
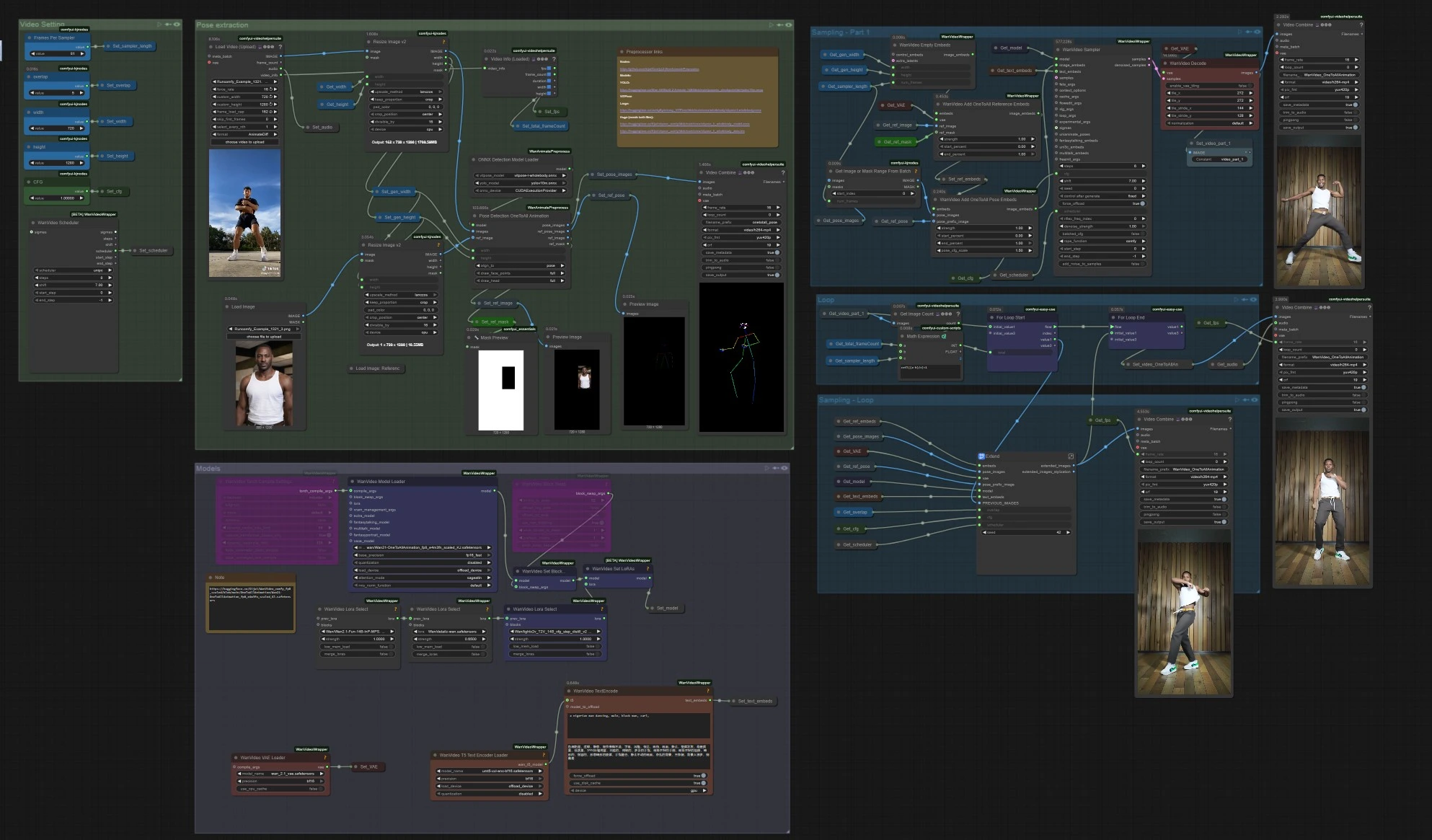
Animación de Uno a Todos: video de personaje alineado con pose en ComfyUI#
Este flujo de trabajo de Animación de Uno a Todos convierte un clip de referencia corto en un video extendido de alta fidelidad, manteniendo el movimiento, la alineación de la pose y la identidad del personaje consistente a lo largo de toda la secuencia. Construido alrededor de la generación de video de Wan 2.1 con guía de pose de cuerpo completo y un extensor de ventana deslizante, es ideal para captura de actuación, danza y tomas narrativas donde deseas que una sola apariencia siga un movimiento complejo.
