
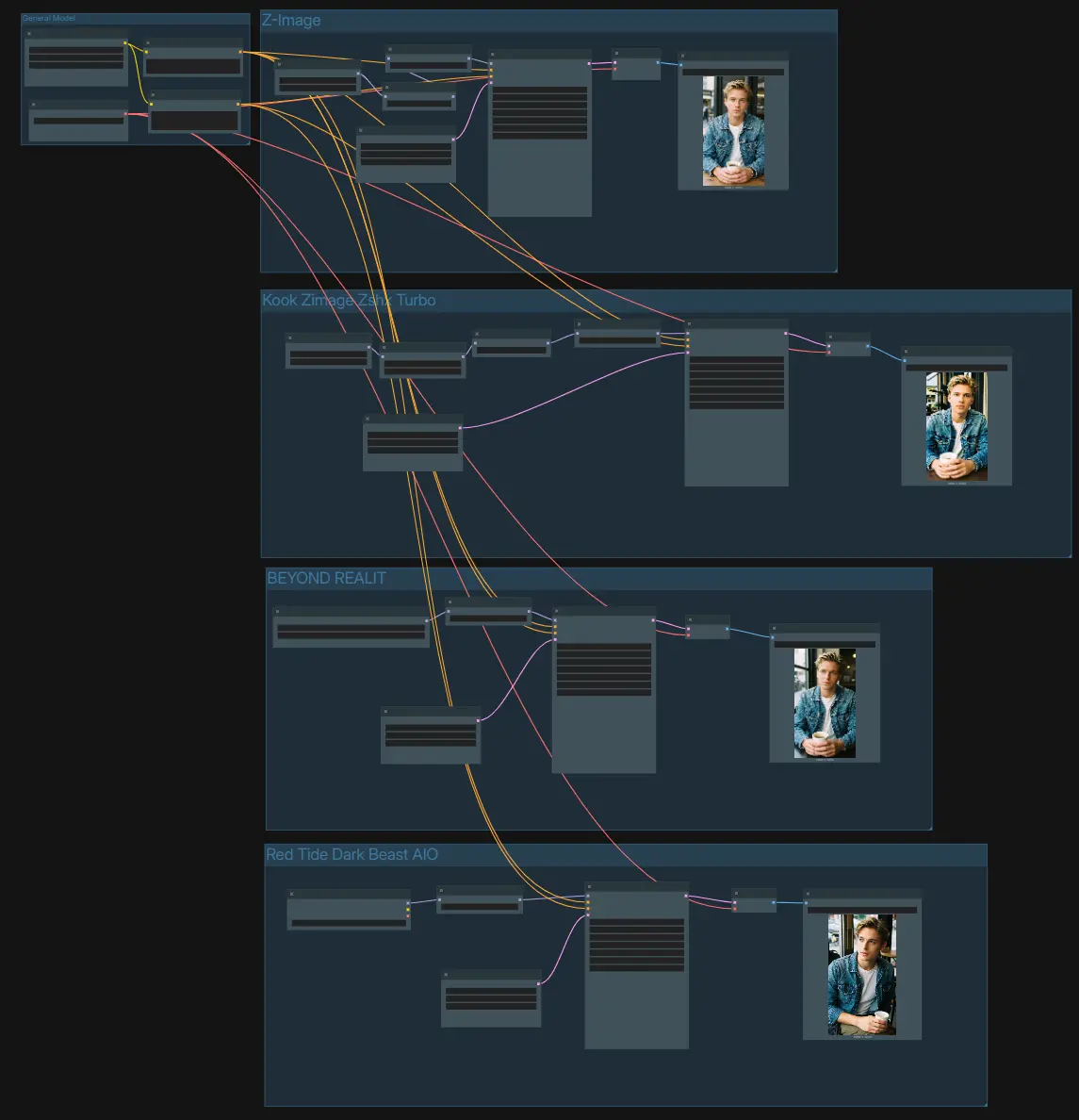





Modèles Z-Image Finetuned : génération d'images multi-style et haute qualité dans ComfyUI#
Ce flux de travail assemble Z-Image-Turbo et un ensemble rotatif de modèles Z-Image finetuned en un seul graphique ComfyUI prêt pour la production. Il est conçu pour comparer les styles côte à côte, maintenir un comportement de prompt cohérent, et produire des résultats nets et cohérents avec un minimum d'étapes. Sous le capot, il combine le chargement optimisé d'UNet, la normalisation CFG, l'échantillonnage compatible AuraFlow, et l'injection LoRA optionnelle pour explorer le réalisme, le portrait cinématographique, le dark fantasy et les looks inspirés de l'anime sans reconfigurer votre canevas.
