
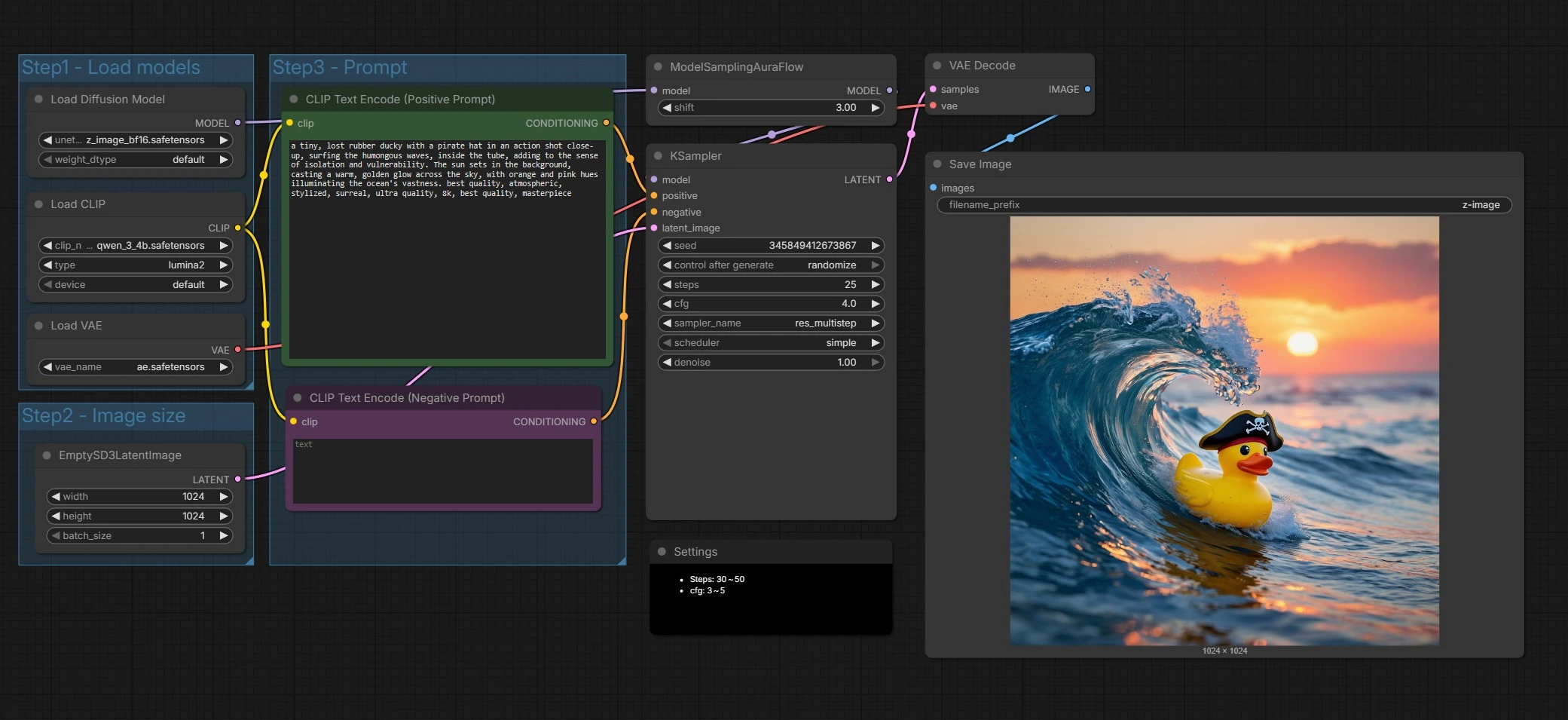
















Flujo de trabajo de texto a imagen Z-Image para ComfyUI#
Este flujo de trabajo de ComfyUI muestra Z-Image, un transformador de difusión de próxima generación diseñado para la generación de imágenes de alta fidelidad y rápida. Construido sobre una arquitectura de flujo único escalable con alrededor de 6 mil millones de parámetros, Z-Image equilibra el fotorrealismo, la fuerte adherencia al prompt y el renderizado de texto bilingüe.
De fábrica, el gráfico está configurado para Z-Image Base para maximizar la calidad mientras permanece eficiente en GPUs comunes. También funciona bien con la variante Z-Image Turbo cuando la velocidad importa, y su estructura facilita la extensión hacia Z-Image Edit para tareas de imagen a imagen. Si buscas un gráfico confiable y minimalista que convierta prompts claros en resultados limpios, este flujo de trabajo Z-Image es un punto de partida sólido.
Modelos clave en el flujo de trabajo Z-Image de ComfyUI#
- Transformador de difusión Z-Image Base (bf16). Generador principal que desruida latentes en imágenes con la topología de flujo único de Z-Image y control de prompts. Model page • bf16 weights
- Codificador de texto Qwen 3 4B. Codifica prompts para Z-Image con cobertura bilingüe fuerte y tokenización clara para el renderizado de texto. encoder weights
- Autoencoder VAE Z-Image. Comprime y reconstruye imágenes entre el espacio de píxeles y el espacio latente de Z-Image. VAE weights
Cómo usar el flujo de trabajo Z-Image de ComfyUI#
A un nivel alto, el gráfico carga los componentes de Z-Image, prepara un lienzo latente, codifica tus prompts positivos y negativos, ejecuta un muestreador ajustado para Z-Image, luego decodifica y guarda el resultado. Principalmente proporcionas el prompt y eliges el tamaño de salida; el resto está configurado para valores predeterminados sensatos.
