
LTX 2.3 IC-LoRA : Génération de vidéo guidée par le mouvement dans ComfyUI#
Ce workflow apporte le système LTX 2.3 IC-LoRA à ComfyUI pour que vous puissiez guider le mouvement et la structure de la scène tout en stylisant librement avec des invites ou des LoRAs supplémentaires. Il conditionne le générateur vidéo LTX-2.3 sur des signaux de référence tels que la profondeur, la pose et les contours, permettant le transfert de mouvement, le verrouillage de la caméra et une composition prévisible.
Les créateurs travaillant sur la vidéo-à-vidéo, le retargeting de mouvement et l'animation AI contrôlée trouveront que LTX 2.3 IC-LoRA sépare le contrôle du mouvement du style visuel. Vous dirigez l'apparence avec des textes et des LoRAs de style, et dirigez le mouvement avec des guides structurés, le tout à l'intérieur d'un seul graphe ComfyUI.
Modèles clés dans le workflow Comfyui LTX 2.3 IC-LoRA#
- LTX-2.3 par Lightricks. Un transformateur de diffusion vidéo latente haute fidélité qui génère des séquences temporellement cohérentes et prend en charge le conditionnement pour le contrôle de la structure et du mouvement. Hugging Face: Lightricks/LTX-2.3
- Poids de contrôle en union LTX 2.3 IC-LoRA. Poids LoRA en contexte conçus pour injecter des signaux de guidage structurés dans LTX-2.3 pour un contrôle précis du mouvement et de la géométrie. Fourni avec la chaîne de modèles du workflow et chargé avant la génération.
- LTX-2.3 VAEs pour la vidéo et l'audio. Encodeurs/décodeurs latents associés à LTX-2.3 pour compresser et reconstruire les caractéristiques vidéo et audio utilisées pendant l'échantillonnage. Préconfiguré dans le graphe et commutable lors de l'utilisation de builds quantifiés. Des exemples de packages séparés sont disponibles ici : Hugging Face: unsloth/LTX-2.3-GGUF
- Depth Anything V2. Estimation robuste de profondeur monoculaire utilisée pour verrouiller le mouvement de la caméra ou préserver la disposition de la scène pendant la génération. Hugging Face: LiheYoung/Depth-Anything-V2
- DWPose. Estimateur de pose multi-personnes léger utilisé pour retargeter ou préserver le mouvement des personnages via des points clés. Hugging Face: yzd-v/DWPose
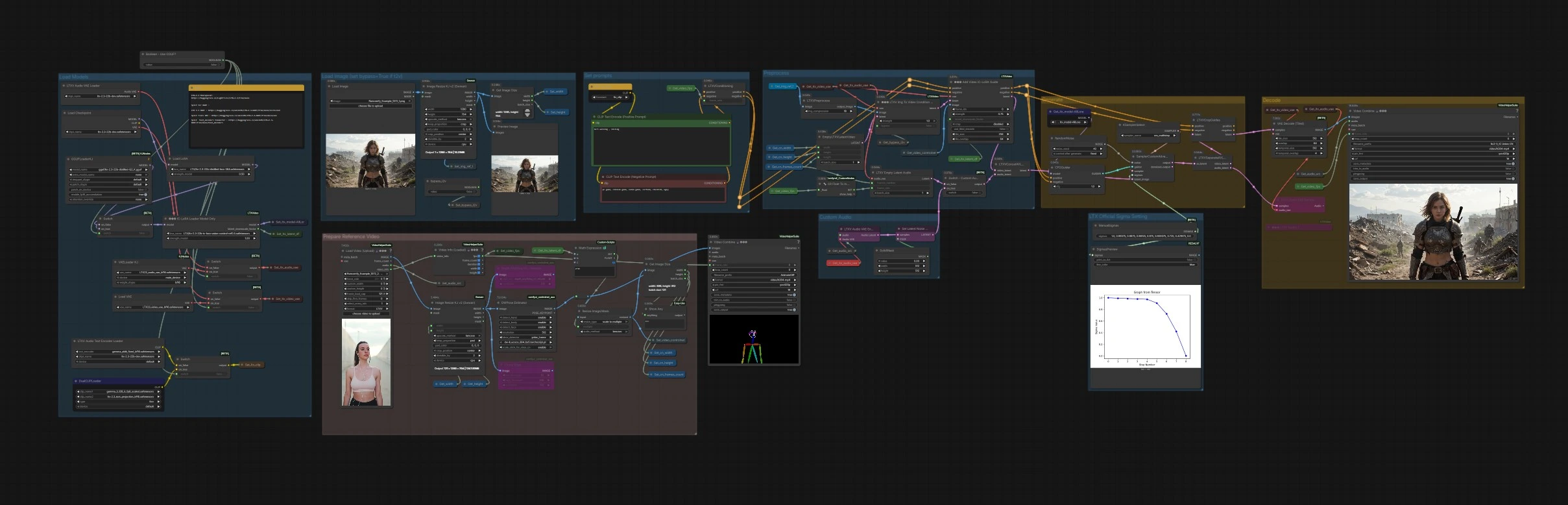
Comment utiliser le workflow Comfyui LTX 2.3 IC-LoRA#
Le graphe est organisé en groupes clairs. Vous préparez des invites et une vidéo de référence, choisissez un ou plusieurs guides structurels, puis générez et exportez.
