





Modelli Z-Image Ottimizzati: generazione di immagini multi-stile e di alta qualità in ComfyUI#
Questo workflow assembla Z-Image-Turbo e un set rotativo di modelli Z-Image ottimizzati in un singolo grafico ComfyUI pronto per la produzione. È progettato per confrontare gli stili fianco a fianco, mantenere il comportamento del prompt coerente e produrre risultati nitidi e coerenti con pochi passaggi. Sotto il cofano combina il caricamento UNet ottimizzato, la normalizzazione CFG, il campionamento compatibile con AuraFlow e l'iniezione opzionale di LoRA in modo da poter esplorare realismo, ritratti cinematografici, dark fantasy e look ispirati all'anime senza dover ricollegare la tua tela.
I modelli Z-Image Ottimizzati sono ideali per artisti, ingegneri di prompt ed esploratori di modelli che vogliono un modo rapido per valutare più checkpoint e LoRA rimanendo all'interno di una pipeline coerente. Inserisci un prompt, genera quattro variazioni da diversi ottimizzazioni Z-Image e blocca rapidamente lo stile che meglio corrisponde al tuo brief.
Modelli chiave nel workflow Comfyui Z-Image Ottimizzati#
- Tongyi-MAI Z-Image-Turbo. Un trasformatore di diffusione a parametro singolo da 6B distillato per testo-immagine fotorealistico con forte aderenza alle istruzioni e rendering di testo bilingue. I pesi ufficiali e le note d'uso sono sulla scheda del modello, con il report tecnico e i metodi di distillazione dettagliati su arXiv e nel repository del progetto. Model • Paper • Decoupled-DMD • DMDR • GitHub • Diffusers pipeline
- BEYOND REALITY Z-Image (community finetune). Un checkpoint Z-Image orientato al fotorealismo che enfatizza texture lucide, bordi nitidi e finiture stilizzate, adatto per ritratti e composizioni simili a prodotti. Model
- Z-Image-Turbo-Realism LoRA (esempio di LoRA usato nel percorso LoRA di questo workflow). Un adattatore leggero che spinge il rendering ultra-realistico preservando l'allineamento del prompt base Z-Image-Turbo; caricabile senza sostituire il tuo modello base. Model
- Famiglia AuraFlow (riferimento compatibile con il campionamento). Il workflow utilizza ganci di campionamento in stile AuraFlow per generazioni stabili a pochi passaggi; vedere il riferimento della pipeline per informazioni di base sui scheduler AuraFlow e i loro obiettivi di progettazione. Docs
Come utilizzare il workflow Comfyui Z-Image Finetuned Models#
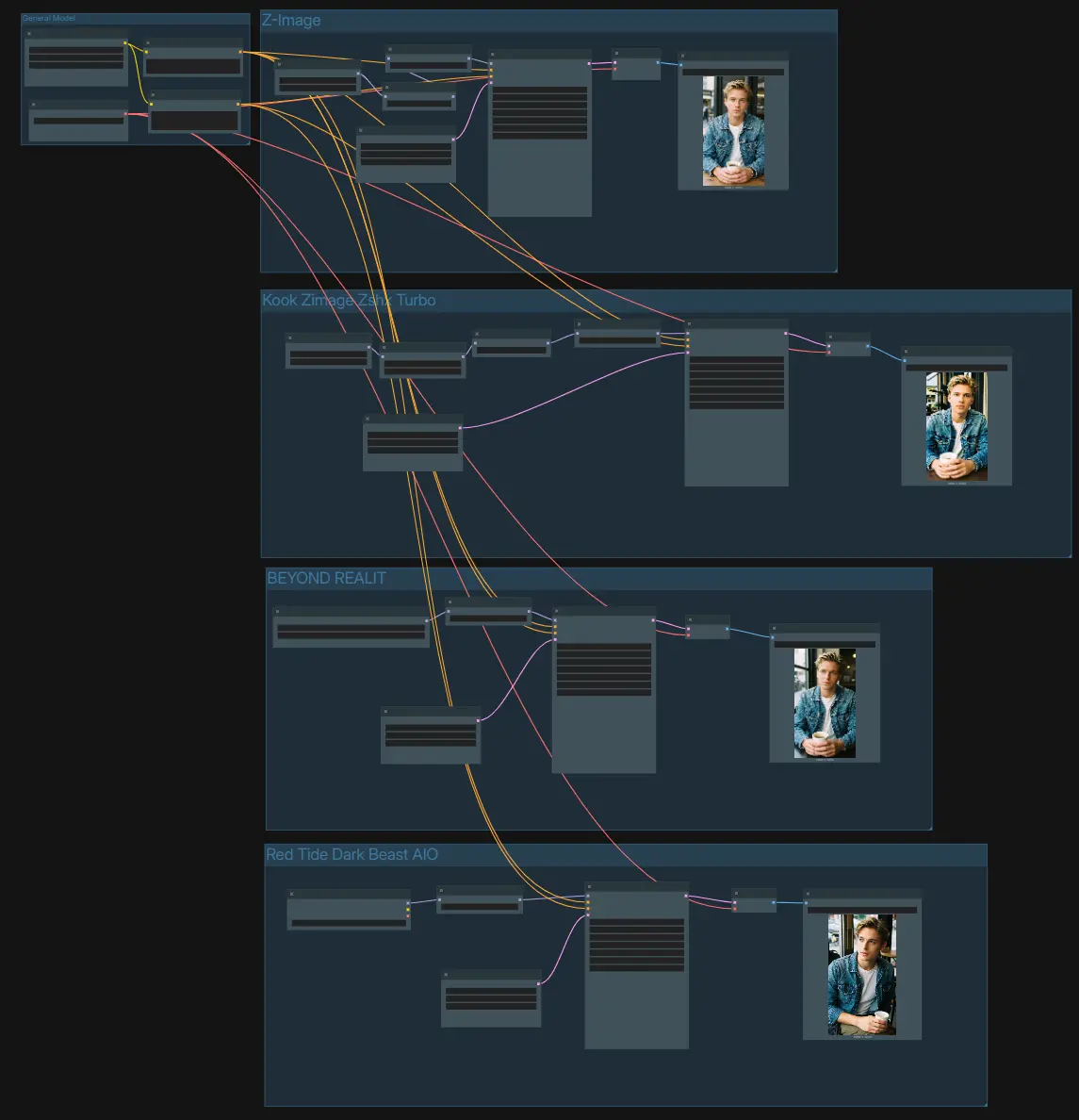
