
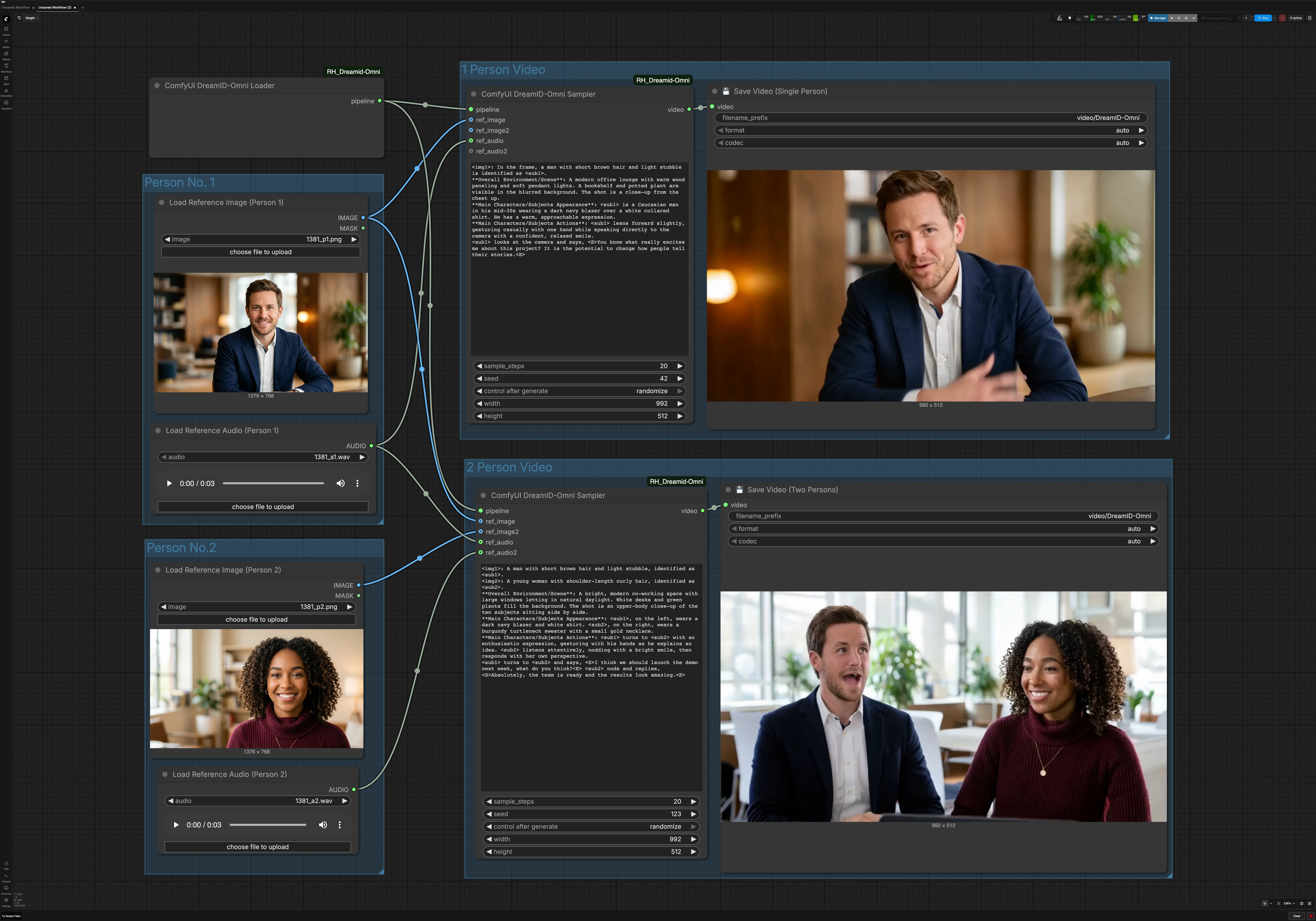
Workflow vidéo parlant de personnage simple et double DreamID-Omni pour ComfyUI#
Ce workflow transforme une photo de référence unique et un clip audio en une vidéo parlante préservant l'identité. Propulsé par le modèle DreamID-Omni, il combine une infrastructure vidéo moderne avec un mouvement labial guidé par MMAudio pour que le sujet parle naturellement tout en conservant le visage de votre image. Il prend également en charge deux personnages, permettant des clips conversationnels côte à côte dirigés par deux voix.