Définir les invites#
Utilisez CLIP Text Encode (Positive Prompt) (#2483) et CLIP Text Encode (Negative Prompt) (#2612) pour décrire le style visuel et exclure les traits indésirables. Les encodeurs de texte sont chargés dans le groupe de modèles et envoyés à LTXVConditioning (#1241), qui reçoit également la fréquence d'images de travail pour que le conditionnement corresponde à votre chronométrage de clip. Gardez les invites concentrées sur l'apparence car LTX 2.3 IC-LoRA s'occupera du mouvement et de la structure.
Prétraiter#
Chargez ou passez un clip de référence dans VHS_LoadVideo (#5182). Les cadres sont redimensionnés dans ImageResizeKJv2 (#5080) et alimentés dans les extracteurs de guides : DepthAnythingV2Preprocessor (#5064) pour la profondeur, DWPreprocessor (#4986) pour la pose, et CannyEdgePreprocessor (#4991) pour les contours. Un nœud de redimensionnement en aval assure que les cartes de guidage correspondent aux multiples adaptés au modèle, et GetImageSize (#5029) enregistre la largeur, la hauteur et le nombre de cadres pour le reste du pipeline. La séquence d'images de guidage résultante est stockée par Set_video_controlnet (#5100) pour être consommée par IC-LoRA.
Charger les Modèles#
Le modèle de base et les LoRAs sont assemblés dans ce groupe. CheckpointLoaderSimple (#3940) charge LTX-2.3; LoraLoaderModelOnly (#4922) applique un LoRA LTX distillé pour la qualité et la vitesse; LTXICLoRALoaderModelOnly (#5011) ajoute les poids LTX 2.3 IC-LoRA et publie le facteur d'échelle descendant latent requis. Les VAEs pour la vidéo et l'audio sont chargés, et Boolean - Use GGUF? (#5158) peut passer à un build GGUF quantifié via GGUFLoaderKJ (#5150) avec des encodeurs de texte et VAEs compatibles lorsque la VRAM est limitée.
Charger l'Image (définir bypass=True si t2v)#
Si vous souhaitez ancrer la composition avec une référence fixe ou le premier cadre, utilisez LoadImage (#2004). Il est redimensionné par ImageResizeKJv2 (#5076) et prévisualisé pour des vérifications rapides. Le booléen bypass_i2v contrôle si l'image est utilisée; définissez-le sur True pour un pur texte-à-vidéo avec LTX 2.3 IC-LoRA.
Générer#
EmptyLTXVLatentVideo (#3059) crée la toile latente. Si l'ancrage d'image est activé, LTXVImgToVideoConditionOnly (#3159) injecte uniquement des informations structurelles de votre image sans intégrer le style. L'étape principale se déroule dans LTXAddVideoICLoRAGuide (#5012), qui attache votre séquence de guide choisie au modèle en utilisant le facteur d'échelle descendant latent du chargeur IC-LoRA. Le conditionnement audio s'écoule également dans le latent via LTXVEmptyLatentAudio (#3980) ou le chemin audio personnalisé. CFGGuider (#4828), KSamplerSelect (#4831), ManualSigmas (#5025), et SamplerCustomAdvanced (#4829) effectuent ensuite le débruitage pour synthétiser la vidéo latente finale tout en respectant à la fois les invites et les contrôles LTX 2.3 IC-LoRA.
Décoder#
LTXVSeparateAVLatent (#4845) divise les latents audio et vidéo générés pour le décodage. LTXVCropGuides (#5013) aligne et recadre si nécessaire, puis VAEDecodeTiled (#4851) reconstruit les cadres efficacement. VHS_VideoCombine (#5070) multiplexe les cadres dans un MP4, utilisant par défaut l'audio du clip de référence. Vous pouvez également décoder le latent audio généré avec LTXVAudioVAEDecode (#4848) si vous souhaitez l'auditionner séparément.
