
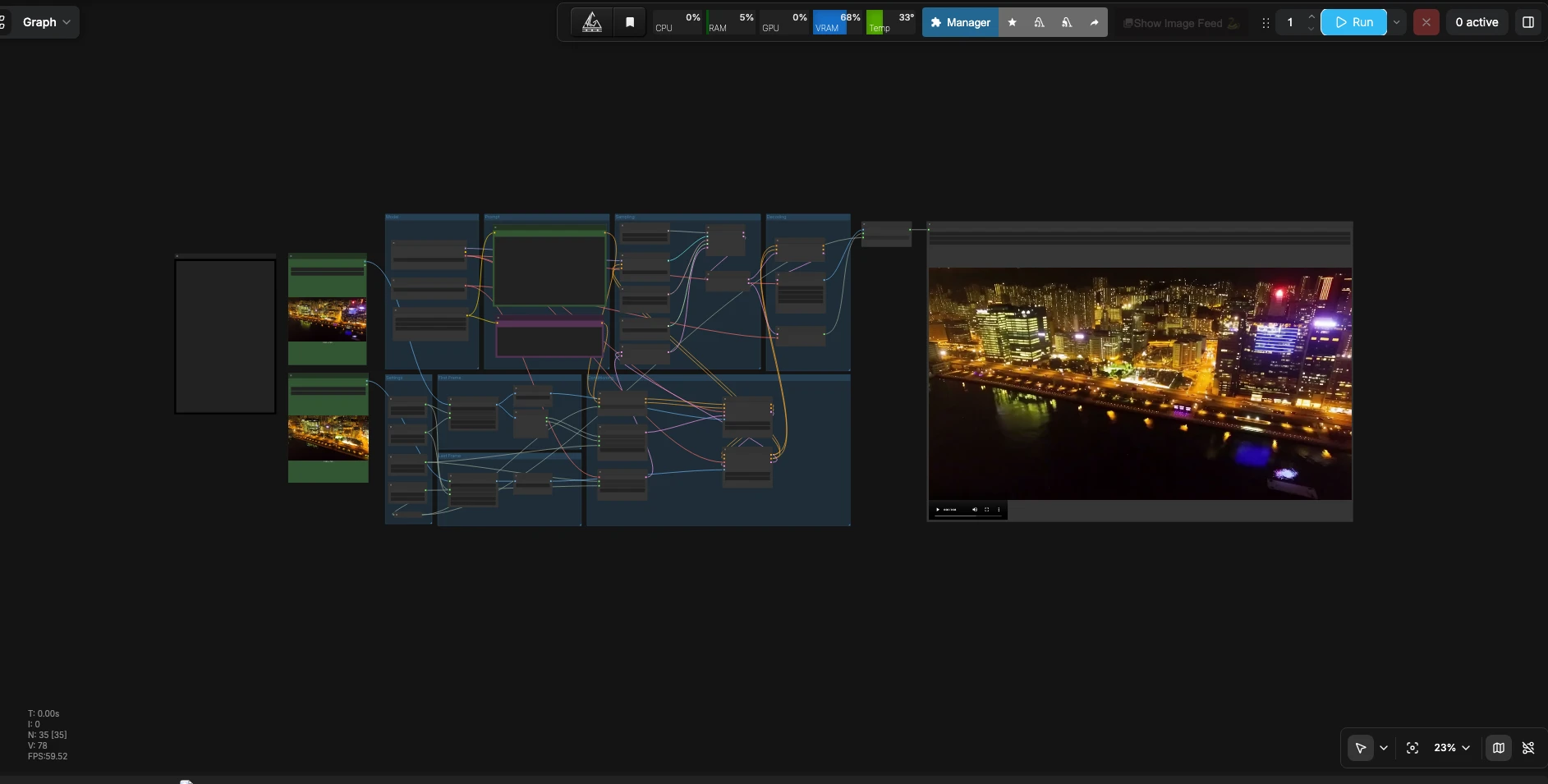
LTX 2.3 First Last Frame to Video#
LTX 2.3 First Last Frame to Video est un flux de travail ComfyUI qui transforme deux images fixes en une vidéo continue et fluide avec audio synchronisé. Vous fournissez une première image, une dernière image et une invite en langage naturel décrivant le mouvement, les détails de la scène et le son. Propulsé par le point de contrôle LTX-2.3 22B distilled FP8, le pipeline interpole entre les images tout en maintenant une apparence et un timing cohérents. Il est idéal pour les éditeurs, les designers de mouvement et les artistes de storyboard qui ont besoin d'une transition fluide ou d'un court clip en boucle créé directement dans ComfyUI.