Il grafico è organizzato in quattro percorsi di generazione indipendenti che condividono un encoder di testo comune e un VAE. Usa un prompt per guidare tutti i percorsi, quindi confronta i risultati salvati da ciascun ramo.
- Modello Generale
- L'impostazione condivisa carica l'encoder di testo e il VAE. Inserisci la tua descrizione nel
CLIPTextEncodepositivo (#75) e aggiungi vincoli opzionali alCLIPTextEncodenegativo (#74). Questo mantiene il condizionamento identico tra i rami in modo da poter giudicare equamente come si comporta ciascuna ottimizzazione. IlVAELoader(#21) fornisce il decoder utilizzato da tutti i percorsi per trasformare i latenti in immagini.
- L'impostazione condivisa carica l'encoder di testo e il VAE. Inserisci la tua descrizione nel
- Z-Image (Base Turbo)
- Questo percorso esegue l'UNet ufficiale Z-Image-Turbo tramite
UNETLoader(#100) e lo corregge conModelSamplingAuraFlow(#76) per stabilità a pochi passaggi.CFGNorm(#67) standardizza il comportamento della guida senza classificatore in modo che il contrasto e il dettaglio del campionatore rimangano prevedibili nei prompt. UnEmptyLatentImage(#19) definisce la dimensione della tela, quindiKSampler(#78) genera latenti che vengono decodificati daVAEDecode(#79) e scritti daSaveImage(#102). Usa questo ramo come base quando valuti altri modelli Z-Image Ottimizzati.
- Questo percorso esegue l'UNet ufficiale Z-Image-Turbo tramite
- Z-Image-Turbo + Realism LoRA
- Questo percorso inietta un adattatore di stile con
LoraLoaderModelOnly(#106) sopra ilUNETLoaderbase (#82).ModelSamplingAuraFlow(#84) eCFGNorm(#64) mantengono gli output nitidi mentre il LoRA spinge il realismo senza sopraffare il soggetto. Definisci la risoluzione conEmptyLatentImage(#71), genera conKSampler(#85), decodifica tramiteVAEDecode(#86) e salva usandoSaveImage(#103). Se un LoRA sembra troppo forte, riduci il suo peso qui piuttosto che modificare eccessivamente il tuo prompt.
- Questo percorso inietta un adattatore di stile con
- BEYOND REALITY ottimizzazione
- Questo percorso scambia un checkpoint comunitario con
UNETLoader(#88) per offrire un look stilizzato e ad alto contrasto.CFGNorm(#66) doma la guida in modo che la firma visiva rimanga pulita quando cambi campionatori o passaggi. Imposta la tua dimensione target inEmptyLatentImage(#72), rendi conKSampler(#89), decodificaVAEDecode(#90) e salva tramiteSaveImage(#104). Usa lo stesso prompt del percorso base per vedere come questa ottimizzazione interpreta la composizione e l'illuminazione.