Préparer la Vidéo de Référence#
Cette zone d'assistance montre le pipeline de cadres de référence. VHS_VideoInfoLoaded (#5073) extrait les fps et la durée, qui sont propagés aux nœuds de conditionnement et aux exportateurs pour que le timing reste synchronisé. Un petit nœud de combinaison fournit un aperçu visuel rapide de la séquence source pour des vérifications de cohérence.
Audio Personnalisé#
Si vous souhaitez une génération consciente de l'audio, l'audio de référence est encodé avec LTXVAudioVAEEncode (#5146) et un masque simple est appliqué dans SetLatentNoiseMask (#5148). Le commutateur intitulé Switch - Custom Audio? (#5149) sélectionne entre des latents audio vides ou encodés avant la concaténation dans LTXVConcatAVLatent (#4528). L'exportation finale utilise toujours par défaut l'audio de référence; si vous préférez l'audio décodé du modèle, dirigez la sortie LTXVAudioVAEDecode vers l'entrée audio de l'exportateur.
Réglage Sigma Officiel LTX#
Le nœud de programme ManualSigmas (#5025) définit un profil sigma concis ajusté pour LTX-2.3, et SigmasPreview (#5142) le visualise pour que vous puissiez raisonner sur l'allocation du bruit au fil du temps. Cela vous permet d'échanger la vitesse contre le détail tout en maintenant la stabilité temporelle caractéristique de LTX 2.3 IC-LoRA.
Nœuds clés dans le workflow Comfyui LTX 2.3 IC-LoRA#
LTXICLoRALoaderModelOnly(#5011). Charge les poids LTX 2.3 IC-LoRA et produit le facteur d'échelle descendant latent requis par l'injecteur de guide. Si vous ajoutez des LoRAs de style supplémentaires, placez-les avant ce chargeur pour garder le guidage du mouvement dominant.LTXAddVideoICLoRAGuide(#5012). Le point où les séquences de profondeur, de pose ou de contour entrent dans le modèle en tant que guidage en contexte. Ajustez sa force pour équilibrer entre l'adhérence structurelle stricte et la liberté stylistique de votre invite et des LoRAs de style.LTXVImgToVideoConditionOnly(#3159). Fournit un conditionnement image-à-vidéo optionnel qui transfère uniquement la composition et la structure grossière d'une image fixe. Utilisez son basculementbypasslors du passage entre i2v et le pur texte-à-vidéo.CFGGuider(#4828). Contrôle la force avec laquelle le modèle suit vos invites par rapport au guide LTX 2.3 IC-LoRA. Augmentez le guidage lorsque la fidélité au style est primordiale, diminuez-le pour préserver le mouvement et la géométrie avec un minimum de dérive.SamplerCustomAdvanced(#4829) avecManualSigmas(#5025). Un programme compact et un échantillonneur multistep qui offre une bonne cohérence temporelle pour LTX-2.3. Si vous modifiez le programme, gardez-le en décroissance progressive et testez des clips courts avant des rendus plus longs.
Extras optionnels#
- Choisissez le bon guide. Utilisez la profondeur pour verrouiller la caméra et la disposition, la pose pour le mouvement des personnages, et les contours pour les objets rigides ou les silhouettes nettes. Mélanger deux guides est possible s'ils décrivent des aspects différents.
- Gardez les dimensions adaptées à l'échantillonneur. Les préprocesseurs arrondissent déjà les tailles aux multiples adaptés au modèle; gardez votre source proche du ratio d'aspect cible pour minimiser le rembourrage.
- Style sans casser le mouvement. Ajoutez un LoRA de style léger avant le chargeur IC-LoRA et gardez son poids modéré pour que LTX 2.3 IC-LoRA puisse maintenir la géométrie et le timing.
- Mode faible VRAM. Activez Use GGUF pour exécuter le modèle distillé quantifié et les encodeurs de texte/VAEs correspondants du package GGUF si votre GPU est contraint. Hugging Face: unsloth/LTX-2.3-GGUF
- Timing stable. La fréquence d'images lue à partir de la vidéo de référence est injectée dans le conditionnement et les exportateurs pour que le mouvement et l'audio restent alignés. Si vous remplacez les fps, faites-le de manière cohérente à travers le conditionnement et l'exportation.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement @Benji’s AI Playground de LTX 2.3 IC-LoRA Source pour avoir fourni des matériaux et des conseils de source. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- LTX 2.3 IC-LoRA Source
- Docs / Notes de version : YouTube @Benji’s AI Playground
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.