Paso 1 - Cargar modelos#
Este grupo inicializa el UNet de Z-Image, el codificador de texto Qwen 3 4B y el VAE para que todos los componentes se alineen. El UNETLoader (#66) apunta a Z-Image Base por defecto, lo que favorece la fidelidad y el margen para la edición. El CLIPLoader (#62) incorpora el codificador basado en Qwen que maneja bien los prompts multilingües y los tokens de texto. El VAELoader (#63) establece el autoencoder usado más tarde para la decodificación. Cambia los pesos aquí si quieres probar Z-Image Turbo para borradores más rápidos.
Paso 2 - Tamaño de la imagen#
Este grupo configura el lienzo latente a través de EmptySD3LatentImage (#68). Elige el ancho y la altura que deseas generar, y ten en cuenta la relación de aspecto para la composición. Z-Image funciona bien en tamaños creativos comunes, así que elige dimensiones que coincidan con tus guiones gráficos o formato de entrega. Los tamaños más grandes aumentan el detalle y el costo de cómputo.
Paso 3 - Prompt#
Aquí escribes tu historia. El nodo CLIP Text Encode (Positive Prompt) (#67) toma tu descripción de la escena y directivas de estilo para Z-Image. El CLIP Text Encode (Negative Prompt) (#71) ayuda a alejarse de los artefactos o elementos no deseados. Z-Image está ajustado para el renderizado de texto bilingüe, por lo que puedes incluir contenido de texto en varios idiomas directamente en el prompt cuando sea necesario. Mantén los prompts específicos y visuales para obtener los resultados más consistentes.
Muestreo y desruido#
ModelSamplingAuraFlow (#70) aplica una política de muestreo alineada con el diseño de flujo único de Z-Image, luego KSampler (#69) impulsa el proceso de desruido para convertir el ruido en una imagen que coincida con tus prompts. El muestreador combina tu condicionamiento positivo y negativo con el lienzo latente para refinar iterativamente la estructura y los detalles. Puedes intercambiar velocidad por calidad aquí ajustando la configuración del muestreador como se describe a continuación. Esta etapa es donde la adherencia al prompt de Z-Image y la claridad del texto realmente se muestran.
Decodificar y guardar#
VAEDecode (#65) convierte el latente final en una imagen RGB. SaveImage (#9) escribe archivos usando el prefijo establecido en el nodo para que tus salidas de Z-Image sean fáciles de encontrar y organizar. Esto completa un pase completo de prompt a píxeles.
Nodos clave en el flujo de trabajo Z-Image de ComfyUI#
UNETLoader (#66)#
Carga la columna vertebral de Z-Image que realiza la desruida real. Cambia a otra variante de Z-Image aquí cuando explores casos de uso de velocidad o edición. Si cambias variantes, mantén el codificador y el VAE compatibles para evitar cambios de color o contraste.
CLIP Text Encode (Positive Prompt) (#67)#
Codifica la descripción principal para Z-Image. Escribe frases concisas y visuales que especifiquen sujeto, iluminación, cámara, estado de ánimo y cualquier texto en la imagen. Para el renderizado de texto, pon las palabras deseadas entre comillas y mantenlas cortas para la mejor legibilidad.
CLIP Text Encode (Negative Prompt) (#71)#
Define qué evitar para que Z-Image pueda centrarse en los detalles correctos. Úsalo para suprimir desenfoques, extremidades adicionales, tipografía desordenada o elementos fuera de estilo. Mantenlo breve y temático para que no restrinja demasiado la composición.
EmptySD3LatentImage (#68)#
Crea el lienzo latente donde Z-Image pintará. Elige dimensiones que se adapten al uso final y mantenlas en múltiplos de 64 px para un uso eficiente de la memoria. Los lienzos más anchos o más altos influyen en la composición y la perspectiva, así que ajusta los prompts en consecuencia.
ModelSamplingAuraFlow (#70)#
Selecciona un preajuste de muestreador que coincida con el entrenamiento de Z-Image y el espacio latente. Rara vez necesitas cambiar esto a menos que estés probando muestreadores alternativos. Déjalo como se proporciona para resultados estables y libres de artefactos.
KSampler (#69)#
Controla el intercambio calidad-velocidad para Z-Image. Aumenta steps para más detalle y estabilidad, disminuye para borradores más rápidos. Mantén cfg moderado para equilibrar la adherencia al prompt con texturas naturales; los valores típicos en este gráfico son steps: 30 a 50 y cfg: 3 a 5. Establece una seed fija para reproducibilidad o aleatorízala para explorar variaciones.
VAEDecode (#65)#
Transforma el latente final de Z-Image en una imagen RGB. Si alguna vez cambias el VAE, mantenlo emparejado con la familia de modelos para preservar la precisión del color y la nitidez.
SaveImage (#9)#
Escribe el resultado con un prefijo de nombre de archivo claro para que las salidas de Z-Image sean fáciles de catalogar. Ajusta el prefijo para separar experimentos, variantes de modelos o relaciones de aspecto.
Extras opcionales#
- Usa Z-Image Turbo para la ideación rápida, luego cambia de nuevo a Z-Image Base y aumenta los pasos para renders finales.
- Para prompts bilingües y texto en la imagen, mantén las palabras cortas y con alto contraste en el prompt para ayudar a Z-Image a renderizar una tipografía nítida.
- Bloquea la semilla al comparar pequeñas ediciones de prompts para que las diferencias reflejen tus cambios en lugar de nuevo ruido.
- Si ves sobresaturación o halos, baja ligeramente
cfgo fortalece el prompt negativo para recuperar el equilibrio.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Comfy-Org por el flujo de trabajo plantilla Z-Image Day-0 ComfyUI por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Comfy-Org/Z-Image Day-0 support in ComfyUI
- GitHub: Comfy-Org/workflow_templates
- Docs / Release Notes: Source
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.

