
Control de Pose LipSync con Wan2.2 S2V: imagen a video controlado por pose y audio para avatares expresivos#
Control de Pose LipSync con Wan2.2 S2V transforma una sola imagen, un clip de audio y un video de referencia de pose en una actuación sincronizada que habla. El personaje en tu imagen de referencia sigue el movimiento corporal del video de referencia mientras los movimientos labiales coinciden con el audio. Este flujo de trabajo de ComfyUI es ideal para avatares, escenas de historias, tráilers, explicadores y videos musicales donde deseas un control preciso sobre la pose, la expresión y el tiempo del habla.
Construido sobre la familia de modelos Wan 2.2 S2V 14B, el flujo de trabajo fusiona mensajes de texto, características vocales limpias y mapas de poses para generar movimiento cinematográfico con identidad estable. Está diseñado para ser simple de operar mientras proporciona a los creadores un control fino sobre la apariencia, el ritmo y el encuadre.
Modelos clave en el flujo de trabajo de Comfyui Control de Pose LipSync con Wan2.2 S2V#
- Wan2.2‑S2V‑14B. El generador principal de habla a video que transforma una imagen fija más audio en video, con acondicionamiento de pose opcional para guiar el movimiento. Consulta el repositorio oficial y la tarjeta del modelo para capacidades y notas de uso: Wan‑Video/Wan2.2 y Wan‑AI/Wan2.2‑S2V‑14B.
- Wan VAE. El autoencoder Wan codifica y decodifica latentes de video con alta fidelidad y se utiliza en las tuberías Wan 2.x. Implementación de referencia: tuberías Wan en Diffusers documentación.
- Google UMT5‑XXL codificador de texto. Proporciona un fuerte acondicionamiento de texto multilingüe para el control de la intención de la escena y el estilo a alto nivel dentro de las tuberías Wan. Tarjeta del modelo: google/umt5‑xxl.
- Facebook Wav2Vec2‑Large. Extrae características de habla robustas que impulsan la sincronización labial y las microexpresiones. Tarjeta del modelo: facebook/wav2vec2‑large‑960h.
- DWPose con detector YOLOX. Genera puntos clave de pose humana y mapas de pose del video de referencia para guiar el movimiento corporal completo. Repos: IDEA‑Research/DWPose y Megvii‑BaseDetection/YOLOX.
- LightX2V LoRA para Wan. Un LoRA ligero utilizado para acelerar la descomposición de estilo de imagen a video de bajo paso mientras se preserva la calidad del movimiento; Wan 2.2 admite LoRAs en sus descomponedores. Consulta la guía de Wan Diffusers sobre el uso de LoRA en tuberías Wan.
Cómo usar el flujo de trabajo de Comfyui Control de Pose LipSync con Wan2.2 S2V#
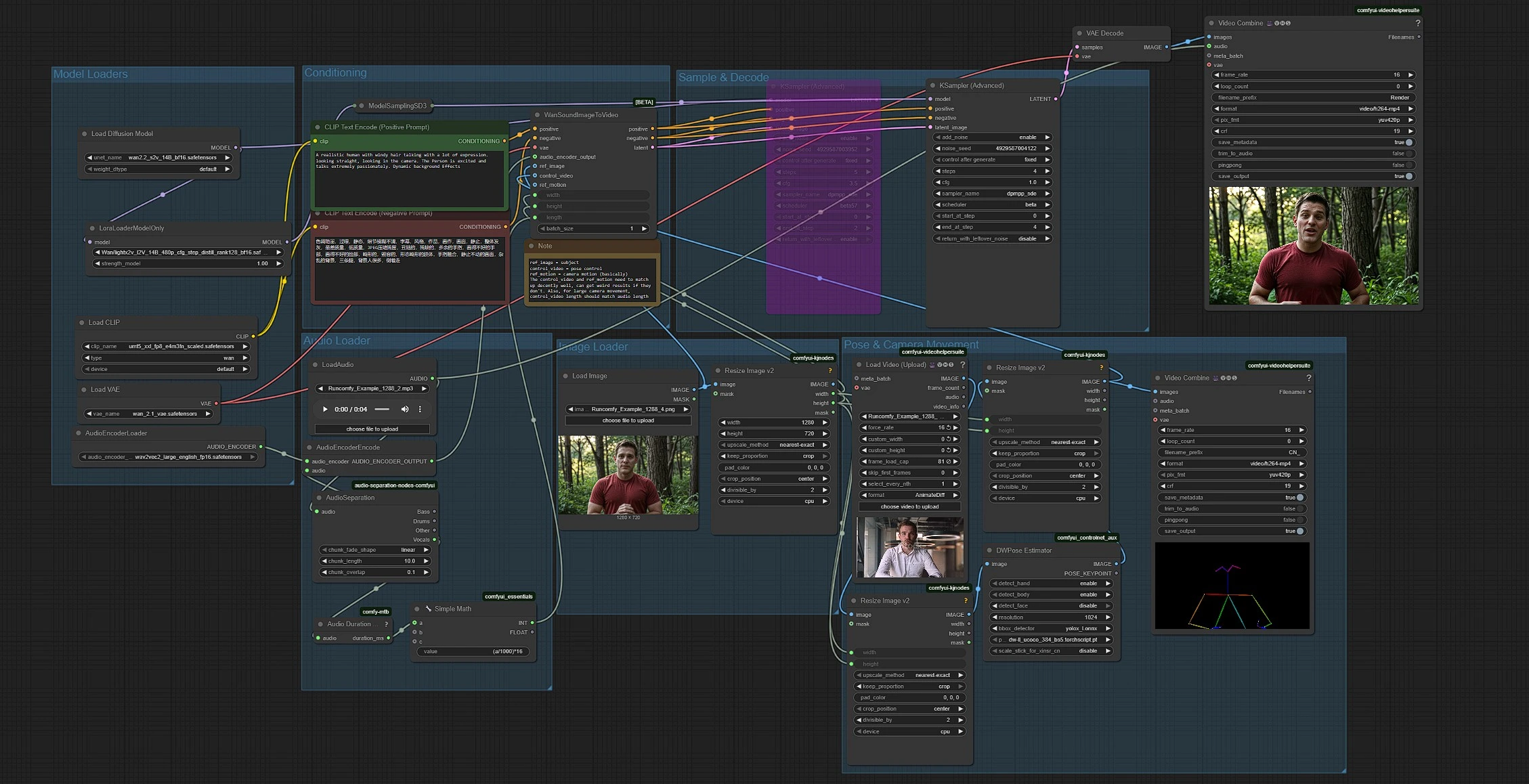
