
Gemma 4 Text Generation ComfyUI workflow: testo multimodale con contesto immagine, video e audio#
Questo workflow Gemma 4 Text Generation ComfyUI è un modello compatto, pronto per RunComfy, che genera testo di alta qualità comprendendo immagini e audio, con un esempio video incluso. È progettato per iterazioni rapide su prompt multimodali, riassunto di recensioni di prodotti, analisi dei contenuti e prototipi di assistenti leggeri all'interno di ComfyUI.
Il grafo utilizza i nativi TextGenerate e CLIPLoader di ComfyUI per eseguire Gemma 4 E4B con input opzionali di immagini, audio e video. Puoi mantenerlo semplice per la generazione di testo puro o allegare media per guidare il ragionamento del modello e produrre output più ricchi.
Modelli chiave nel workflow Comfyui Gemma 4 Text Generation ComfyUI#
- Modello multimodale istruttivo Gemma 4 E4B. Fornisce generazione di testo con comprensione visiva e audio per risposte concise, riassunti e analisi. Gli asset del modello per ComfyUI sono organizzati nel pacchetto comunitario Comfy-Org/gemma-4.
- Codificatore di testo Gemma 4 E4B (FP8 scalato). Il workflow carica i pesi del codificatore confezionati
gemma4_e4b_it_fp8_scaled.safetensorsche supportano gli input linguistici e multimodali del nodoTextGenerate. Link diretto al file per utenti locali: `text_encoders/gemma4_e4b_it_fp8_scaled.safetensors`.
Come usare il workflow Comfyui Gemma 4 Text Generation ComfyUI#
Logica generale: il workflow carica il codificatore Gemma 4, accetta media opzionali, quindi utilizza TextGenerate per produrre una risposta che viene resa in un'anteprima. Puoi eseguirlo solo come testo, collegare un'immagine e audio, o estenderlo al video collegando il gruppo di esempio.
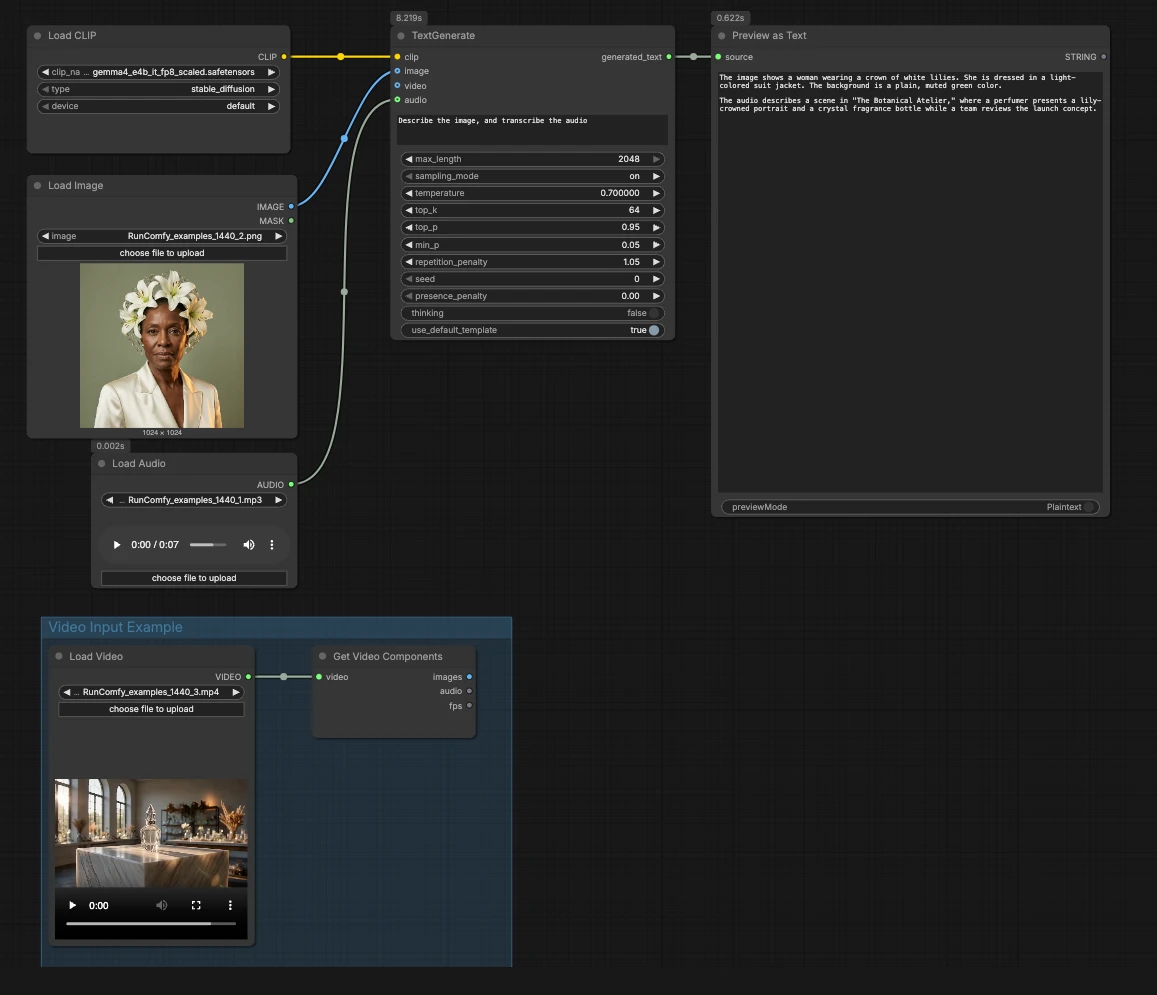
CLIPLoader(#3) Carica il codificatore di testo Gemma 4 E4B richiesto dal generatore. Quando viene eseguito localmente, selezionagemma4_e4b_it_fp8_scaled.safetensorsin modo che il modello linguistico abbia il tokenizzatore corretto e il codificatore multimodale. Negli ambienti gestiti il file corretto è tipicamente preselezionato. Non è necessario regolare nulla qui una volta che i pesi scelti sono visibili.- Input immagine con
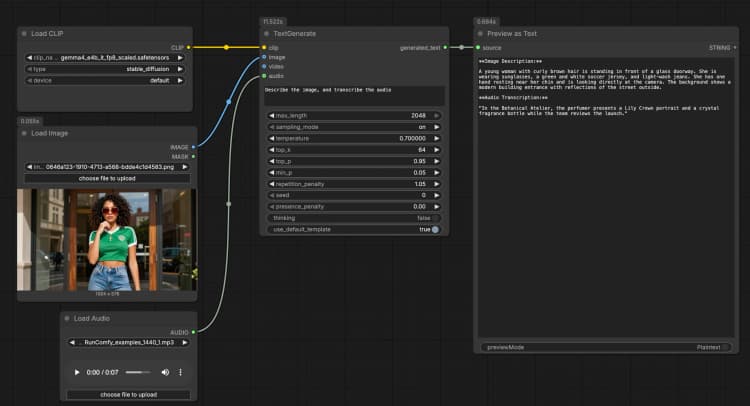
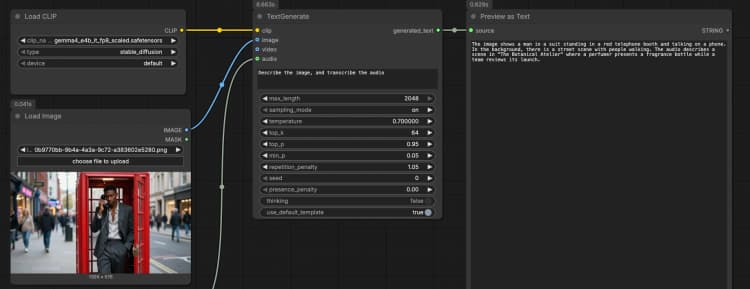
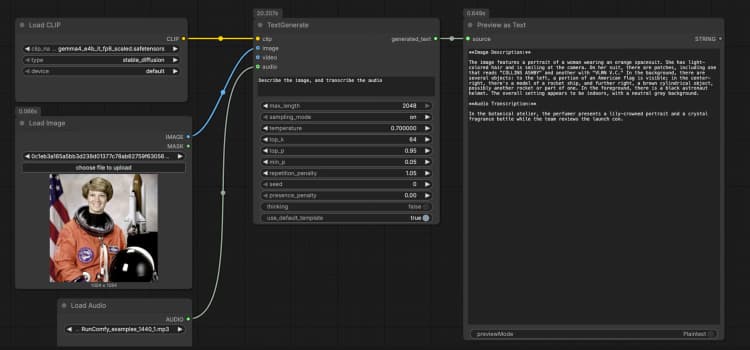