- Questo percorso scambia un checkpoint comunitario con
- Red Tide Dark Beast AIO ottimizzazione
- Un checkpoint orientato al dark-fantasy viene caricato con
CheckpointLoaderSimple(#92), quindi normalizzato daCFGNorm(#65). Questo percorso si inclina verso palette di colori cupe e micro-contrasto più pesante mantenendo una buona conformità al prompt. Scegli il tuo frame inEmptyLatentImage(#73), genera conKSampler(#93), decodifica conVAEDecode(#94) ed esporta daSaveImage(#105). È un modo pratico per testare estetiche più grintose all'interno dello stesso setup di modelli Z-Image Ottimizzati.
- Un checkpoint orientato al dark-fantasy viene caricato con
Nodi chiave nel workflow Comfyui Z-Image Finetuned Models#
ModelSamplingAuraFlow(#76, #84)- Scopo: corregge il modello per utilizzare un percorso di campionamento compatibile con AuraFlow che è stabile a conteggi di passaggi molto bassi. Il controllo
shiftregola sottilmente le traiettorie di campionamento; trattalo come una manopola di finezza che interagisce con la tua scelta di campionatore e il budget di passaggi. Per la migliore comparabilità tra i percorsi, mantieni lo stesso campionatore e modifica solo una variabile (ad es.,shifto peso LoRA) per test. Riferimento: background della pipeline AuraFlow e note di pianificazione. Docs
- Scopo: corregge il modello per utilizzare un percorso di campionamento compatibile con AuraFlow che è stabile a conteggi di passaggi molto bassi. Il controllo
CFGNorm(#64, #65, #66, #67)- Scopo: normalizza la guida senza classificatore in modo che contrasto e dettaglio non oscillino selvaggiamente quando cambi modelli, passaggi o scheduler. Aumenta la sua
strengthse i punti salienti si lavano via o le texture sembrano incoerenti tra i percorsi; riducila se le immagini iniziano a sembrare eccessivamente compresse. Mantienila simile tra i rami quando vuoi un confronto pulito A/B dei modelli Z-Image Ottimizzati.
- Scopo: normalizza la guida senza classificatore in modo che contrasto e dettaglio non oscillino selvaggiamente quando cambi modelli, passaggi o scheduler. Aumenta la sua
LoraLoaderModelOnly(#106)- Scopo: inietta un adattatore LoRA direttamente nell'UNet caricato senza alterare il checkpoint base. Il parametro
strengthcontrolla l'impatto stilistico; valori più bassi preservano il realismo di base mentre valori più alti impongono l'aspetto del LoRA. Se un LoRA domina i volti o la tipografia, riduci prima il suo peso, poi affina la formulazione del prompt.
- Scopo: inietta un adattatore LoRA direttamente nell'UNet caricato senza alterare il checkpoint base. Il parametro
KSampler(#78, #85, #89, #93)- Scopo: esegue il ciclo di diffusione effettivo. Scegli un campionatore e uno scheduler che si abbinano bene con distillazioni a pochi passaggi; molti utenti preferiscono campionatori in stile Euler con scheduler uniformi o multistep per modelli di classe Turbo. Mantieni i semi fissi quando confronti i percorsi e cambia solo una variabile alla volta per capire come si comporta ciascuna ottimizzazione.
Extra opzionali#
- Inizia con un prompt descrittivo in stile paragrafo e riutilizzalo in tutti i percorsi per giudicare le differenze tra i modelli Z-Image Ottimizzati; itera le parole di stile solo dopo aver scelto un ramo preferito.
- Per i modelli di classe Turbo, CFG molto basso o anche zero spesso produce i risultati più puliti; usa il prompt negativo solo quando devi escludere elementi specifici.
- Mantieni la stessa risoluzione, campionatore e seme durante i test A/B; cambia il peso LoRA o
shiftin piccoli incrementi per isolare causa ed effetto. - Ogni ramo scrive la propria uscita; i quattro nodi
SaveImagesono etichettati in modo univoco in modo da poter confrontare e curare rapidamente.
Link per ulteriori letture:
- Scheda del modello Z-Image-Turbo: Tongyi-MAI/Z-Image-Turbo
- Report tecnico e metodi: Z-Image • Decoupled-DMD • DMDR
- Repository del progetto: Tongyi-MAI/Z-Image
- Esempio di ottimizzazione: Nurburgring/BEYOND_REALITY_Z_IMAGE
- Esempio di LoRA: Z-Image-Turbo-Realism-LoRA
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo calorosamente i modelli HuggingFace per l'articolo per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Modelli HuggingFace:
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.