Ce flux de travail LTX 2.3 First Last Frame met l'accent sur une inférence efficace et une haute fidélité des invites. Les poids FP8 gardent l'utilisation de la VRAM sous contrôle, tandis qu'un encodeur de texte Gemma 3 12B améliore la compréhension sémantique des instructions visuelles et audio. Le résultat est un passage visuel cohérent de la première à la dernière image qui respecte votre invite et reste synchronisé avec l'audio généré.
Modèles clés dans le flux de travail Comfyui LTX 2.3 First Last Frame#
- LTX-2.3 22B Distilled FP8 checkpoint par Lightricks. Modèle de génération vidéo principal distillé pour une inférence efficace, utilisé ici pour synthétiser des images temporellement cohérentes tout en se basant sur les deux guides d'image et l'invite de texte. Model card
- Gemma 3 12B IT text encoder. Fournit une compréhension linguistique robuste pour les aspects visuels et audio de l'invite, permettant des mouvements précis, des attributs de scène et des indices de bande sonore. Model card
- LTX-2.3 latent VAEs pour la vidéo et l'audio. Ces composants mappent les images et l'audio sous forme d'onde vers des latents compacts et inversement lors du décodage, préservant la qualité tout en gardant l'échantillonnage efficace. Livré avec la version LTX-2.3 FP8. Model card
Comment utiliser le flux de travail Comfyui LTX 2.3 First Last Frame#
Ce flux de travail prend deux images de référence et une invite, construit un conditionnement avec des guides de première et dernière image, échantillonne un latent vidéo avec audio synchronisé, et décode le tout en un fichier lisible.
Paramètres
- Définissez votre résolution cible, le nombre d'images et la fréquence d'images dans le groupe Paramètres. La largeur et la hauteur définissent la toile de travail ; les images d'entrée sont redimensionnées pour correspondre afin que le modèle puisse interpoler proprement. Le nombre d'images contrôle la durée de la transition, et la fréquence d'images définit la vitesse de lecture. Choisissez un format d'image qui correspond à vos sources pour éviter le recadrage indésirable. Les nœuds
WIDTH(#113),HEIGHT(#98),Length(#102), etFrame Rate(int)(#114) ancrent ces choix.
Première Image
- Chargez votre image de départ dans
Load First Frame(#31). Elle est redimensionnée parResizeImageMaskNode(#124) aux dimensions cibles et normalisée parLTXVPreprocess(#104). Cela prépare la première image à agir comme un guide structurel et coloriel fort au début du clip. Utilisez une image nette et bien éclairée pour de meilleurs résultats.
Dernière Image
- Chargez votre image de fin dans
Load Last Frame(#39). L'image est adaptée à la même taille avecResizeImageMaskNode(#125) et normalisée parLTXVPreprocess(#99). Cela garantit l'apparence finale et la disposition souhaitées à la fin de la transition. Pour les boucles, faites en sorte que la dernière image soit visuellement compatible avec la première.
Invite
- Le
LTXAVTextEncoderLoader(#103) fournit l'encodeur de texte, et deux nœudsCLIPTextEncodecapturent vos invites positives et négatives. Dans l'invite positive (CLIPTextEncode(#128)), décrivez le mouvement de la caméra, les sujets, l'éclairage, et incluez également des indices audio tels que "Musique : pads ambiants avec percussions douces" ou "Dialogue : bref chuchotement". L'invite négative (CLIPTextEncode(#112)) peut énumérer les artefacts ou les traits que vous souhaitez supprimer.
Conditionnement
LTXVConditioning(#109) fusionne le conditionnement textuel avec les informations de timing afin que le mouvement et l'audio s'alignent avec votre fréquence d'images choisie.EmptyLTXVLatentVideo(#108) crée un latent vidéo à votre résolution et longueur. Deux passes deLTXVAddGuideattachent d'abord la première image (LTXVAddGuide(#115)) puis la dernière image (LTXVAddGuide(#111)) pour que le modèle sache où commencer et où finir.LTXVEmptyLatentAudio(#101) initialise un latent audio de durée correspondante, etLTXVConcatAVLatent(#119) regroupe les latents audio et vidéo pour l'échantillonnage.
Modèle
CheckpointLoaderSimple(#127) charge les poids LTX-2.3 22B distilled FP8 et le VAE vidéo, tandis queLTXVAudioVAELoader(#126) fournit le VAE audio. Ceux-ci sont préconfigurés pour que vous puissiez vous concentrer sur les entrées créatives plutôt que sur les détails de configuration.