LoadImage(#2) Fornisce un'immagine di riferimento singola che il modello può descrivere, OCR o analizzare come parte del prompt. Sostituisci il file di esempio con il tuo screenshot, grafico, documento o foto del prodotto. L'immagine viene passata direttamente aTextGenerate, che condiziona la risposta sul contenuto visivo. Se vuoi un comportamento solo testuale, lascia questo nodo disconnesso. - Input audio con
LoadAudio(#5) Aggiunge una clip audio per trascrizione o ragionamento consapevole dell'audio. Sostituisci il file di esempio con una nota vocale, un estratto di riunione o una registrazione di recensione. Il flusso audio viene alimentato aTextGeneratein modo da poter chiedere al modello di trascrivere o riassumerlo insieme all'immagine. Per compiti solo testuali, lascia questo input vuoto. - Gruppo di esempio input video Il gruppo "Gruppo di Esempio Input Video" mostra come portare il video nello stesso flusso utilizzando
LoadVideo(#6) eGetVideoComponents(#7).GetVideoComponentsespone fotogrammi rappresentativi e la colonna sonora in modo da poter analizzare scene, diapositive o testo sullo schermo. Per abilitare la comprensione del video, collega l'outputimagesall'inputimagediTextGeneratee l'outputaudioal suo inputaudio. Questo consente al workflow Gemma 4 Text Generation ComfyUI di ragionare su entrambi i fotogrammi e il parlato da un clip. - Generazione testo con
TextGenerate(#1) Questo è il nodo principale che accetta la tua istruzione più qualsiasi media allegato e restituisce il testo generato. Fornisci un prompt chiaro come "Descrivi l'immagine e trascrivi l'audio, quindi scrivi un riassunto di 2 frasi." Il nodo fonde automaticamente contesto visivo e audio, quindi scrivi istruzioni naturali senza segnaposto. Puoi mantenere i prompt conversazionali o orientati ai compiti a seconda del tuo caso d'uso. - Visualizzazione risultato con
PreviewAny(#4) Mostra il testo generato in modo da poterlo copiare nei tuoi appunti o strumenti a valle. Rerun dopo aver modificato il prompt o aver cambiato i media per confrontare rapidamente gli output. Usa questa anteprima per convalidare quanto ogni modalità influenza la risposta.
Nodi chiave nel workflow Comfyui Gemma 4 Text Generation ComfyUI#
TextGenerate(#1) Guida l'output finale e dove si trova la maggior parte della regolazione. Regola la lunghezza della risposta e quanto deve essere esplorativa cambiando i token massimi e la temperatura di campionamento. Abilita la modalità di ragionamento opzionale se vuoi un pensiero più passo-passo prima della risposta. Per dettagli sull'implementazione, vedi il codice