
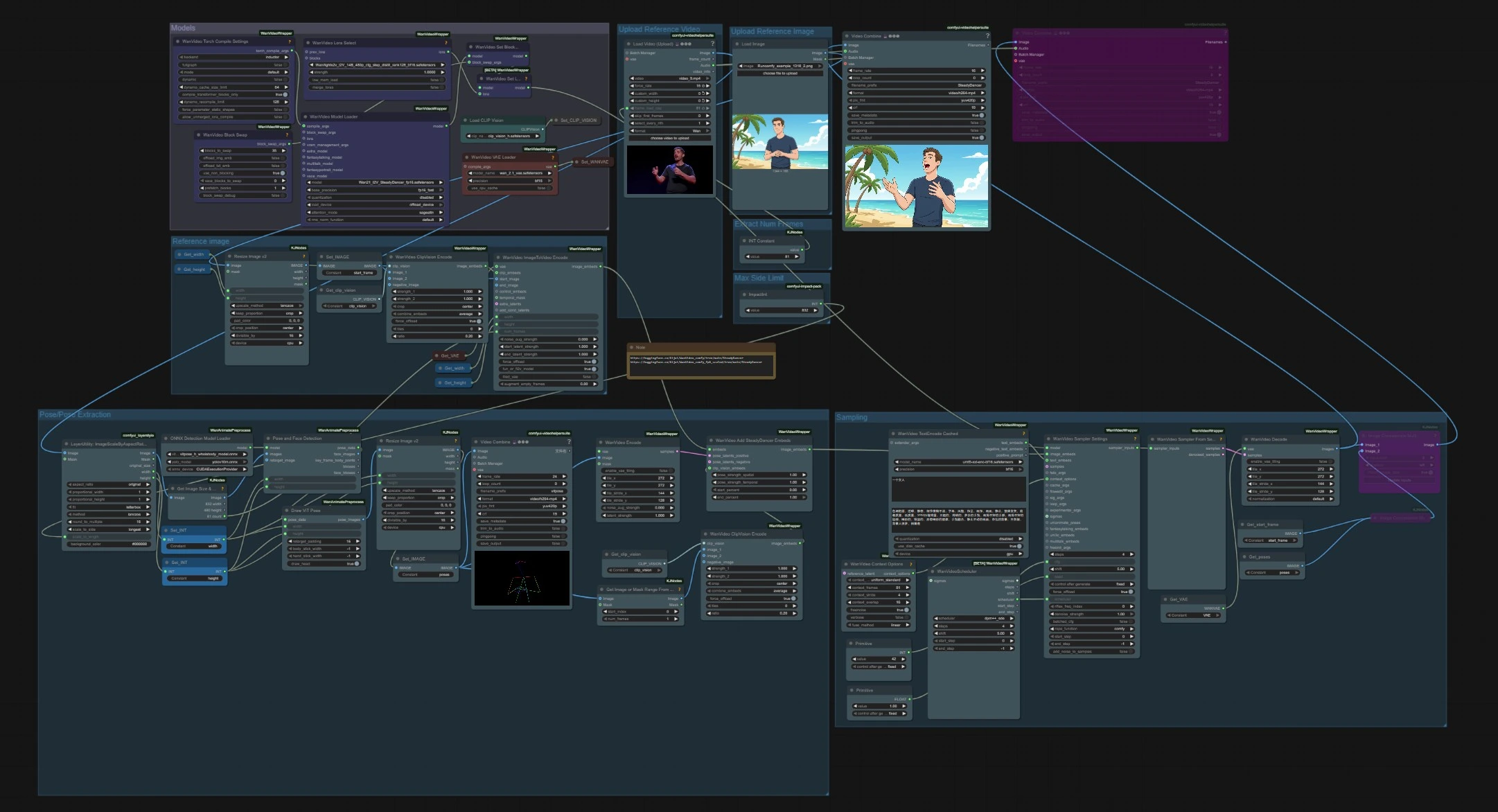
Flujo de trabajo de animación de poses de imagen a video de SteadyDancer#
Este flujo de trabajo de ComfyUI convierte una imagen de referencia única en un video coherente, impulsado por el movimiento de una fuente de pose separada. Se construye alrededor del paradigma de imagen a video de SteadyDancer, de modo que el primer fotograma conserva la identidad y apariencia de tu imagen de entrada, mientras que el resto de la secuencia sigue el movimiento objetivo. El gráfico reconcilia pose y apariencia a través de incrustaciones específicas de SteadyDancer y una canalización de poses, produciendo un movimiento corporal completo suave y realista con fuerte coherencia temporal.
SteadyDancer es ideal para animación humana, generación de danza y dar vida a personajes o retratos. Proporciona una imagen fija más un clip de movimiento, y la canalización de ComfyUI maneja la extracción de poses, la incrustación, el muestreo y la decodificación para entregar un video listo para compartir.
