
Animation Contrôlable dans la Vidéo AI: Flux de Travail WanVideo + TTM Motion Control pour ComfyUI#
Ce flux de travail par mickmumpitz apporte l'animation contrôlable dans la vidéo AI à ComfyUI en utilisant une approche guidée par le mouvement sans formation. Il combine la diffusion image-à-vidéo de WanVideo avec la guidance latente Time‑to‑Move (TTM) et des masques sensibles à la région pour que vous puissiez diriger comment les sujets se déplacent tout en préservant l'identité, la texture et la continuité de la scène.
Vous pouvez commencer à partir d'une plaque vidéo ou de deux images clés, ajouter des masques de région qui concentrent le mouvement où vous le souhaitez, et diriger les trajectoires sans aucun ajustement fin. Le résultat est une animation contrôlable précise et répétable dans la vidéo AI, adaptée aux prises de vue dirigées, à la séquence de mouvement des objets et aux modifications créatives personnalisées.
Modèles clés dans le flux de travail Comfyui Animation Contrôlable dans la Vidéo AI#
- Wan2.2 I2V A14B (HIGH/LOW). Le modèle de diffusion image-à-vidéo de base qui synthétise le mouvement et la cohérence temporelle à partir des invites et des références visuelles. Deux variantes équilibrent la fidélité (HIGH) et l'agilité (LOW) pour différentes intensités de mouvement. Les fichiers du modèle sont hébergés dans les collections communautaires WanVideo sur Hugging Face, par exemple les distributions WanVideo de Kijai. Liens : Kijai/WanVideo_comfy_fp8_scaled, Kijai/WanVideo_comfy
- Lightx2v I2V LoRA. Un adaptateur léger qui renforce la structure et la cohérence du mouvement lors de la composition de l'animation contrôlable dans la vidéo AI avec Wan2.2. Il aide à conserver la géométrie du sujet sous des indices de mouvement plus forts. Lien : Kijai/WanVideo_comfy – Lightx2v LoRA
- Wan2.1 VAE. L'autoencodeur vidéo utilisé pour encoder les images en latents et décoder les sorties du sampler en images sans perdre de détails. Lien : Kijai/WanVideo_comfy – Wan2_1_VAE_bf16.safetensors
- UMT5‑XXL encodeur de texte. Fournit des embeddings de texte riches pour le contrôle basé sur les invites en plus des indices de mouvement. Liens : google/umt5-xxl, Kijai/WanVideo_comfy – encoder weights
- Modèles Segment Anything pour les masques vidéo. SAM3 et SAM2 créent et propagent des masques de région à travers les images, permettant une guidance dépendante de la région qui affine l'animation contrôlable dans la vidéo AI là où c'est important. Liens : facebook/sam3, facebook/sam2
