
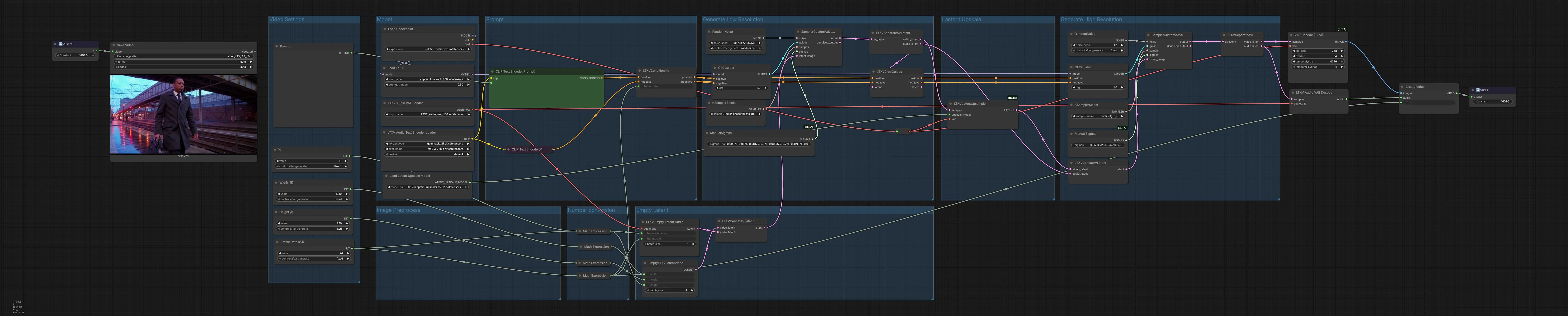
LTX 2.3 Sulphur 2 flusso di lavoro da testo a video per animazione cinematografica di personaggi#
Questa pipeline ComfyUI trasforma i prompt in linguaggio naturale in video brevi, cinematografici, focalizzati sui personaggi con audio opzionale, costruiti attorno ai componenti Lightricks LTX‑2.3 e Sulphur 2. Stabilisci la generazione a bassa risoluzione per la pianificazione del movimento, aumenta la sequenza latente, quindi affina ad alta risoluzione prima di decodificare in fotogrammi e muxare una traccia audio sincronizzata.
Il flusso di lavoro da testo a video LTX 2.3 Sulphur 2 è ideale per rapidi test di animazione di personaggi, concetti di movimento stile D‑Human e esperimenti di testo‑a‑video raffinati. Non si basa su input immagine‑a‑video o trasmissioni di prompt; tutto inizia dal testo, con il condizionamento LTXV che guida i latenti video e audio da un capo all'altro.
Modelli chiave nel flusso di lavoro Comfyui LTX 2.3 Sulphur 2 da testo a video#
- Lightricks LTX‑2.3. Generatore core testo‑a‑video utilizzato per la sintesi spaziotemporale e latenti AV multimodali. Vedi il repository ufficiale del modello per pesi e note su capacità e limitazioni. Hugging Face: Lightricks/LTX-2.3
- Lightricks LTX‑2.3 FP8 checkpoint. Variante a memoria efficiente di LTX‑2.3 che accelera l'inferenza e consente clip più lunghe o risoluzioni più elevate su GPU limitate. Hugging Face: Lightricks/LTX-2.3-fp8
- Modello base Sulphur 2. Fornisce priorità di stile e dettagli del personaggio tramite LoRA in questo flusso di lavoro, aiutando a ottenere volti nitidi e tonalità cinematografiche. Hugging Face: SulphurAI/Sulphur-2-base
- LTX‑2.3 Spatial Upscaler x2 1.1. Upscaler nello spazio latente che aumenta i dettagli spaziali prima del passaggio di affinamento ad alta risoluzione. Hugging Face: Lightricks/LTX-2.3 file ltx-2.3-spatial-upscaler-x2-1.1.safetensors
- Codificatore di testo LTX (Gemma 3 12B IT confezionato per LTX). Fornisce lo spazio di embedding del testo abbinato al condizionamento LTX‑2.3 per un seguito fedele del prompt. Hugging Face: Comfy-Org/ltx-2
- LTX Audio VAE. Decodifica il latente audio generato insieme al video in modo che il render finale possa includere una colonna sonora sincronizzata. Hugging Face: Lightricks/LTX-2.3
Come usare il flusso di lavoro Comfyui LTX 2.3 Sulphur 2 da testo a video#
Logica generale La pipeline si svolge in tre atti: generazione a bassa risoluzione per stabilire movimento e composizione, upscaling latente per aumentare i dettagli spaziali, e un passaggio di affinamento ad alta risoluzione che produce anche l'audio finale. I latenti vengono decodificati in fotogrammi e forma d'onda, quindi muxati in un contenitore MP4 pronto per la consegna.