Si eres un creador que necesita resultados estables impulsados por poses sin temblores o desvíos de identidad, Animación de Uno a Todos te ofrece un camino claro: extrae poses de tu video fuente, fusiónalas con una imagen de referencia y máscara, genera el primer segmento, luego extiende ese segmento repetidamente hasta que se cubra toda la longitud.
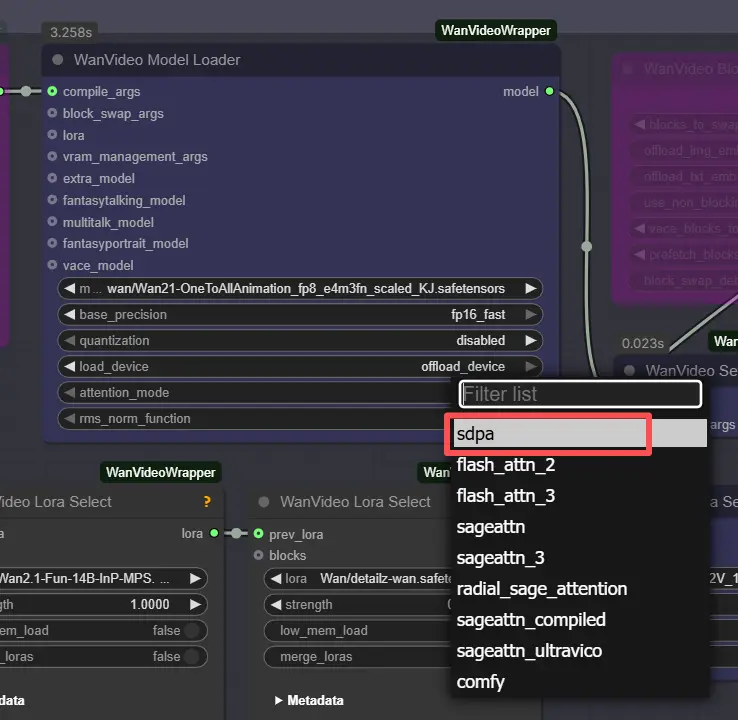
Nota: En máquinas 2XL o 3XL, por favor establece el attention_mode a "sdpa" en el nodo WanVideo Model Loader. El backend segeattn por defecto puede causar problemas de compatibilidad en GPUs de alta gama.
Modelos clave en el flujo de trabajo de Animación de Uno a Todos en ComfyUI#
- Wan 2.1 OneToAllAnimation (generación de video). El modelo de difusión principal utilizado para retención de movimiento e identidad de alta calidad. Pesos de ejemplo: Wan21-OneToAllAnimation fp8 escalado por Kijai. Tarjeta del modelo
- Codificador de texto UMT5-XXL. Codifica indicaciones para la generación de video Wan. Tarjeta del modelo
- ViTPose Whole-Body (estimación de pose). Produce puntos clave esqueléticos densos que impulsan la fidelidad de la pose. Ver el documento de ViTPose y los pesos ONNX de cuerpo completo. Documento • Pesos
- Detector YOLOv10m (detección de persona/región). Acelera la extracción de poses robustas al enfocar el estimador en el sujeto. Documento • Pesos
- Alternativa opcional ViTPose-H. Modelo de cuerpo completo de mayor capacidad para movimientos desafiantes. Pesos y archivo de datos
- Paquetes LoRA opcionales para estilo/control. Los LoRAs utilizados en este gráfico incluyen Wan2.1-Fun-InP-MPS, detailz-wan, y lightx2v T2V; refinan la textura, el detalle o el control in situ sin reentrenar.
