
Stable Audio Open 1.0 Flujo de trabajo de Texto a Música#
Este flujo de trabajo convierte texto simple en música y paisajes sonoros originales utilizando Stable Audio Open 1.0. Está diseñado para compositores, diseñadores de sonido y creadores que desean generación de audio rápida y controlable sin salir de ComfyUI. Escribe una indicación, establece una duración objetivo, y el gráfico renderiza un MP3 que refleja tu estilo, estado de ánimo, tempo e instrumentación.
Bajo el capó, el flujo de trabajo codifica tu texto con un codificador de texto basado en T5, ejecuta el proceso de difusión de Stable Audio en el espacio de audio latente, luego decodifica a una forma de onda y guarda el resultado. Con una guía clara de indicaciones y un control de longitud simple, la generación de Stable Audio se vuelve predecible y repetible para pistas cinematográficas, ambientales o experimentales.
Modelos clave en el flujo de trabajo de Stable Audio de ComfyUI#
- Stable Audio Open 1.0. Modelo de difusión latente de pesos abiertos para diseño de sonido y texto a música por Stability AI. Mapea la intención del texto a latentes de audio y soporta estilos y estructuras musicales variadas. Repositorio • Pesos
- Codificador de Texto T5-Base. Modelo de texto de propósito general utilizado aquí para incrustar indicaciones para condicionar la generación de Stable Audio. Entradas claras y descriptivas llevan a música más consistente. Ficha del modelo
Cómo usar el flujo de trabajo de Stable Audio de ComfyUI#
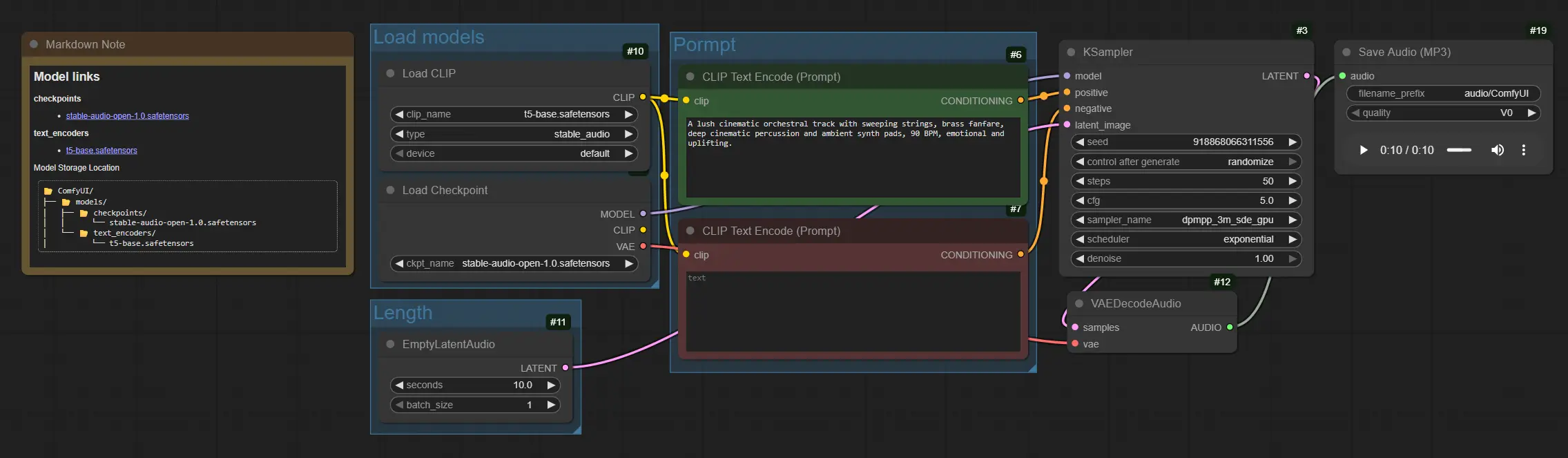
El gráfico fluye desde la carga del modelo hasta el acondicionamiento de la indicación, luego el muestreo, la decodificación y el guardado. Los grupos están organizados para que puedas establecer modelos una vez, ajustar la longitud, escribir tu indicación y renderizar.
Carga de modelos#
Este grupo inicializa los activos principales. CheckpointLoaderSimple (#4) carga el punto de control de Stable Audio Open 1.0, que incluye el modelo de difusión y su VAE de audio. CLIPLoader (#10) carga el codificador de texto basado en T5 utilizado para el acondicionamiento. Una vez cargados, estos modelos proporcionan la columna vertebral para la generación de Stable Audio y permanecen residentes para ejecuciones posteriores.