Modelos clave en el flujo de trabajo de Comfyui SteadyDancer#
- SteadyDancer. Modelo de investigación para imagen a video que preserva la identidad con un Mecanismo de Reconciliación de Condiciones y Modulación Sinérgica de Pose. Usado aquí como el método I2V central. GitHub
- Pesos Wan 2.1 I2V SteadyDancer. Puntos de control portados para ComfyUI que implementan SteadyDancer en el stack Wan 2.1. Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) y Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE. VAE de video usado para codificación y decodificación latente dentro de la canalización. Incluido con el puerto WanVideo en Hugging Face arriba.
- OpenCLIP CLIP ViT‑H/14. Codificador de visión que extrae incrustaciones de apariencia robustas de la imagen de referencia. Hugging Face
- ViTPose‑H WholeBody (ONNX). Modelo de puntos clave de alta calidad para cuerpo, manos y cara usado para derivar la secuencia de poses de conducción. GitHub
- YOLOv10 (ONNX). Detector que mejora la localización de personas antes de la estimación de poses en videos diversos. GitHub
- umT5‑XXL codificador. Codificador de texto opcional para orientación de estilo o escena junto con la imagen de referencia. Hugging Face
Cómo usar el flujo de trabajo de Comfyui SteadyDancer#
El flujo de trabajo tiene dos entradas independientes que se encuentran en el muestreo: una imagen de referencia para la identidad y un video de conducción para el movimiento. Los modelos se cargan una vez al principio, se extrae la pose del clip de conducción, y las incrustaciones de SteadyDancer mezclan pose y apariencia antes de la generación y decodificación.
Modelos#
Este grupo carga los pesos principales utilizados a lo largo del gráfico. WanVideoModelLoader (#22) selecciona el punto de control Wan 2.1 I2V SteadyDancer y maneja la atención y los ajustes de precisión. WanVideoVAELoader (#38) proporciona el VAE de video, y CLIPVisionLoader (#59) prepara la columna vertebral de visión CLIP ViT‑H. Un nodo de selección LoRA y opciones de BlockSwap están presentes para usuarios avanzados que deseen cambiar el comportamiento de memoria o adjuntar pesos adicionales.
Cargar Video de Referencia#
Importa la fuente de movimiento usando VHS_LoadVideo (#75). El nodo lee fotogramas y audio, permitiéndote establecer una tasa de fotogramas objetivo o limitar el número de fotogramas. El clip puede ser cualquier movimiento humano como una danza o un movimiento deportivo. El flujo de video luego se dirige a la escala de relación de aspecto y extracción de poses.
Extraer Número de Fotogramas#
Una constante simple controla cuántos fotogramas se cargan del video de conducción. Esto limita tanto la extracción de poses como la longitud de la salida generada de SteadyDancer. Auméntalo para secuencias más largas o redúcelo para iterar más rápido.
Límite de Lado Máximo#
LayerUtility: ImageScaleByAspectRatio V2 (#146) escala los fotogramas mientras preserva la relación de aspecto para que se ajusten a la capacidad y presupuesto de memoria del modelo. Establece un límite de lado largo apropiado para tu GPU y el nivel de detalle deseado. Los fotogramas escalados son utilizados por los nodos de detección posteriores y como referencia para el tamaño de salida.
Extracción de Pose/Pose#
La detección de personas y la estimación de poses se ejecutan en los fotogramas escalados. PoseAndFaceDetection (#89) utiliza YOLOv10 y ViTPose‑H para encontrar personas y puntos clave de manera robusta. DrawViTPose (#88) representa una representación limpia de figura de palo del movimiento, y ImageResizeKJv2 (#77) dimensiona las imágenes de pose resultantes para que coincidan con el lienzo de generación. WanVideoEncode (#72) convierte las imágenes de pose en latentes para que SteadyDancer pueda modular el movimiento sin luchar contra la señal de apariencia.
Cargar Imagen de Referencia#
Carga la imagen de identidad que deseas que SteadyDancer anime. La imagen debe mostrar claramente al sujeto que deseas mover. Usa una pose y un ángulo de cámara que coincidan ampliamente con el video de conducción para una transferencia más fiel. El fotograma se envía al grupo de imágenes de referencia para la incrustación.
Imagen de referencia#
La imagen fija se redimensiona con ImageResizeKJv2 (#68) y se registra como el fotograma inicial a través de Set_IMAGE (#96). WanVideoClipVisionEncode (#65) extrae incrustaciones CLIP ViT‑H que preservan identidad, vestimenta y diseño general. WanVideoImageToVideoEncode (#63) empaqueta ancho, alto y conteo de fotogramas con el fotograma inicial para preparar la condición I2V de SteadyDancer.
