
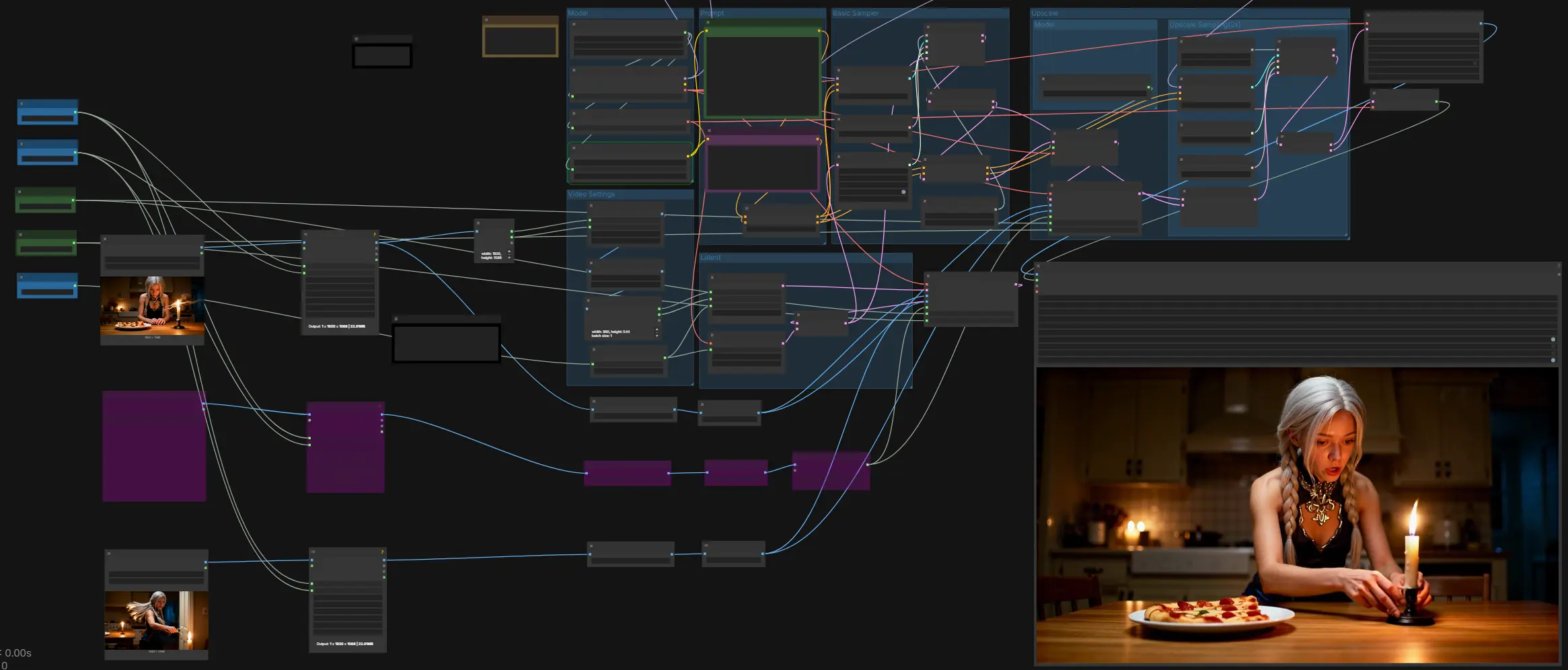
LTX-2 Primer Último Fotograma: generación de video controlada de inicio a fin, sincronizada con audio en ComfyUI#
LTX-2 Primer Último Fotograma es un flujo de trabajo de ComfyUI para creadores que desean un movimiento cinematográfico preciso entre un fotograma de inicio definido y un fotograma final mientras generan audio y visuales sincronizados en una sola pasada. Al condicionarse en ambas imágenes (y opcionalmente un fotograma intermedio de guía), el flujo de trabajo preserva la identidad, el encuadre y la iluminación a lo largo de la toma, luego dirige el movimiento para aterrizar exactamente en el último fotograma. Está diseñado para ritmos narrativos, transiciones de título o escena, movimientos de cámara y cualquier momento donde la continuidad temporal y la alineación de audio sean importantes.