Les modèles Z-Image Finetuned sont idéaux pour les artistes, les ingénieurs de prompt et les explorateurs de modèles qui souhaitent une méthode rapide pour évaluer plusieurs points de contrôle et LoRAs tout en restant dans un pipeline cohérent. Entrez un prompt, rendez quatre variations à partir de différents finetunes Z-Image, et verrouillez rapidement le style qui correspond le mieux à votre briefing.
Modèles clés dans le flux de travail Comfyui Z-Image Finetuned Models#
- Tongyi-MAI Z-Image-Turbo. Un transformateur de diffusion à flux unique de 6 milliards de paramètres distillé pour une conversion texte-image photoréaliste en quelques étapes avec une forte adhérence aux instructions et un rendu textuel bilingue. Les poids officiels et les notes d'utilisation sont sur la carte du modèle, avec le rapport technique et les méthodes de distillation détaillées sur arXiv et dans le dépôt du projet. Model • Paper • Decoupled-DMD • DMDR • GitHub • Diffusers pipeline
- BEYOND REALITY Z-Image (community finetune). Un point de contrôle Z-Image à tendance photoréaliste qui met l'accent sur des textures brillantes, des bords nets et une finition stylisée, adapté aux portraits et aux compositions de type produit. Model
- Z-Image-Turbo-Realism LoRA (exemple de LoRA utilisé dans la voie LoRA de ce flux de travail). Un adaptateur léger qui pousse le rendu ultra-réaliste tout en préservant l'alignement des prompts de base Z-Image-Turbo ; chargeable sans remplacer votre modèle de base. Model
- Famille AuraFlow (référence compatible avec l'échantillonnage). Le flux de travail utilise des crochets d'échantillonnage de style AuraFlow pour des générations stables en quelques étapes ; voir la référence de pipeline pour le contexte sur les planificateurs AuraFlow et leurs objectifs de conception. Docs
Comment utiliser le flux de travail Comfyui Z-Image Finetuned Models#
Le graphique est organisé en quatre voies de génération indépendantes qui partagent un encodeur de texte commun et un VAE. Utilisez un prompt pour piloter toutes les voies, puis comparez les résultats enregistrés de chaque branche.
- Modèle Général
- La configuration partagée charge l'encodeur de texte et le VAE. Entrez votre description dans le
CLIPTextEncodepositif (#75) et ajoutez des contraintes optionnelles auCLIPTextEncodenégatif (#74). Cela garde le conditionnement identique entre les branches afin que vous puissiez juger équitablement comment chaque finetune se comporte. LeVAELoader(#21) fournit le décodeur utilisé par toutes les voies pour transformer les latents en images.
- La configuration partagée charge l'encodeur de texte et le VAE. Entrez votre description dans le
- Z-Image (Base Turbo)
- Cette voie exécute l'UNet officiel Z-Image-Turbo via
UNETLoader(#100) et le corrige avecModelSamplingAuraFlow(#76) pour une stabilité en quelques étapes.CFGNorm(#67) standardise le comportement de la guidance sans classificateur afin que le contraste et le détail du sampler restent prévisibles à travers les prompts. UnEmptyLatentImage(#19) définit la taille du canevas, puisKSampler(#78) génère des latents qui sont décodés parVAEDecode(#79) et écrits parSaveImage(#102). Utilisez cette branche comme votre référence lors de l'évaluation d'autres modèles Z-Image Finetuned.
- Cette voie exécute l'UNet officiel Z-Image-Turbo via
- Z-Image-Turbo + Realism LoRA
- Cette voie injecte un adaptateur de style avec
LoraLoaderModelOnly(#106) au-dessus duUNETLoaderde base (#82).ModelSamplingAuraFlow(#84) etCFGNorm(#64) maintiennent des sorties nettes tandis que la LoRA pousse le réalisme sans submerger le sujet. Définissez la résolution avecEmptyLatentImage(#71), générez avecKSampler(#85), décodez viaVAEDecode(#86), et sauvegardez en utilisantSaveImage(#103). Si une LoRA semble trop forte, réduisez son poids ici plutôt que de sur-éditer votre prompt.
- Cette voie injecte un adaptateur de style avec
- BEYOND REALITY finetune
- Ce chemin échange un point de contrôle communautaire avec
UNETLoader(#88) pour offrir un look stylisé et à fort contraste.CFGNorm(#66) apprivoise la guidance afin que la signature visuelle reste propre lorsque vous changez de samplers ou d'étapes. Définissez votre taille cible dansEmptyLatentImage(#72), rendez avecKSampler(#89), décodezVAEDecode(#90), et sauvegardez viaSaveImage(#104). Utilisez le même prompt que la voie de base pour voir comment ce finetune interprète la composition et l'éclairage.