Conçu pour les créateurs, les équipes produit et les chercheurs, le workflow DreamID-Omni dans ComfyUI est idéal pour les avatars numériques, les annonces personnalisées, les introductions de tutoriels et les scènes de dialogue IA. Vous fournissez des photos et des audios, décrivez éventuellement la prise de vue dans une invite courte, et le graphique rend une vidéo soignée prête à être partagée.
Modèles clés dans le workflow DreamID-Omni de ComfyUI#
- DreamID-Omni. Le module d'identité de base qui préserve la personne dans votre image de référence à travers les cadres tout en répondant à l'audio pour des mouvements des lèvres réalistes. Voir le dépôt officiel et les poids pour plus de détails : DreamID-Omni et DreamID-Omni sur Hugging Face.
- Wan 2.2 génération vidéo. Une infrastructure de diffusion vidéo haute capacité qui synthétise le mouvement cohérent, l'éclairage et la composition de la prise de vue tandis que DreamID-Omni dirige l'identité faciale.
- MMAudio. Un modèle de représentation audio qui conditionne les formes de la bouche et les indices faciaux subtils pour s'aligner avec le discours fourni, améliorant le réalisme de la synchronisation labiale.
Comment utiliser le workflow DreamID-Omni de ComfyUI#
Ce graphique a deux chemins parallèles. Le chemin à une personne utilise une image et un audio. Le chemin à deux personnes utilise deux images et deux audios pour produire un clip conversationnel. Un chargeur DreamID-Omni partagé initialise le pipeline pour les deux.
Personne n° 1#
Utilisez Load Reference Image (Person 1) (#6) pour sélectionner un portrait clair, de face avec un éclairage uniforme et une occlusion minimale. Utilisez Load Reference Audio (Person 1) (#7) pour fournir le discours que vous souhaitez que le personnage dise. Un audio plus propre produit une meilleure synchronisation labiale, donc préférez un discours sans musique ni bruit de fond fort. Ce couple alimente à la fois le mode à une personne et, lorsqu'il est activé, le sujet gauche ou premier en mode à deux personnes.
Personne n° 2#
Utilisez Load Reference Image (Person 2) (#9) et Load Reference Audio (Person 2) (#11) lors de la création d'un dialogue. Choisissez une photo qui correspond au cadrage de la Personne 1 pour maintenir la composition équilibrée. Assurez-vous que le second audio est similaire en volume au premier pour éviter des changements perceptuels brusques. Si vous ne faites qu'un clip à une personne, vous pouvez ignorer ce groupe.
Vidéo à 1 Personne#
Le chemin du locuteur unique est dirigé par ComfyUI DreamID-Omni Sampler (#21). Il fusionne le pipeline DreamID-Omni avec la photo et l'audio de la Personne 1, puis rend une prise cohérente avec la description de votre scène dans la zone d'invite du nœud. Gardez votre invite concise et pratique, par exemple en décrivant l'arrière-plan, la distance de la caméra et le comportement. Le résultat est écrit par 💾 Save Video (Single Person) (#4), qui nomme et exporte le fichier pour vous.
Vidéo à 2 Personnes#
Le chemin du dialogue utilise ComfyUI DreamID-Omni Sampler (#22) pour composer deux identités dans un cadre et diriger chaque bouche avec son audio associé. Fournissez une courte invite pour définir l'environnement et le style d'interaction, comme un espace de co-travail, un ton décontracté ou qui parle en premier. Cela aide à stabiliser le placement de la caméra et les gestes tandis que DreamID-Omni et MMAudio maintiennent l'identité et l'alignement des lèvres. Le clip est exporté par 💾 Save Video (Two Persons) (#5).