El flujo de trabajo combina cinco partes: carga de modelos, preparación de audio, entradas de imagen y pose, acondicionamiento y generación. Los grupos se ejecutan en un flujo de izquierda a derecha, con la longitud del audio estableciendo automáticamente la duración del clip a 16 fps.
Cargadores de Modelos#
Este grupo carga el modelo Wan 2.2 S2V, su VAE, el codificador de texto UMT5‑XXL y un LightX2V LoRA. El transformador base se inicializa en UNETLoader (#37) y se adapta con LoraLoaderModelOnly (#61) para un muestreo más rápido de bajo paso. El VAE de Wan es suministrado por VAELoader (#39). Los codificadores de texto son proporcionados por CLIPLoader (#38) que carga los pesos UMT5‑XXL referenciados por Wan. Rara vez necesitas tocar este grupo a menos que cambies archivos de modelo.
Cargador de Audio#
Inserta un archivo de audio con LoadAudio (#58). AudioSeparation (#85) aísla el tallo vocal para que los labios sigan un habla clara o canto en lugar de instrumentos de fondo. Audio Duration (mtb) (#70) mide el clip y SimpleMath+ (#71) convierte la duración en un conteo de cuadros a 16 fps para que la longitud del video coincida con tu audio. AudioEncoderEncode (#56) alimenta un codificador Wav2Vec2‑Large para que Wan pueda mapear fonemas a formas de boca para una sincronización labial precisa.
Cargador de Imágenes#
LoadImage (#52) proporciona la imagen fija del sujeto que lleva la identidad, la ropa y la configuración de la cámara. ImageResizeKJv2 (#69) lee las dimensiones de la imagen para que la tubería derive consistentemente el ancho y la altura objetivo para todas las etapas posteriores. Usa una imagen nítida, de frente y sin obstrucciones en la boca para los movimientos labiales más fieles.
Movimiento de Pose y Cámara#
VHS_LoadVideo (#80) importa tu video de referencia de pose. ImageResizeKJv2 (#83) adapta los cuadros al tamaño objetivo, y DWPreprocessor (#78) los convierte en mapas de poses con detección YOLOX más puntos clave de DWPose. Un ImageResizeKJv2 (#81) final alinea los cuadros de pose a la resolución de generación antes de pasarlos como el video de control. Puedes previsualizar las salidas de pose enrutando a VHS_VideoCombine (#95), lo que ayuda a confirmar que el encuadre y el tiempo de referencia se ajustan a tu sujeto.
Acondicionamiento#
Escribe el estilo y la intención de la escena en CLIP Text Encode (Positive Prompt) (#6) y usa CLIP Text Encode (Negative Prompt) (#7) para desalentar artefactos no deseados. Los mensajes dirigen la estética de alto nivel y el movimiento de fondo, mientras que el audio impulsa los movimientos labiales y la referencia de pose gobierna la dinámica corporal. Mantén los mensajes concisos y alineados con tu ángulo de cámara objetivo y estado de ánimo.
