
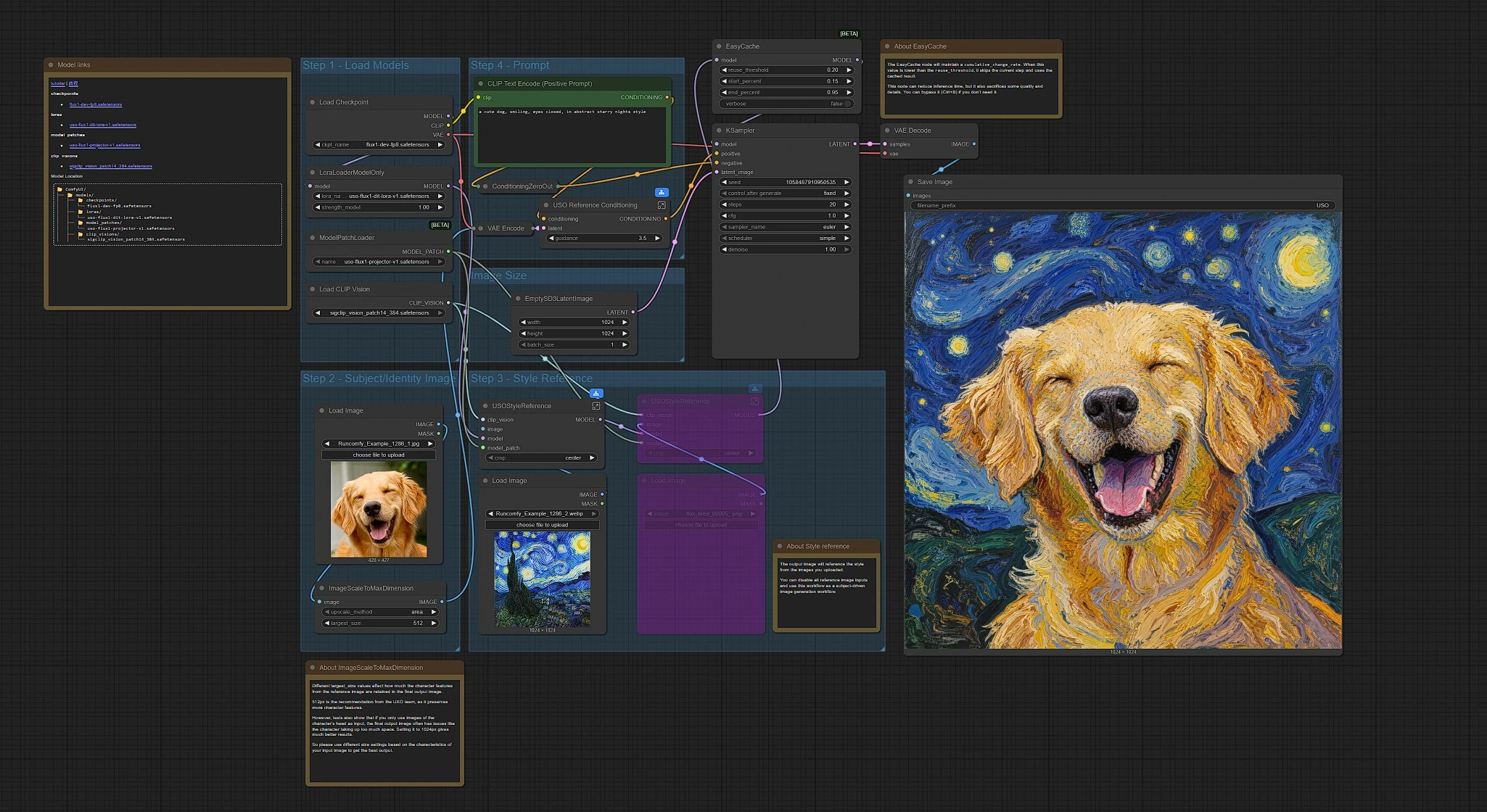




ByteDance USO: Unified Style and Subject Generation Workflow for ComfyUI#
This workflow brings ByteDance USO to ComfyUI for creators who want identity‑faithful characters and precise style transfer in one place. Built on FLUX.1‑dev, it supports subject‑driven, style‑driven, and combined generation so you can place a character into new scenes while keeping likeness, apply styles from reference images, or do both at once.
Use ByteDance USO when you need strong subject coherence with flexible, high‑quality style control. The graph includes two complementary branches: a subject+style path that conditions on an identity image, and a prompt‑driven path that can be used with or without style references. Both paths save images independently so you can compare results quickly.