Cómo usar el flujo de trabajo de Animación de Uno a Todos en ComfyUI#
Flujo general
- El flujo de trabajo lee tu video de movimiento de referencia, extrae poses de cuerpo completo, prepara incrustaciones de Animación de Uno a Todos que fusionan la pose y una referencia de personaje, genera un clip inicial, luego extiende repetidamente ese clip con superposición hasta que se cubra toda la duración. Finalmente, fusiona audio y exporta un video completo.
Extracción de pose
- Carga tu fuente de movimiento en
VHS_LoadVideo(#454). Los fotogramas se redimensionan conImageResizeKJv2(#131) para que coincidan con la relación de aspecto de generación para un muestreo estable. OnnxDetectionModelLoader(#128) carga YOLOv10m y ViTPose de cuerpo completo;PoseDetectionOneToAllAnimation(#141) luego emite un mapa de pose por fotograma, una imagen de pose de referencia y una máscara de referencia limpia.- Usa
PreviewImage(#145) para inspeccionar rápidamente que las poses siguen al sujeto. Imágenes claras y de alto contraste con un desenfoque de movimiento mínimo ofrecen los mejores resultados de Animación de Uno a Todos.
Modelos
WanVideoModelLoader(#22) carga los pesos de Wan 2.1 OneToAllAnimation;WanVideoVAELoader(#38) proporciona el VAE emparejado. Si lo deseas, apila LoRAs de estilo/control a través deWanVideoLoraSelect(#452, #451, #56) y aplícalos conWanVideoSetLoRAs(#80).- Las indicaciones de texto se codifican mediante
WanVideoTextEncode(#16). Escribe una indicación positiva concisa y centrada en la identidad y una limpieza negativa fuerte para mantener al personaje en el modelo.
Configuración de video
- El ancho y la altura se establecen en el grupo "Configuración de Video" y se propagan a la extracción de poses y generación para que todo se mantenga alineado.
Nota: ⚠️ Límite de Resolución: Este flujo de trabajo está fijado a 720×1280 (720p). Usar cualquier otra resolución causará errores de desajuste de dimensiones a menos que el flujo de trabajo se reconfigure manualmente.
WanVideoScheduler(#231) y el controlCFGseleccionan el calendario de ruido y la fuerza de la indicación. Un CFG más alto se adhiere más a la indicación; los valores más bajos siguen la pose un poco más libremente pero pueden reducir los artefactos.VHS_VideoInfoLoaded(#440) lee el fps y el conteo de fotogramas del clip fuente, que el bucle usa para determinar cuántas ventanas de Animación de Uno a Todos se necesitan.
Muestreo – Parte 1
WanVideoEmptyEmbeds(#99) crea un contenedor para el acondicionamiento en el tamaño objetivo.WanVideoAddOneToAllReferenceEmbeds(#105) inyecta tu imagen de referencia y suref_maskpara bloquear la identidad y preservar o ignorar áreas como el fondo o la ropa.WanVideoAddOneToAllPoseEmbeds(#98) adjunta laspose_imagesextraídas y lapose_prefix_imagepara que el primer segmento generado siga el movimiento fuente desde el primer fotograma.WanVideoSampler(#27) produce el clip latente inicial, que es decodificado porWanVideoDecode(#28) y opcionalmente previsualizado o guardado conVHS_VideoCombine(#139). Este es el segmento de semilla a extender.
Bucle
VHS_GetImageCount(#327) yMathExpression|pysssss(#332) calculan cuántos pases de extensión se requieren según el total de fotogramas y la longitud por pase.easy forLoopStart(#329) comienza los pases de extensión usando el clip inicial como contexto de inicio.
Muestreo – Bucle
Extend(#263) es el corazón de la Animación de Uno a Todos de longitud larga. Recalcula el acondicionamiento conWanVideoAddOneToAllExtendEmbeds(dentro del subgrafo) para mantener la continuidad de los latentes anteriores, luego muestrea y decodifica la siguiente ventana.ImageBatchExtendWithOverlap(dentro deExtend) mezcla cada nueva ventana en el video acumulado usando una región deoverlap, suavizando los límites y reduciendo las costuras temporales.easy forLoopEnd(#334) añade cada bloque extendido. El resultado se almacena a través deSet_video_OneToAllAnimation(#386) para exportación.