- Qwen‑Image‑Edit 2509 (optionnel). Une base d'édition d'image et un LoRA rapide pour le nettoyage rapide des images de début/fin ou la suppression d'objets avant l'animation. Liens : QuantStack/Qwen‑Image‑Edit‑2509‑GGUF, lightx2v/Qwen‑Image‑Lightning, Comfy‑Org/Qwen‑Image_ComfyUI
- Guidance Time‑to‑Move (TTM). Le flux de travail intègre les latents TTM pour injecter un contrôle de trajectoire de manière sans formation pour l'animation contrôlable dans la vidéo AI. Lien : time‑to‑move/TTM
Comment utiliser le flux de travail Comfyui Animation Contrôlable dans la Vidéo AI#
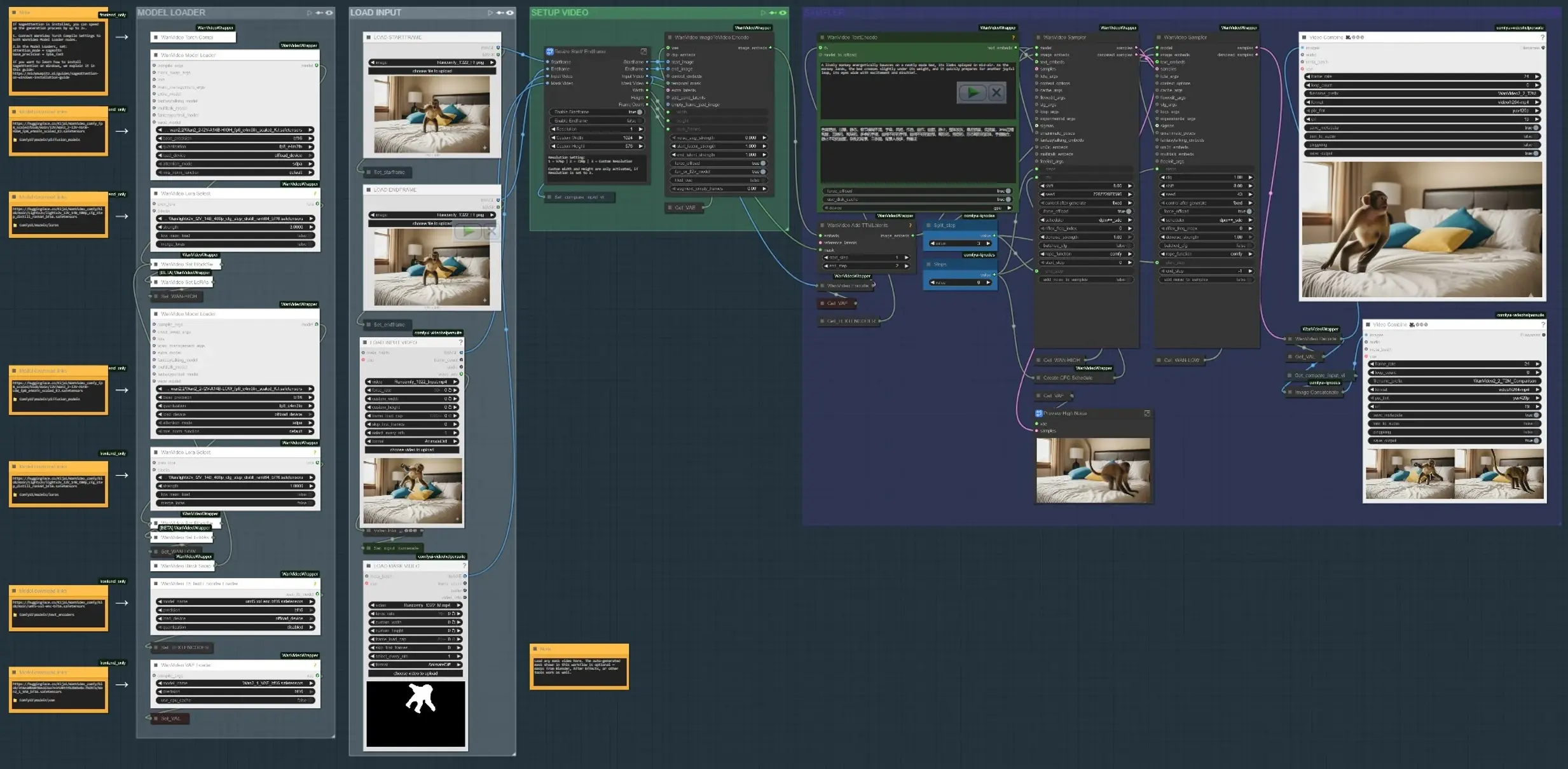
Le flux de travail fonctionne en quatre phases principales : charger les entrées, définir où le mouvement doit se produire, encoder les indices de texte et de mouvement, puis synthétiser et prévisualiser le résultat. Chaque groupe ci-dessous correspond à une section étiquetée dans le graphique.
- CHARGER L'ENTRÉE Utilisez le groupe "LOAD INPUT VIDEO" pour importer une plaque ou un clip de référence, ou charger les images clés de début et de fin si vous construisez un mouvement entre deux états. Le sous-graphe "Resize Start/Endframe" normalise les dimensions et permet éventuellement de bloquer les images de début et de fin. Un comparateur côte à côte construit une sortie qui montre l'entrée par rapport au résultat pour un examen rapide (
VHS_VideoCombine(#613)). - CHARGEUR DE MODÈLE Le groupe "MODEL LOADER" configure Wan2.2 I2V (HIGH/LOW) et applique le Lightx2v LoRA. Un chemin d'échange de blocs mélange des variantes pour un bon compromis fidélité-mouvement avant l'échantillonnage. Le Wan VAE est chargé une fois et partagé à travers l'encodage/décodage. L'encodage de texte utilise UMT5‑XXL pour un conditionnement d'invite fort dans l'animation contrôlable dans la vidéo AI.
- SUJET DU MASQUE SAM3/SAM2 Dans "SAM3 MASK SUBJECT" ou "SAM2 MASK SUBJECT", cliquez sur une image de référence, ajoutez des points positifs et négatifs, et propagez les masques à travers le clip. Cela produit des masques temporellement cohérents qui limitent les modifications de mouvement au sujet ou à la région de votre choix, permettant une guidance dépendante de la région. Vous pouvez également contourner et charger votre propre vidéo de masque ; les masques de Blender/After Effects fonctionnent bien lorsque vous souhaitez un contrôle dessiné par un artiste.