Impulsado por el modelo en tiempo real LTX-2, el flujo de trabajo mantiene la iteración rápida mientras ofrece un control preciso sobre los prompts, el comportamiento de la cámara a través de LoRAs y la fuerza del primer/último fotograma. El resultado es una secuencia suave y coherente cuyo tiempo, apariencia y sonido siguen tus indicaciones desde el primer fotograma hasta el último.
Nota: Para tipos de máquinas por debajo de 2x Grande, por favor utiliza el modelo "ltx-2-19b-dev-fp8.safetensors" !
Modelos clave en el flujo de trabajo LTX-2 Primer Último Fotograma de ComfyUI#
- LTX-2 19B (dev). El modelo central de generación de video que produce latentes de audio-video conjuntos a partir de texto y controles de fotograma; admite iteración en tiempo real y LoRAs conscientes de la cámara. Ver el repositorio oficial y pesos: Lightricks/LTX-2 en GitHub y Lightricks/LTX-2 en Hugging Face.
- Gemma 3 12B Instruct text encoder para LTX-2. Proporciona una comprensión robusta del lenguaje afinada por instrucciones para la generación de prompts visuales y de audio en este flujo de trabajo; empaquetado para ComfyUI como un codificador de texto compatible con LTX. Referencia de pesos: Comfy-Org/ltx-2 split text encoders.
- LTXV Audio VAE (vocoder de 24 kHz). Codifica y decodifica latentes de audio para que la banda sonora se genere junto con el video y se mantenga sincronizada con la acción en pantalla. Ver el contexto de la familia de modelos en Lightricks/LTX-2.
- LTX-2 Spatial Upscaler x2. Un escalador latente para obtener resultados más limpios y de alta resolución después del paso base, utilizado durante la etapa de muestreo de escalado. Los pesos están disponibles bajo Lightricks/LTX-2.
- Paquete LTX-2 LoRA para control de cámara y detalle. LoRAs opcionales como Dolly In/Out/Left/Right, Jib Up/Down, Static, y un Detallador de Condicionamiento de Imagen dan forma al movimiento de la cámara y al detalle fino. Navega por la colección oficial: Lightricks LTX-2 LoRAs.
Cómo usar el flujo de trabajo LTX-2 Primer Último Fotograma de ComfyUI#
Este flujo de trabajo se mueve desde entradas y prompts hasta una muestra base de audio-video, luego realiza un paso de escalado guiado 2x antes de decodificar y mezclar en MP4 con audio. Se basa en controles de primer/último fotograma tanto en las etapas base como de escalado, con un fotograma intermedio opcional para estabilizar la trayectoria.
Modelo#
El grupo Modelo carga el punto de control LTX-2, el codificador de texto Gemma 3 12B Instruct, y el LTXV Audio VAE. Usa el panel ckpt_name para seleccionar entre variantes estándar y FP8 según tu GPU. El codificador de texto es proporcionado por LTXAVTextEncoderLoader y alimenta tanto prompts positivos como negativos. El audio VAE permite la generación conjunta de audio-video para que los diálogos, efectos o ambientes descritos en el prompt emerjan con los visuales.
Prompt#
Escribe la escena en el prompt positivo y lista los rasgos indeseables en el prompt negativo. Describe acciones a lo largo del tiempo, especificaciones visuales clave y eventos sonoros en el orden en que deben ocurrir. El bloque LTXVConditioning aplica tu prompt junto con la tasa de fotogramas elegida para que el tiempo y el movimiento se interpreten de manera consistente. Trata el audio como parte del prompt cuando necesites discurso, efectos o ambiente.
Configuración de Video#
Configura Width, Height y el total de Video Frames, luego elige Length para el espaciamiento de control de primer/último si es necesario. El flujo de trabajo asegura que las dimensiones coincidan con los requisitos del modelo y escala las entradas apropiadamente. Si tus imágenes de entrada son más grandes, el gráfico lee su tamaño para inicializar el lienzo latente y redimensiona los fotogramas proporcionados para que encajen. Elige una tasa de fotogramas que coincida con tu entrega prevista.
Latente#
Este grupo construye un latente de video vacío y un latente de audio coincidente, luego los concatena para que el modelo muestree audio y video juntos. Es donde la guía de primer/último fotograma se inyecta primero en el paso base. Proporcionar un fotograma intermedio es opcional pero útil para estabilizar la identidad o la pose clave a mitad de toma. El resultado es un único latente AV listo para el muestreo base.