Exportar
VHS_VideoCombine(#344) escribe el video final, usando el fps fuente y el audio opcional deVHS_LoadVideo. Si prefieres un resultado silencioso, omite o silencia la entrada de audio aquí.
Nodos clave en el flujo de trabajo de Animación de Uno a Todos en ComfyUI#
PoseDetectionOneToAllAnimation (#141)
- Detecta al sujeto y estima puntos clave de cuerpo completo que impulsan la guía de pose. Respaldado por YOLOv10 y ViTPose, es robusto ante movimientos rápidos y oclusión parcial. Si tu sujeto se desplaza o escenas multi-persona confunden al detector, recorta tu entrada o cambia a los pesos ViTPose-H de mayor capacidad vinculados arriba.
WanVideoAddOneToAllReferenceEmbeds (#105)
- Fusiona una imagen de referencia y
ref_masken el acondicionamiento para que la identidad, el atuendo o las regiones protegidas permanezcan estables a lo largo de los fotogramas. Máscaras ajustadas preservan caras y cabello; máscaras más amplias pueden bloquear fondos. Al cambiar el aspecto, intercambia la referencia y mantén el mismo movimiento.
WanVideoAddOneToAllPoseEmbeds (#98)
- Vincula mapas de poses y una pose prefijo a las incrustaciones de Animación de Uno a Todos. Para coreografía más estricta, aumenta la influencia de la pose; para una interpretación más libre, redúcelo ligeramente. Combina con LoRAs cuando deseas textura consistente mientras aún combinas movimiento.
WanVideoSampler (#27)
- El muestreador de video principal que convierte incrustaciones y texto en el clip latente inicial.
cfgcontrola la adherencia a la indicación, yschedulerintercambia calidad, velocidad y estabilidad. Usa la misma familia de muestreadores aquí y en el bucle para evitar parpadeos.
Extend (#263)
- Un subgrafo compacto que realiza la extensión de ventana deslizante con superposición. La configuración de
overlapes el dial clave: más superposición mezcla transiciones más suavemente a costa de computación extra; menos superposición es más rápida pero puede revelar costuras. Este nodo también reutiliza latentes anteriores para mantener la escena y el personaje coherentes a través de las ventanas.
VHS_VideoCombine (#344)
- Multiplexación y guardado final. Establece el
frame_ratedesde el fps detectado para mantener el tiempo de movimiento fiel a tu fuente. Puedes recortar o hacer bucles en postproducción, pero exportar al ritmo original preserva la sensación de la actuación.
Extras opcionales#
- Notas de instalación para preprocesadores. Los nodos del extractor de poses provienen del complemento de la comunidad. Consulta el repositorio para la configuración y colocación de ONNX. ComfyUI-WanAnimatePreprocess
- Prefiere ViTPose-H para movimientos difíciles. Cambia a ViTPose-H cuando las manos/pies sean rápidos o parcialmente ocluidos; descarga tanto el modelo como su archivo de datos desde las páginas vinculadas arriba.
- Ajuste para ejecuciones largas. Si alcanzas los límites de VRAM, reduce la longitud de la ventana por pase o simplifica las pilas LoRA. La superposición luego puede ser ajustada un poco para mantener transiciones limpias.
- Fuerte retención de identidad. Usa una referencia de alta calidad y de frente, y pinta una
ref_maskprecisa para proteger cara, cabello o atuendo. Esto es crítico para secuencias largas de Animación de Uno a Todos. - Imágenes limpias ayudan. Alta velocidad de obturación, iluminación constante y un sujeto en primer plano claro mejorarán dramáticamente el seguimiento de poses y reducirán el temblor en las salidas de Animación de Uno a Todos.
- Utilidades de video. El exportador y los nodos de ayuda provienen de Video Helper Suite. Si deseas control adicional sobre códecs o previsualizaciones, consulta la documentación del proyecto. Video Helper Suite
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a Innovate Futures @ Benji por el tutorial del flujo de trabajo de Animación de Uno a Todos y a ssj9596 por el proyecto de Animación de Uno a Todos por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios vinculados a continuación.
Recursos#
- Innovate Futures @ Benji/Fuente de Animación de Uno a Todos
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940
- Documentos / Notas de Lanzamiento: Publicación en Patreon
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.