Muestra y Decodifica#
WanSoundImageToVideo (#55) fusiona texto, características de audio, la imagen de referencia y el video de control de pose, luego prepara una secuencia latente. KSamplerAdvanced (#64) realiza una descomposición de bajo paso adecuada para la aceleración estilo LightX2V, y VAEDecode (#8) reconstruye los cuadros. VHS_VideoCombine (#62) ensambla los cuadros en un MP4 y adjunta tu audio original para que la salida esté lista para revisar o editar.
Nodos clave en el flujo de trabajo de Comfyui Control de Pose LipSync con Wan2.2 S2V#
WanSoundImageToVideo (#55)#
El corazón del flujo de trabajo que condiciona Wan2.2‑S2V con tu mensaje, voces, imagen del sujeto y video de control de pose. Ajusta solo lo que importa: establece width, height y length para que coincidan con tu imagen del sujeto y la longitud del audio, y conecta un video de pose preprocesado para el control del movimiento. Deja ref_motion vacío a menos que planees inyectar una pista de cámara separada. El comportamiento de habla a video del modelo se describe en Wan‑AI/Wan2.2‑S2V‑14B y Wan‑Video/Wan2.2.
DWPreprocessor (#78)#
Genera mapas de poses usando YOLOX para detección y DWPose para puntos clave de cuerpo completo. Las señales de pose fuertes ayudan a Wan a seguir extremidades y torso mientras el audio controla los labios y las expresiones. Si tu referencia tiene mucho movimiento de cámara, usa un video de pose que alinee el punto de vista y el tiempo con la actuación prevista. DWPose y sus variantes se documentan en IDEA‑Research/DWPose.
KSamplerAdvanced (#64)#
Ejecuta la descomposición para la secuencia latente. Con un LightX2V LoRA cargado, puedes mantener los pasos bajos para vistas previas rápidas mientras retienes la coherencia del movimiento; aumenta los pasos cuando busques el máximo detalle. Las elecciones de programador afectan la suavidad del movimiento frente a la nitidez, y deben ajustarse junto con el uso de LoRA como se describe para Wan en la documentación de Diffusers.
VHS_LoadVideo (#80)#
Importa y examina tu referencia de pose. Usa sus herramientas de selección de cuadros en el nodo para elegir el segmento exacto que coincide con tu segmento de audio. Mantener el encuadre y el tamaño del sujeto consistentes con la imagen de referencia estabilizará la transferencia de movimiento. El nodo es parte de VideoHelperSuite: ComfyUI‑VideoHelperSuite.
VHS_VideoCombine (#62)#
Combina los cuadros generados y tu audio en un MP4 y guarda los metadatos del flujo de trabajo. Establece la velocidad de fotogramas de salida a 16 fps para que coincida con el conteo de cuadros calculado a partir de la duración del audio en este flujo de trabajo. Desactiva o activa el guardado de metadatos según tus necesidades de gestión de activos. Consulta la documentación de VideoHelperSuite en ComfyUI‑VideoHelperSuite.
AudioSeparation (#85)#
Aísla las voces para que las características de Wav2Vec2 impulsen las formas de la boca sin interferencia de instrumentos o efectos. Si tu entrada ya es un discurso limpio, puedes omitir la separación. Para obtener los mejores resultados, mantén los niveles de audio consistentes y minimiza la reverberación.
Extras opcionales#
- Para una mejor sincronización labial, prefiere discursos limpios o voces a capella. Wav2Vec2 funciona a 16 kHz; la mayoría de las tuberías muestrean automáticamente, pero suministrar archivos de 16 kHz ayuda.
- Usa una imagen del sujeto bien iluminada, de frente y con dientes y labios visibles. Las obstrucciones reducen la precisión.
- Haz coincidir el encuadre y el movimiento de la referencia de pose con tu sujeto. Los grandes movimientos de cámara funcionan mejor cuando la longitud del video de pose coincide con el segmento de audio.
- Comienza en 480p para una iteración rápida; pasa a 720p para calidad final. Wan 2.2 admite ambas resoluciones en S2V.
- Mantén los mensajes cortos y consistentes con la configuración de la cámara en tu imagen y referencia de pose para evitar conflictos.
- Si experimentas con LoRAs, asegúrate de que sean compatibles con los descomponedores de Wan 2.2. Consulta las notas de LoRA en los documentos de Wan Diffusers.
Este flujo de trabajo de Control de Pose LipSync con Wan2.2 S2V te ofrece un camino rápido desde el audio y una imagen fija a una actuación controlable y en el ritmo que parece cohesiva y se siente expresiva.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a @ArtOfficialLabs de Pose Control LipSync con Wan2.2 S2VDemo por sus contribuciones y mantenimiento. Para detalles autoritativos, consulta la documentación original y los repositorios vinculados a continuación.
Recursos#
- YouTube/Pose Control LipSync con Wan2.2 S2VDemo
- Documentos / Notas de lanzamiento de @ArtOfficialLabs: Pose Control LipSync con Wan2.2 S2VDemo
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.