Muestreador Básico#
El paso base utiliza ruido aleatorio, un programador y el guía configurado para resolver tu prompt en un latente AV coherente. El guía recibe condicionamiento positivo y negativo además de cualquier modelo modificado por LoRA. Después del muestreo, el latente se divide de nuevo en video y audio para que el video pueda escalarse mientras el audio se mantiene alineado. Esta etapa establece el movimiento global, el ritmo y el ritmo de audio que el paso de escalado refinará.
Escalado#
El escalador eleva el latente a una resolución espacial más alta antes de un segundo paso de muestreo. El control de primer/último fotograma se vuelve a aplicar en esta resolución más alta para bloquear los fotogramas de apertura y cierre con precisión. También puedes alimentar un fotograma intermedio aquí para mantener las características estables durante el escalado. El resultado es un latente AV más nítido que preserva el movimiento planeado.
Modelo#
Este grupo Modelo carga el escalador latente LTX-2 utilizado por el grupo de Escalado. Prepara el modelo espacial específico x2 y lo expone al nodo de escalado latente. Cambia modelos aquí si mantienes múltiples escaladores. Deja este grupo sin tocar si estás satisfecho con el comportamiento predeterminado x2.
Muestreo de Escalado (2x)#
El segundo paso realiza un muestreo guiado en el latente escalado usando un muestreador separado y un calendario sigma. Una guía consciente de recorte alinea el condicionamiento a la nueva resolución para que los detalles se mantengan consistentes. La salida se divide en video y audio nuevamente para decodificación. Este paso principalmente agudiza bordes, mejora texto pequeño o texturas, y mantiene la coincidencia del primer/último fotograma.
LTX-2-19b-IC-LoRA-Detailer#
Este grupo aplica un LoRA orientado al detalle afinado para la vía de condicionamiento de imagen de LTX-2. Habilítalo cuando desees más micro-detalle o texturas más ajustadas después de condicionarte en imágenes reales. Mantén la fuerza moderada para evitar sobrepasar tu prompt o restricciones de fotograma. Si tus entradas ya son nítidas y bien iluminadas, puedes omitir este LoRA.
Control de Cámara-Dolly-In#
Usa este LoRA cuando la cámara deba avanzar hacia el sujeto a lo largo del tiempo. Inclina el modelo hacia el movimiento hacia adelante mientras respeta los objetivos de primer/último. Combínalo con indicaciones textuales que describan el movimiento para el efecto más fuerte. Reduce la fuerza si el movimiento excede el encuadre que deseas.
Control de Cámara-Dolly-Out#
Selecciona esto cuando la toma deba alejarse del sujeto. Ayuda a crear paralaje negativo y contexto ampliado a medida que avanza la secuencia. Mantén el último fotograma alineado con tu composición de salida para aterrizar el movimiento limpiamente. Combina con prompts de audio atmosférico para revelaciones cinematográficas.
Control de Cámara-Dolly-Left#
Aplica un movimiento lateral hacia la izquierda que se lee como un dolly o truck. Bueno para ritmos conversacionales o revelaciones a través de un set. Si los objetos se difuminan o se desplazan, aumenta ligeramente la fuerza de primer/último o agrega un fotograma intermedio. Equilibra con pequeñas indicaciones textuales como "movimiento lento hacia la izquierda" para complementar el LoRA.
Control de Cámara-Dolly-Right#
El espejo de Dolly-Left, esto inclina el movimiento hacia el lado derecho. Funciona bien para seguir a un personaje o hacer un paneo hacia un nuevo sujeto. Mantén la fuerza de LoRA modesta si también solicitas un avance para evitar señales contradictorias. Asegúrate de que la composición del último fotograma coincida con tu punto de llegada deseado.
Control de Cámara-Jib-Up#
Crea un ascenso vertical, útil para revelaciones elevadas o tomas de establecimiento. Combina con prompts superficiales sobre cambio de perspectiva y cambio de horizonte para mayor claridad. Cuando el movimiento es fuerte, observa techos o exposición al cielo; ajusta el prompt negativo para evitar reflejos excesivos. Si es necesario, agrega un fotograma intermedio que muestre el encuadre a mitad de ascenso.
Control de Cámara-Jib-Down#
Produce un descenso controlado, a menudo utilizado para centrarse en un detalle o personaje. Puede combinarse con una cama de audio más tranquila para mayor énfasis. Asegúrate de que el último fotograma contenga el objeto o rostro objetivo para que el movimiento se resuelva de manera decisiva. Ajusta la fuerza de LoRA si el descenso se siente demasiado rápido.