Pipeline partagé DreamID-Omni#
ComfyUI DreamID-Omni Loader (#23) initialise les composants DreamID-Omni utilisés par les deux chemins. Vous n'avez normalement rien à ajuster ici. Tant que les poids et le nœud ComfyUI sont disponibles, le chargeur prépare le pipeline pour que les échantillonneurs puissent rendre.
Nœuds clés dans le workflow DreamID-Omni de ComfyUI#
ComfyUI DreamID-Omni Loader (#23)#
Initialise le pipeline DreamID-Omni et rend ses poids disponibles pour les échantillonneurs en aval. Il n'y a pas d'entrées utilisateur typiques ici. Si vous maintenez plusieurs variantes de modèles, confirmez que les poids corrects sont installés avant de mettre en file d'attente les rendus.
ComfyUI DreamID-Omni Sampler (#21)#
Rendu à une personne. Ce nœud combine le pipeline du chargeur avec la première image et l'audio de référence pour synthétiser une tête parlante préservant l'identité. Le champ d'invite est l'endroit où vous définissez la scène et le comportement ; la graine contrôle la répétabilité ; la résolution détermine le cadrage et le détail du visage ; et les étapes échangent la vitesse pour la fidélité. Pour des résultats cohérents sur plusieurs prises, réutilisez la même graine et gardez les changements d'invite minimaux.
ComfyUI DreamID-Omni Sampler (#22)#
Rendu à deux personnes. Cette instance accepte deux photos et deux audios, associant chaque voix à son sujet pour un mouvement des lèvres synchronisé. L'invite peut mettre en scène la conversation et la disposition de la caméra. Ajustez la graine et la résolution comme vous le feriez en mode une personne, et assurez-vous que les deux audios sont ajustés à la durée souhaitée avant le rendu.
💾 Save Video (Single Person) (#4)#
Écrit la sortie du locuteur unique sur le disque. Définissez le dossier ou le nom de base pour garder les versions organisées. Si disponible, laissez les options de codec et de taux de trame sur automatique lorsque vous n'êtes pas sûr.
💾 Save Video (Two Persons) (#5)#
Écrit la sortie du dialogue sur le disque. Utilisez un nom de base distinct pour que les clips à une et deux personnes soient faciles à distinguer. Gardez les paramètres d'exportation automatiques pour la fiabilité à moins que vous n'ayez une exigence de livraison spécifique.
Extras optionnels#
- Gardez les visages suffisamment grands dans les images de référence pour occuper une partie significative du cadre pour un verrouillage d'identité plus fort.
- Utilisez un audio de discours propre et bien nivelé. Coupez les silences au début pour éviter les lèvres gelées initiales.
- Pour un look plus stable, réutilisez la même graine lorsque vous itérez sur les invites ou les tenues.
- Si l'espacement à deux personnes semble serré, reformulez l'invite pour élargir la caméra ou augmenter l'espace pour les épaules plutôt que de recadrer les visages.
- Pour les actifs et les mises à jour, voir le modèle et le nœud officiels : DreamID-Omni, ComfyUI_RH_Dreamid-Omni, et DreamID-Omni weights.
Remerciements#
Ce workflow met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Guoxu1233 pour le modèle/workflow DreamID-Omni, HM-RunningHub pour le nœud ComfyUI DreamID-Omni, et XuGuo699 pour les poids du modèle DreamID-Omni pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- Dépôt officiel DreamID-Omni - https://github.com/Guoxu1233/DreamID-Omni
- GitHub: Guoxu1233/DreamID-Omni
- Nœud ComfyUI DreamID-Omni (RunningHub) - https://github.com/HM-RunningHub/ComfyUI_RH_Dreamid-Omni
- Poids du modèle DreamID-Omni (Hugging Face) - https://huggingface.co/XuGuo699/DreamID-Omni
- Hugging Face: XuGuo699/DreamID-Omni
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.