- Ce chemin échange un point de contrôle communautaire avec
- Red Tide Dark Beast AIO finetune
- Un point de contrôle orienté dark fantasy est chargé avec
CheckpointLoaderSimple(#92), puis normalisé parCFGNorm(#65). Cette voie s'appuie sur des palettes de couleurs sombres et un micro-contraste plus lourd tout en maintenant une bonne conformité aux prompts. Choisissez votre cadre dansEmptyLatentImage(#73), générez avecKSampler(#93), décodez avecVAEDecode(#94), et exportez depuisSaveImage(#105). C'est une méthode pratique pour tester des esthétiques plus rugueuses dans le même ensemble de modèles Z-Image Finetuned.
- Un point de contrôle orienté dark fantasy est chargé avec
Nœuds clés dans le flux de travail Comfyui Z-Image Finetuned Models#
ModelSamplingAuraFlow(#76, #84)- Objectif : corrige le modèle pour utiliser un chemin d'échantillonnage compatible avec AuraFlow qui est stable à des comptes d'étapes très bas. Le contrôle
shiftajuste subtilement les trajectoires d'échantillonnage ; traitez-le comme un cadran de finesse qui interagit avec votre choix de sampler et votre budget d'étapes. Pour une meilleure comparabilité entre les voies, conservez le même sampler et ajustez une seule variable (par exemple,shiftou poids de LoRA) par test. Référence : contexte du pipeline AuraFlow et notes de planification. Docs
- Objectif : corrige le modèle pour utiliser un chemin d'échantillonnage compatible avec AuraFlow qui est stable à des comptes d'étapes très bas. Le contrôle
CFGNorm(#64, #65, #66, #67)- Objectif : normalise la guidance sans classificateur afin que le contraste et le détail ne varient pas de manière excessive lorsque vous changez de modèles, d'étapes ou de planificateurs. Augmentez sa
strengthsi les hautes lumières s'effacent ou si les textures semblent incohérentes entre les voies ; réduisez-la si les images commencent à paraître excessivement compressées. Gardez-la similaire entre les branches lorsque vous souhaitez un A/B propre des modèles Z-Image Finetuned.
- Objectif : normalise la guidance sans classificateur afin que le contraste et le détail ne varient pas de manière excessive lorsque vous changez de modèles, d'étapes ou de planificateurs. Augmentez sa
LoraLoaderModelOnly(#106)- Objectif : injecte un adaptateur LoRA directement dans l'UNet chargé sans altérer le point de contrôle de base. Le paramètre
strengthcontrôle l'impact stylistique ; des valeurs plus basses préservent le réalisme de base tandis que des valeurs plus élevées imposent le look de la LoRA. Si une LoRA surpuissante les visages ou la typographie, réduisez d'abord son poids, puis affinez la formulation du prompt.
- Objectif : injecte un adaptateur LoRA directement dans l'UNet chargé sans altérer le point de contrôle de base. Le paramètre
KSampler(#78, #85, #89, #93)- Objectif : exécute la boucle de diffusion réelle. Choisissez un sampler et un planificateur qui se marient bien avec les distillations en quelques étapes ; de nombreux utilisateurs préfèrent les samplers de style Euler avec des planificateurs uniformes ou multi-étapes pour les modèles de la classe Turbo. Gardez les graines fixes lors de la comparaison des voies, et changez une seule variable à la fois pour comprendre comment chaque finetune se comporte.
Extras optionnels#
- Commencez avec un prompt descriptif de style paragraphe et réutilisez-le à travers toutes les voies pour juger des différences entre les modèles Z-Image Finetuned ; itérez les mots de style uniquement après avoir choisi une branche préférée.
- Pour les modèles de classe Turbo, un CFG très bas ou même nul donne souvent les résultats les plus propres ; utilisez le prompt négatif uniquement lorsque vous devez exclure des éléments spécifiques.
- Maintenez la même résolution, le même sampler et la même graine lors des tests A/B ; changez le poids de la LoRA ou le
shiftpar petits incréments pour isoler cause et effet. - Chaque branche écrit sa propre sortie ; les quatre nœuds
SaveImagesont étiquetés de manière unique pour que vous puissiez comparer et organiser rapidement.
Liens pour lecture complémentaire :
- Carte du modèle Z-Image-Turbo : Tongyi-MAI/Z-Image-Turbo
- Rapport technique et méthodes : Z-Image • Decoupled-DMD • DMDR
- Dépôt de projet : Tongyi-MAI/Z-Image
- Exemple de finetune : Nurburgring/BEYOND_REALITY_Z_IMAGE
- Exemple de LoRA : Z-Image-Turbo-Realism-LoRA
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement les modèles HuggingFace pour l'article pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Modèles HuggingFace:
Note : L'utilisation des modèles, jeux de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.