Impostazioni video Usa il gruppo “Impostazioni Video” per definire larghezza, altezza, frame rate e durata. Il conteggio dei fotogrammi viene calcolato automaticamente dalla tua durata e fps in modo che il timing e la cadenza rimangano coerenti. Questi valori guidano l'allocazione e la decodifica latente, quindi impostali prima per abbinare il rapporto d'aspetto e il tempo di esecuzione target. Regolare fps qui informa anche il condizionamento in modo che la fluidità del movimento e l'allineamento audio utilizzino lo stesso orologio.
Prompt Nel “Prompt,” carica il codificatore di testo LTX con LTXAVTextEncoderLoader (#316), quindi scrivi la tua descrizione positiva in CLIPTextEncode (#303) e qualsiasi tratto indesiderato in CLIPTextEncode (#312). Il nodo LTXVConditioning (#304) unisce il condizionamento positivo e negativo e aggiunge il frame rate scelto in modo che la guida temporale corrisponda al tuo fps. Tratta il prompt positivo come un brief di ripresa: soggetto, fotocamera, illuminazione, atmosfera e indicazioni stilistiche. Mantieni la lista negativa focalizzata sugli artefatti che vedi regolarmente e vuoi rimuovere.
Modello Il gruppo “Modello” carica il checkpoint principale tramite CheckpointLoaderSimple (#315) e applica un Sulphur 2 LoRA con LoraLoaderModelOnly (#285) per infondere texture cinematografiche e fedeltà del personaggio. Qui puoi scambiare checkpoint o LoRA per cambiare l'aspetto generale e le priorità del movimento. L'output del modello è indirizzato sia ai guidatori iniziali che di affinamento in modo che stile e identità siano coerenti tra i passaggi. L'abbinamento di LTX‑2.3 con Sulphur 2 produce contrasti vivaci e volti dettagliati che si leggono bene in movimento.
Conversione numerica Espressioni di utilità convertono il tuo fps e secondi nel conteggio dei fotogrammi intero utilizzato a valle. Questo mantiene le timeline audio e video allineate senza calcoli manuali. Se modifichi fps o durata in seguito, il grafico aggiorna automaticamente i nodi dipendenti.
Latente Vuoto “Latente Vuoto” crea contenitori allineati per la generazione: EmptyLTXVLatentVideo (#295) definisce la dimensione spaziale e la lunghezza del video latente, LTXVEmptyLatentAudio (#305) assegna il latente audio allo stesso frame rate, e LTXVConcatAVLatent (#321) li unisce in un unico latente AV. Partire da latenti vuoti assicura che il passaggio di diffusione rifletta completamente il tuo prompt e il condizionamento piuttosto che qualsiasi contenuto preesistente.
Generazione a Bassa Risoluzione La prima fase di campionamento stabilisce movimento e composizione a costo inferiore. CFGGuider (#313), KSamplerSelect (#291), e ManualSigmas (#306) governano quanto fortemente il prompt guida la generazione e la pianificazione del rumore complessiva. SamplerCustomAdvanced (#283) quindi denoizza il latente AV in un clip coerente. Il risultato viene diviso da LTXVSeparateAVLatent (#307), e LTXVCropGuides (#284) affina l'attenzione spaziale in modo che l'inquadratura del soggetto desiderata venga preservata durante il successivo upscaling.
Lantent Upscale LTXVLatentUpsampler (#287) utilizza l'upscaler x2 LTX‑2.3 per sollevare i dettagli spaziali rimanendo nello spazio latente per velocità e stabilità. Alimentare il video latente upscalato avanti migliora la trama e la leggibilità prima dell'affinamento ad alta risoluzione. Questo preserva il movimento che ti è piaciuto dal primo passaggio mentre apre spazio per bordi più nitidi e materiali più ricchi.
Generazione ad Alta Risoluzione Il video latente upscalato viene riunito con il latente audio in LTXVConcatAVLatent (#278) e guidato di nuovo per la qualità finale. CFGGuider (#282), KSamplerSelect (#280), e ManualSigmas (#281) danno l'ultima parola sulla forza del prompt, i dettagli, e la coerenza temporale, con SamplerCustomAdvanced (#308) che produce il latente AV raffinato. LTXVSeparateAVLatent (#309) consegna il video a VAEDecodeTiled (#314) per la decodifica dei fotogrammi compatibile con la memoria e l'audio a LTXVAudioVAEDecode (#297) per la ricostruzione della forma d'onda. CreateVideo (#310) muxa i fotogrammi e l'audio al tuo fps target, e SaveVideo (#75) scrive un file MP4/H.264.