Échantillonnage
CFGGuider(#116) équilibre l'adhérence à votre texte et aux images guides contre la liberté créative.RandomNoise(#100) définit une graine pour la reproductibilité. L'échantillonneur utiliseSamplerEulerAncestral(#117) avec un programme personnalisé deManualSigmas(#118), orchestré parSamplerCustomAdvanced(#120), pour affiner progressivement le latent en une séquence cohérente qui suit vos instructions de mouvement et d'audio.
Décodage
- Après l'échantillonnage,
LTXVSeparateAVLatent(#121) sépare le latent combiné en vidéo et audio.LTXVCropGuides(#106) affine les guides spatiaux pour réduire les artefacts de bord avant le décodage des images.VAEDecodeTiled(#105) produit la séquence d'images, etLTXVAudioVAEDecode(#107) génère la forme d'onde audio.CreateVideo(#122) multiplexe les images et le son à votre fps sélectionné etSaveVideo(#68) écrit le fichier final dans votre sortie ComfyUI.
Nœuds clés dans le flux de travail Comfyui LTX 2.3 First Last Frame#
EmptyLTXVLatentVideo (#108)
- Définit la résolution de travail et la durée de votre clip. Ajustez la largeur, la hauteur et la longueur ici pour définir l'échelle visuelle et le temps de transition. Les durées plus longues nécessitent des indices de mouvement plus forts dans l'invite pour éviter la stagnation.
LTXVAddGuide (#115)
- Injecte la première image comme ancre structurelle et colorielle au début de la séquence. Si l'ouverture s'éloigne de votre source, augmentez l'influence de ce guide ; si elle semble trop contrainte, réduisez-la légèrement pour permettre plus de mouvement.
LTXVAddGuide (#111)
- Ancre l'apparence cible à la fin du clip en utilisant la dernière image. Si la transition dépasse ou n'atteint jamais tout à fait votre dernière image, augmentez l'influence du guide ; si elle se fixe trop fortement près de la fin, réduisez-la.
CFGGuider (#116)
- Contrôle la force avec laquelle le modèle suit le conditionnement texte et image. Une guidance plus élevée accentue votre invite et vos guides mais peut réduire la fluidité ; des valeurs plus basses se sentent plus libres mais peuvent s'écarter de l'apparence prévue. Ajustez par petites étapes et réutilisez la même graine lors de la comparaison.
SamplerCustomAdvanced (#120) avec SamplerEulerAncestral (#117) et ManualSigmas (#118)
- Conduit le débruitage avec un programme cohérent pour un mouvement stable. Les programmes plus courts rendent plus rapidement mais peuvent être rugueux ; les programmes plus longs ou plus doux améliorent la cohérence à un coût de calcul supplémentaire. Gardez le programme cohérent lors des tests A/B d'autres paramètres.
CreateVideo (#122)
- Multiplexe les images décodées et l'audio en un clip final à votre fréquence d'images choisie. Utilisez le même fps que vous avez conditionné pour que les formes de lèvres, les pas ou les impulsions musicales restent alignés.
Options supplémentaires#
- Écrivez des invites avec des verbes et des timings : "la caméra avance," "les lumières s'éteignent à mesure que nous approchons," "Musique : piano épars avec réverbération douce." Des verbes clairs aident le pipeline LTX 2.3 First Last Frame à inférer mouvement et rythme.
- Correspondre le format d'image et l'orientation de vos deux images. De grands décalages peuvent introduire un recadrage ou un étirement indésirable.
- Pour des boucles sans soudure, faites en sorte que la dernière image soit presque identique à la première et gardez le mouvement de la caméra cyclique.
- Réutilisez une graine dans
RandomNoisepour reproduire un look en itérant sur les invites ou les forces des guides ; changez la graine pour explorer de nouvelles variations. - Si vous avez besoin de détails d'implémentation ou de références de nœuds personnalisés, consultez les intégrations et utilitaires LTX de ComfyUI tels que ComfyUI-LTXTricks. Repository
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Lightricks pour LTX-2.3 22B Distilled FP8 Checkpoint, Google pour Gemma 3 12B IT FP4 Text Encoder, logtd pour ComfyUI-LTXTricks Custom Nodes, et Comfy.org pour Comfy.org Official Workflow pour leurs contributions et maintenance. Pour des détails autoritatifs, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Lightricks/LTX-2.3 22B Distilled FP8 Checkpoint
- Hugging Face: Lightricks/LTX-2.3-fp8
- Google/Gemma 3 12B IT FP4 Text Encoder
- Hugging Face: google/gemma-3-12b-it
- logtd/ComfyUI-LTXTricks Custom Nodes
- GitHub: logtd/ComfyUI-LTXTricks
- Comfy.org/Comfy.org Official Workflow
- Docs / Release Notes: comfy.org/workflows/video_ltx2_3_flf2v
Note : L'utilisation des modèles, des ensembles de données et du code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.