Longitud#
Este grupo define cuánto durará tu audio. EmptyLatentAudio (#11) crea una pista latente en blanco con la duración elegida para que el muestreador sepa cuántos cuadros generar. Los clips más largos consumen más tiempo y memoria, así que comienza modestamente, luego escala. También puedes producir múltiples variaciones aumentando la dimensión del lote al explorar ideas.
Indicación#
Este grupo convierte el texto en las señales de guía para el proceso de difusión. Usa CLIPTextEncode (#6) para escribir una indicación positiva con instrumentos, género, estado de ánimo, tempo y pistas de producción, por ejemplo: "orquesta cinematográfica exuberante, cuerdas y metales envolventes, percusión profunda, pads ambientales, 90 BPM, edificante." Usa CLIPTextEncode (#7) para una indicación negativa para suprimir artefactos como "ruido áspero, recortes, distorsión." Juntos dirigen Stable Audio hacia las texturas y estructuras que deseas.
Generar y exportar#
KSampler (#3) realiza los pasos de difusión que transforman el latente vacío en un latente musical guiado por tus codificaciones de texto. VAEDecodeAudio (#12) convierte el audio latente de nuevo a una forma de onda. Finalmente, SaveAudioMP3 (#19) escribe un archivo MP3 para que puedas revisarlo o colocarlo directamente en tu línea de tiempo. Para trabajo iterativo, ajusta el prefijo del nombre de archivo para mantener las tomas organizadas.
Nodos clave en el flujo de trabajo de Stable Audio de ComfyUI#
CLIPTextEncode(#6) Este nodo codifica tu indicación positiva en el acondicionamiento que sigue Stable Audio. Prioriza listas claras de instrumentos, género, estado de ánimo, tempo o BPM, y términos de producción como "cálido," "lo-fi," "cinemático," o "ambiental." Cambios sutiles en la redacción pueden cambiar significativamente la composición. Consulta los nodos centrales de ComfyUI para un comportamiento general. ComfyUICLIPTextEncode(#7) La indicación negativa ayuda a evitar timbres indeseados o problemas de mezcla. Agrega términos que describan qué eliminar, por ejemplo "chirriante, timbre metálico, pops de glitch, siseo de radio." Mantener esto conciso a menudo produce renders de Stable Audio más limpios. ComfyUIEmptyLatentAudio(#11) Controla la duración del clip en segundos y opcionalmente la cuenta del lote para múltiples variaciones. Aumenta los segundos para piezas más largas, teniendo en cuenta que el cálculo escala con la longitud. Usa generación por lotes para probar varias tomas de Stable Audio desde una sola indicación. ComfyUIKSampler(#3) Impulsa el proceso de difusión para latentes de audio. Los controles más influyentes sonsteps,sampler,cfg, yseed. Aumentastepspara más detalle refinado, ajustacfgpara equilibrar la adherencia a la indicación con la creatividad, y establece unseedfijo para reproducir una toma o variarla para nuevas ideas. Consulta las notas del muestreador de ComfyUI para orientación general. ComfyUISaveAudioMP3(#19) Exporta la forma de onda final a un MP3. Usa elfilename_prefixpara etiquetar versiones y mantener las iteraciones ordenadas. Al comparar indicaciones o semillas, guardar múltiples tomas lado a lado hace que la selección de Stable Audio sea más rápida. ComfyUI
Extras opcionales#
- Escribe indicaciones como un breve de sesión: instrumentos, género, estado de ánimo, tempo o BPM, y adjetivos de mezcla.
- Usa indicaciones negativas cortas y enfocadas para reducir el siseo, la dureza o los instrumentos no deseados.
- Bloquea
seedmientras iteras texto, luego cambiaseedpara explorar nuevas variaciones de Stable Audio. - Comienza con duraciones más cortas para ajustar el estilo, luego alarga una vez que el sonido sea correcto.
- Mantén un prefijo de nombre de archivo consistente por concepto para que puedas comparar tomas de Stable Audio más tarde.
Recursos para una lectura más profunda: detalles del modelo de Stable Audio y ejemplos aquí, núcleo de ComfyUI y comportamiento de nodos aquí, y la ficha del modelo T5-Base aquí.
Reconocimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Stability AI por Stable Audio Open, comfyanonymous (ComfyUI) por los nodos de ComfyUI y referencias de flujo de trabajo, y Comfy-Org y ComfyUI-Wiki por el punto de control de Stable Audio Open 1.0 y el codificador de texto T5-Base por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Comfy-Org/Flujo de trabajo de Stable Audio Open 1.0
- GitHub: Stability-AI/stable-audio-open
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.