Key models in Comfyui ByteDance USO workflow#
- FLUX.1‑dev. The base diffusion transformer that powers generation quality and speed. It provides the sampling backbone used by ByteDance USO in this workflow. Model card
- ByteDance USO DiT LoRA v1. A low‑rank adapter that injects Unified Style and Subject capabilities into FLUX.1‑dev, enabling identity preservation and style guidance in a unified setup. Files are provided in the USO 1.0 repack. Repository
- USO FLUX.1 Projector v1. A projector patch that connects CLIP‑Vision features to the generation backbone so style and subject cues can steer the model effectively. Included with the USO repack. Repository
- SigCLIP Vision (patch14, 384). The vision encoder that extracts embeddings from your style and subject reference images, used by the USO modules for visual guidance. Repository
How to use Comfyui ByteDance USO workflow#
The graph has two branches that can run independently. The upper branch uses an identity image plus style references; the lower branch is prompt‑driven and can optionally include style references. Generate from either branch or both.
Step 1 – Load Models#
This step initializes FLUX.1‑dev, the ByteDance USO LoRA, the USO projector, and the SigCLIP vision encoder. It prepares the base model for unified style and subject guidance. Both branches load the same set so you can run subject+style or prompt workflows without reconfiguring models. Once loaded, the model stream is ready for USO’s reference processors.
Step 2 – Subject/Identity Image#
Provide a clean identity image of your character. The workflow scales it to a suitable working size and encodes it into a latent that preserves key facial or character features. This latent is fused with your prompt so ByteDance USO can place the subject into new scenes while keeping identity. Omit this step if you want style‑only or text‑only generation.
Step 3 – Style Reference#
Add one or two style images to guide palette, materials, and brushwork. Each image is encoded with the vision model and applied through USO’s style reference nodes, which layer style influences onto the loaded model. Order matters when using two references, because the second ref is applied after the first. You can bypass this group to run a pure subject‑driven or text‑only pass.
Prompt#
Write an intent‑driven prompt for composition, mood, and details. In the subject+style branch, your prompt is combined with the identity latent and USO’s guidance so text, subject, and style pull in the same direction. In the prompt‑driven branch, the text alone (optionally with style references) steers the image. Keep prompts specific; avoid contradicting the chosen style.
Image Size#
Pick the target resolution for generation. The chosen size influences composition tightness and detail density, especially for portraits vs full‑body shots. If VRAM is limited, start smaller and scale up later. Both branches expose a simple image‑size node so you can tailor aspect and fidelity to your use case.
Sampling and Output#
Each branch samples with a standard sampler, decodes to RGB, and saves to its own output. You will typically get two images per run: one styled subject result and one prompt‑driven result. Iterate by adjusting the prompt or swapping references; resample to explore alternatives or fix the seed for repeatability.
Key nodes in Comfyui ByteDance USO workflow#
USOStyleReference (#56)#
Applies a style image to the current model stream using the USO projector and CLIP‑Vision features. Use one reference for a strong, coherent look or chain two for nuanced blends; the second reference refines the first. If the style dominates too much, try a single, cleaner reference or simplify its content.
ReferenceLatent (#44)#
Injects the encoded subject latent into the conditioning path so ByteDance USO preserves identity. Works best with uncluttered identity photos that clearly show the character’s face or defining features. If identity slips, feed a more complete reference or reduce conflicting style cues.
FluxKontextMultiReferenceLatentMethod (#41)#
Combines multiple reference signals within the FLUX context pathway. This is where subject and prompt context are balanced before sampling. If results feel over‑constrained, relax references; if they drift, strengthen subject imagery or simplify the prompt.
FluxGuidance (#35)#
Controls the strength of text guidance relative to reference signals. Lower values let subject/style lead; higher values enforce the prompt more strongly. Adjust when you see either prompt underfitting (raise guidance) or style/subject being overridden (lower guidance).
ImageScaleToMaxDimension (#109)#
Prepares the identity image for stable feature extraction. Smaller max sizes favor broader composition; larger sizes help when the reference is a tight portrait and you need crisper identity cues. Tune based on whether your subject ref is full‑body or a headshot.
EasyCache (#95)#
Speeds up inference by reusing intermediate states when changes are minor. Great for prompt tweaks and rapid iteration, but it can slightly reduce micro‑details. Disable it for final, highest‑quality renders.
KSampler (#31)#
Runs the diffusion steps and controls stochasticity via seed and sampler choice. Increase steps for more detail, or lock the seed to reproduce a look while changing references. If textures look noisy, try a different sampler or fewer steps with stronger style guidance.
Optional extras#
- For ByteDance USO identity work, prefer neutral, evenly lit subject images; avoid heavy makeup or extreme angles that can conflict with style cues.
- When stacking two style references, place the broader aesthetic first and the texture/detail ref second to refine without overpowering identity.
- Keep negative prompting minimal; the graph intentionally uses a neutral negative path so USO’s learned priors and references align cleanly.
- Iterate fast at lower resolution or with caching on, then switch caching off and upscale your favorite seeds for finals.
- Use reproducible seeds when comparing subject‑only, style‑only, and combined modes to understand how ByteDance USO balances each signal.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge ByteDance for the USO model and the ComfyUI team for the ByteDance USO ComfyUI Native Workflow tutorial for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- ByteDance/USO
- GitHub: bytedance/USO
- Hugging Face: bytedance-research/USO
- arXiv: 2508.18966
- Docs / Release Notes: ByteDance USO Documentation
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.