Preprocessamento Immagine Quest'area instrada i modelli base VAE e upscaler in modo che il tiling e l'upscaling latente funzionino entro il tuo budget VRAM. Se si verifica pressione di memoria, preferisci i pesi FP8 LTX‑2.3 e mantieni la decodifica tiling abilitata per mantenere throughput e qualità.
Nodi chiave nel flusso di lavoro Comfyui LTX 2.3 Sulphur 2 da testo a video#
LTXVConditioning (#304) Unisce il condizionamento positivo e negativo del testo e attacca il frame rate di lavoro in modo che la guida temporale corrisponda al tuo render. Un linguaggio di scena forte e specifico migliora la struttura del colpo; negativi concisi riducono gli artefatti. Vedi la scheda modello LTX‑2.3 per note sul condizionamento. Hugging Face: Lightricks/LTX-2.3
LTXVCropGuides (#284) Guida dolcemente la composizione per mantenere il soggetto principale inquadrato come previsto. Usalo per proteggere la dimensione del volto, il posizionamento dell'orizzonte o un soggetto centrato prima dell'upscaling e dell'affinamento. È particolarmente utile per scatti in stile dialogo e primi piani medi.
CFGGuider (#313, #282) Controlla quanto aggressivamente il prompt influenza la traiettoria di diffusione in entrambi i passaggi. Usa la prima guida per bloccare movimento e messa in scena, quindi la seconda per aggiungere nitidezza senza allontanarsi dallo scatto stabilito.
ManualSigmas (#306, #281) Definisce la pianificazione del rumore. Caricare più rumore incoraggia una maggiore esplorazione del movimento; una pianificazione più dolce enfatizza la coerenza temporale. Mantieni le pianificazioni a bassa risoluzione e ad alta risoluzione complementari piuttosto che identiche.
LTXVLatentUpsampler (#287) Esegue l'upscaling latente x2 utilizzando l'upscaler LTX ufficiale in modo da guadagnare dettagli prima del campionatore di affinamento. Cambiare a un'altra variante di upscaler LTX‑2.3 può cambiare leggermente nitidezza e grana. Hugging Face: Lightricks/LTX-2.3
VAEDecodeTiled (#314) Decodifica clip lunghe o grandi in tile gestibili per evitare picchi di VRAM. Se cambi dimensione spaziale o lunghezza del clip, regola il tiling per bilanciare spazio di memoria e velocità di decodifica.
LoraLoaderModelOnly (#285) Applica il Sulphur 2 LoRA al percorso del modello base in modo che la fedeltà del personaggio e le indicazioni stilistiche si trasferiscano in entrambe le fasi di campionamento. Usa questo per cambiare rapidamente l'aspetto mantenendo la stessa base LTX‑2.3. Hugging Face: SulphurAI/Sulphur-2-base
Extra opzionali#
- Controllo dei semi: imposta valori fissi in entrambi i nodi
RandomNoisein modo che i take siano riproducibili; cambia un seme per esplorare alternative. - Prompting: scrivi i prompt come direzioni di scatto (soggetto, fotocamera, illuminazione, atmosfera). Mantieni la lista negativa focalizzata e breve.
- Performance: se la VRAM è limitata, preferisci i pesi FP8 LTX‑2.3 e mantieni la decodifica tiling abilitata.
- Output: il grafico scrive MP4/H.264; cambia contenitore o codec in
SaveVideose hai bisogno di flussi di lavoro proxy ProRes.
Questo flusso di lavoro LTX 2.3 Sulphur 2 da testo a video offre un percorso pulito, da un capo all'altro, dal prompt al video raffinato con audio sincronizzato, costruito per iterazioni rapide su animazioni di personaggi cinematografiche.
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine RunningHub per il flusso di lavoro di base Sulphur2 per la produzione video, SulphurAI per il modello Sulphur-2-base, Lightricks per i modelli LTX-2.3 e LTX-2.3-fp8, e Comfy-Org per il codificatore di testo LTX-2 per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- RunningHub/Sulphur2 Basic Workflow for Video Production
- Documenti / Note di rilascio: Sulphur2 Basic Workflow for Video Production
- SulphurAI/Sulphur-2-base
- Hugging Face: SulphurAI/Sulphur-2-base
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Lightricks/LTX-2.3-fp8
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-fp8
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.