sorgente del nodo di generazione testo ComfyUI qui.CLIPLoader(#3) Seleziona e carica il pacchetto di codificatori Gemma 4 E4B necessario per la comprensione testuale e multimodale. Se mantieni i modelli localmente, posiziona il file sotto: ComfyUI/models/text_encoders/gemma4_e4b_it_fp8_scaled.safetensors Dopo la selezione, raramente è necessario rivedere questo nodo a meno che non si cambi variante del modello.GetVideoComponents(#7) Utile quando vuoi che il modello consideri il video. Esponi fotogrammi e audio in modo da poter condizionareTextGeneratesu entrambi. Se il tuo clip è lungo, scegli un set più piccolo di fotogrammi per una risposta più veloce; se hai bisogno di dettagli più fini, aumenta il campionamento dei fotogrammi a scapito della velocità.
Extra opzionali#
- Inizia con istruzioni esplicite come "Considera l'immagine e l'audio allegati" per rendere evidente il radicamento multimodale.
- Per recensioni di prodotti, chiedi pro, contro e un verdetto in una frase per mantenere gli output strutturati.
- Se il tuo compito è puramente testuale, disconnetti immagine e audio per esecuzioni più rapide.
- Per esperimenti in batch, duplica il nodo
TextGeneratecon prompt diversi e confronta le anteprime fianco a fianco. - I file e le varianti del modello per Gemma 4 sono organizzati nel pacchetto comunitario; esplora gli asset disponibili qui: Comfy-Org/gemma-4.
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine Comfy-Org per il pacchetto modello Gemma 4 ComfyUI e il codificatore di testo E4B, Comfy-Org (mantenitori di ComfyUI) per il nodo TextGenerate integrato, e Comfy.org per il tutorial ufficiale di Gemma 4 e il blog di rilascio per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- ComfyUI Docs/Esempio di workflow Gemma 4 ComfyUI
- GitHub: Comfy-Org/ComfyUI
- Hugging Face: Comfy-Org/gemma-4
- Docs / Note di Rilascio: Esempio di workflow Gemma 4 ComfyUI
- ComfyUI Blog/Nuovi Modelli Open-Source Ora in ComfyUI: VOID, BiRefNet & Gemma 4
- GitHub: Comfy-Org/workflow_templates
- Hugging Face: Comfy-Org/gemma-4
- Docs / Note di Rilascio: Nuovi Modelli Open-Source Ora in ComfyUI: VOID, BiRefNet & Gemma 4
- Comfy-Org/gemma-4
- Hugging Face: Comfy-Org/gemma-4
- Comfy-Org/gemma-4 E4B text encoder
- Hugging Face: Comfy-Org/gemma-4: gemma4_e4b_it_fp8_scaled.safetensors
- Comfy-Org/ComfyUI TextGenerate node
Nota: L'uso dei modelli, dataset e codice di cui sopra è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.