Muestreo#
Aquí es donde la apariencia y el movimiento se encuentran para generar video. WanVideoAddSteadyDancerEmbeds (#71) recibe la condición de imagen de WanVideoImageToVideoEncode y la aumenta con latentes de pose más una referencia CLIP-vision, habilitando la reconciliación de condiciones de SteadyDancer. Las ventanas de contexto y la superposición se establecen en WanVideoContextOptions (#87) para la consistencia temporal. Opcionalmente, WanVideoTextEncodeCached (#92) agrega orientación de texto umT5 para ajustes de estilo. WanVideoSamplerSettings (#119) y WanVideoSamplerFromSettings (#129) ejecutan los pasos de eliminación de ruido reales en el modelo Wan 2.1, después de lo cual WanVideoDecode (#28) convierte los latentes de nuevo a fotogramas RGB. Los videos finales se guardan con VHS_VideoCombine (#141, #83).
Nodos clave en el flujo de trabajo de Comfyui SteadyDancer#
WanVideoAddSteadyDancerEmbeds (#71)#
Este nodo es el corazón de SteadyDancer en el gráfico. Fusiona la condición de imagen con latentes de pose y señales de CLIP-vision para que el primer fotograma bloquee la identidad mientras el movimiento se despliega naturalmente. Ajusta pose_strength_spatial para controlar qué tan estrechamente las extremidades siguen el esqueleto detectado y pose_strength_temporal para regular la suavidad del movimiento en el tiempo. Usa start_percent y end_percent para limitar dónde se aplica el control de poses dentro de la secuencia para introducciones y conclusiones más naturales.
PoseAndFaceDetection (#89)#
Ejecuta la detección YOLOv10 y la estimación de puntos clave ViTPose‑H en el video de conducción. Si las poses pierden extremidades pequeñas o caras, aumenta la resolución de entrada aguas arriba o elige metraje con menos oclusiones e iluminación más limpia. Cuando hay múltiples personas presentes, mantén al sujeto objetivo más grande en el fotograma para que el detector y la cabeza de poses se mantengan estables.
VHS_LoadVideo (#75)#
Controla qué porción de la fuente de movimiento usas. Aumenta el límite de fotogramas para salidas más largas o bájalo para prototipos rápidos. La entrada force_rate alinea el espaciado de poses con la tasa de generación y puede ayudar a reducir el tartamudeo cuando el FPS del clip original es inusual.
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
Mantiene los fotogramas dentro de un límite de lado largo elegido mientras mantiene la relación de aspecto y agrupando a un tamaño divisible. Igualar la escala aquí al lienzo de generación para que SteadyDancer no necesite aumentar o recortar agresivamente. Si ves resultados suaves o artefactos en los bordes, acerca el lado largo a la escala de entrenamiento nativa del modelo para una decodificación más limpia.
WanVideoSamplerSettings (#119)#
Define el plan de eliminación de ruido para el muestreador Wan 2.1. El scheduler y los steps establecen la calidad general versus la velocidad, mientras cfg equilibra la adherencia a la imagen más el aviso contra la diversidad. seed bloquea la reproducibilidad y denoise_strength puede reducirse cuando deseas acercarte aún más a la apariencia de la imagen de referencia.
WanVideoModelLoader (#22)#
Carga el punto de control Wan 2.1 I2V SteadyDancer y maneja la precisión, la implementación de atención y la colocación de dispositivos. Déjalos como están configurados para estabilidad. Los usuarios avanzados pueden adjuntar un I2V LoRA para alterar el comportamiento del movimiento o reducir el costo computacional al experimentar.
Extras opcionales#
- Elige una imagen de referencia clara y bien iluminada. Vistas frontales o ligeramente anguladas que se asemejen a la cámara del video de conducción hacen que SteadyDancer preserve la identidad de manera más confiable.
- Prefiere clips de movimiento con un único sujeto prominente y mínima oclusión. Fondos ocupados o cortes rápidos reducen la estabilidad de las poses.
- Si las manos y los pies tiemblan, aumenta ligeramente la fuerza temporal de la pose en
WanVideoAddSteadyDancerEmbedso aumenta el FPS del video para densificar las poses. - Para escenas más largas, procesa en segmentos con contexto superpuesto y une las salidas. Esto mantiene el uso de memoria razonable y mantiene la continuidad temporal.
- Usa los mosaicos de vista previa incorporados para comparar los fotogramas generados contra el fotograma inicial y la secuencia de poses mientras ajustas la configuración.
Este flujo de trabajo de SteadyDancer te ofrece un camino práctico y completo desde una imagen fija hasta un video fiel impulsado por poses con la identidad preservada desde el primer fotograma.
Reconocimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a MCG-NJU por SteadyDancer por sus contribuciones y mantenimiento. Para obtener detalles autorizados, consulta la documentación y los repositorios originales vinculados a continuación.
Recursos#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
Nota: El uso de los modelos, conjuntos de datos y códigos referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.