- PRÉPARATION DE L'IMAGE DE DÉBUT/FIN (optionnel) Les groupes "STARTFRAME – QWEN REMOVE" et "ENDFRAME – QWEN REMOVE" offrent un passage de nettoyage optionnel sur des images spécifiques en utilisant Qwen‑Image‑Edit. Utilisez-les pour supprimer les gréements, bâtons ou artefacts de plaque qui pollueraient autrement les indices de mouvement. Le recadrage et la couture en peinture réintègrent l'édition dans l'image complète pour une base propre.
- ENCODAGE TEXTE + MOUVEMENT Les invites sont encodées avec UMT5‑XXL dans
WanVideoTextEncode(#605). Les images de début/fin sont transformées en latents vidéo dansWanVideoImageToVideoEncode(#89). Les latents de mouvement TTM et un masque temporel optionnel sont fusionnés viaWanVideoAddTTMLatents(#104) pour que le sampler reçoive à la fois des indices sémantiques (texte) et de trajectoire, essentiels pour l'animation contrôlable dans la vidéo AI. - ÉCHANTILLONNEUR ET PRÉVISUALISATION L'échantillonneur Wan (
WanVideoSampler(#27) etWanVideoSampler(#90)) débruite les latents en utilisant une configuration à deux horloges : un chemin régit les dynamiques globales tandis que l'autre préserve l'apparence locale. Les étapes et un calendrier CFG configurable façonnent l'intensité du mouvement par rapport à la fidélité. Le résultat est décodé en images et enregistré en tant que vidéo ; une sortie de comparaison aide à juger si votre animation contrôlable dans la vidéo AI correspond au cahier des charges.
Nœuds clés dans le flux de travail Comfyui Animation Contrôlable dans la Vidéo AI#
WanVideoImageToVideoEncode(#89) Encode les images de début/fin en latents vidéo qui amorcent la synthèse de mouvement. Ajustez uniquement lors du changement de résolution de base ou du nombre d'images ; gardez-les alignés avec votre entrée pour éviter l'étirement. Si vous utilisez une vidéo de masque, assurez-vous que ses dimensions correspondent à la taille latente encodée.WanVideoAddTTMLatents(#104) Fusionne les latents de mouvement TTM et les masques temporels dans le flux de contrôle. Basculer l'entrée du masque pour contraindre le mouvement à votre sujet ; le laisser vide applique le mouvement globalement. Utilisez cela lorsque vous souhaitez une animation contrôlable dans la vidéo AI spécifique à une trajectoire sans affecter l'arrière-plan.SAM3VideoSegmentation(#687) Collectez quelques points positifs et négatifs, choisissez une image de suivi, puis propagez à travers le clip. Utilisez la sortie de visualisation pour valider la dérive du masque avant l'échantillonnage. Pour les flux de travail sensibles à la confidentialité ou hors ligne, passez au groupe SAM2 qui ne nécessite pas de portage de modèle.WanVideoSampler(#27) Le débruiteur qui équilibre le mouvement et l'identité. Couplez "Steps" avec la liste de calendrier CFG pour pousser ou relâcher la force du mouvement ; une force excessive peut surpasser l'apparence, tandis que trop peu sous-livre le mouvement. Lorsque les masques sont actifs, l'échantillonneur concentre les mises à jour dans la région, améliorant la stabilité pour l'animation contrôlable dans la vidéo AI.
Extras optionnels#
- Pour des itérations rapides, commencez avec le modèle LOW Wan2.2, réglez le mouvement avec TTM, puis passez à HIGH pour le dernier passage pour récupérer la texture.
- Utilisez des vidéos de masques dessinées par des artistes pour des silhouettes complexes ; le chargeur accepte les masques externes et les redimensionnera pour correspondre.
- Les commutateurs "startframe/endframe" vous permettent de verrouiller la première ou la dernière image visuellement, utile pour des transitions en douceur dans les montages plus longs.
- Si disponible dans votre environnement, activer l'attention optimisée (par exemple, SageAttention) peut accélérer considérablement l'échantillonnage.
- Faites correspondre le taux de trame de sortie à la source dans le nœud de combinaison pour éviter les différences de synchronisation perçues dans l'animation contrôlable dans la vidéo AI.
Ce flux de travail offre un contrôle de mouvement sensible à la région sans formation en combinant des invites de texte, des latents TTM et une segmentation robuste. Avec quelques entrées ciblées, vous pouvez diriger une animation contrôlable dans la vidéo AI nuancée et prête pour la production tout en maintenant les sujets sur le modèle et les scènes cohérentes.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Mickmumpitz qui est le créateur de l'animation contrôlable dans la vidéo AI pour le tutoriel/post, ainsi que l'équipe time-to-move pour TTM pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Patreon/Controllable Animation in AI Video
- Docs / Notes de version : Mickmumpitz Patreon post
- time-to-move/TTM
- GitHub : time-to-move/TTM
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.