Control de Cámara-Static#
Bloquea la cámara virtual en su lugar cuando deseas acción sin movimiento de cámara. Esto es útil para tomas de diálogo o producto donde solo el sujeto se mueve. Combina con control de primer/último fotograma para mantener la composición perfectamente estable. Agrega movimiento sutil a través del prompt de texto en lugar de un LoRA de cámara.
Nodos clave en el flujo de trabajo LTX-2 Primer Último Fotograma de ComfyUI#
LTXVFirstLastFrameControl_TTP (#227)#
Inyecta restricciones de imagen de primer y último en el latente AV base. Ajusta first_strength para controlar qué tan estrictamente se iguala el primer fotograma y last_strength para determinar qué tan fuerte aterriza la secuencia en el fotograma final. Si el medio del clip se desplaza, proporciona un fotograma intermedio a través de LTXVMiddleFrame_TTP y mantén las fuerzas moderadas para evitar sobre-restringir el movimiento.
LTXVMiddleFrame_TTP (#181)#
Opcionalmente inserta un fotograma guía en una posición elegida entre el inicio y el final para estabilizar la identidad o la pose. Aumenta strength cuando el sujeto cambia demasiado a mitad de toma. Úsalo con moderación; los mejores resultados provienen de una única referencia intermedia bien elegida en lugar de muchas restricciones competitivas.
LTXVLatentUpsampler (#217)#
Realiza el escalado espacial x2 en el espacio latente usando el escalador espacial LTX-2. Usa esto antes del paso de muestreo 2x para que los detalles de mayor resolución sean refinados por el modelo en lugar de estirados. Si la memoria es ajustada, mantén el uso de LoRA al mínimo durante esta etapa.
LTXVFirstLastFrameControl_TTP (#223)#
Re-aplica la guía de inicio/fin (y opcionalmente intermedia) después del escalado x2. Esto asegura que los fotogramas decodificados finales coincidan con tus referencias de inicio y fin con precisión a la resolución de entrega. Si el escalado introduce micro desplazamientos, aumenta ligeramente last_strength aquí en lugar de en la etapa base.
LTXVSpatioTemporalTiledVAEDecode (#230)#
Decodifica el latente de video de alta resolución a fotogramas usando mosaico espaciotemporal. Ajusta la configuración de mosaico y superposición solo cuando veas costuras o parpadeo temporal; una superposición más grande cuesta más VRAM pero mejora la consistencia. Mantén last_frame_fix para casos extremos donde el fotograma final muestra un pequeño desplazamiento.
VHS_VideoCombine (#254)#
Mezcla fotogramas decodificados y el audio generado en un solo MP4. Configura el format, pix_fmt y crf para tu objetivo de entrega, y elige una frame_rate consistente con el condicionamiento. Habilita el guardado de metadatos para mantener registros de reproducibilidad con cada render.
Extras opcionales#
- Usa pesos FP8 de LTX-2 si tu GPU es limitada; vuelve a la precisión completa para la mayor fidelidad cuando la VRAM lo permita. Los pesos están en Lightricks/LTX-2.
- Las dimensiones funcionan mejor cuando el ancho y la altura son de la forma 32n + 1; el total de fotogramas funciona mejor como 8n + 1. El flujo de trabajo corrige automáticamente a los valores válidos más cercanos si es necesario.
- Describe las señales de audio directamente en tu prompt positivo (diálogo, efectos, ambiente). El latente AV conjunto del modelo mantiene labios, acciones y sonidos alineados.
- Comienza con fuerzas de primer/último moderadas; aumenta la fuerza del último para clavar la pose final, o agrega un fotograma intermedio para estabilizar la identidad.
- Aplica solo un LoRA de cámara a la vez para una intención clara. Navega por las opciones oficiales en la colección Lightricks LTX-2 LoRA.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos enormemente a @AIKSK por la Referencia de Flujo de Trabajo LTX-2 Primer Último Fotograma por sus contribuciones y mantenimiento. Para obtener detalles autorizados, consulte la documentación original y los repositorios vinculados a continuación.
Recursos#
- RunningHub/LTX-2 Primer Último Fotograma Referencia de Flujo de Trabajo
- Documentos / Notas de Lanzamiento: LTX-2 Primer Último Fotograma Referencia de Flujo de Trabajo de AIKSK
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.