
LTX-2 ComfyUI: texto, imagen, profundidad y pose a video en tiempo real con audio sincronizado#
Este flujo de trabajo todo en uno de LTX-2 ComfyUI te permite generar e iterar sobre videos cortos con audio en segundos. Viene con rutas para texto a video (T2V), imagen a video (I2V), profundidad a video, pose a video y canny a video, por lo que puedes comenzar desde un prompt, una imagen fija o una guía estructurada y mantener el mismo ciclo creativo.
Construido alrededor del pipeline AV de baja latencia de LTX-2 y el paralelismo de secuencias multi-GPU, el gráfico enfatiza la retroalimentación rápida. Describe el movimiento, la cámara, el aspecto y el sonido una vez, luego ajusta el ancho, la altura, el conteo de cuadros o controla las LoRAs para refinar el resultado sin volver a cablear nada.
Nota: Nota sobre la compatibilidad del flujo de trabajo LTX-2 — LTX-2 incluye 5 flujos de trabajo: Texto a Video e Imagen a Video funcionan en todos los tipos de máquina, mientras que Profundidad a Video, Canny a Video y Pose a Video requieren una máquina 2X-Large o más grande; ejecutar estos flujos de trabajo ControlNet en máquinas más pequeñas puede resultar en errores.
Modelos clave en el flujo de trabajo LTX-2 ComfyUI#
- LTX-2 19B (dev FP8) checkpoint. Modelo generativo audiovisual central que produce cuadros de video y audio sincronizado desde condicionamiento multimodal. Lightricks/LTX-2
- LTX-2 19B Distilled checkpoint. Variante más ligera y rápida útil para borradores rápidos o ejecuciones controladas por canny. Lightricks/LTX-2
- Gemma 3 12B IT codificador de texto. Base principal de comprensión de texto utilizada por los codificadores de prompt del flujo de trabajo. Comfy-Org/ltx-2 split files
- LTX-2 Spatial Upscaler x2. Supermuestreador latente que duplica el detalle espacial a mitad del gráfico para obtener salidas más limpias. Lightricks/LTX-2
- LTX-2 Audio VAE. Codifica y decodifica latentes de audio para que el sonido pueda generarse y mezclarse junto al video. Incluido con la versión LTX-2 anterior.
- Lotus Depth D v1‑1. UNet de profundidad utilizado para derivar mapas de profundidad robustos a partir de imágenes antes de la generación de video guiada por profundidad. Comfy‑Org/lotus
- SD VAE (MSE, EMA pruned). VAE utilizado en la rama del preprocesador de profundidad. stabilityai/sd-vae-ft-mse-original
- Control LoRAs para LTX‑2. LoRAs opcionales, plug-and-play, para dirigir el movimiento y la estructura:
Cómo usar el flujo de trabajo LTX-2 ComfyUI#
El gráfico contiene cinco rutas que puedes ejecutar de forma independiente. Todas las rutas comparten el mismo camino de exportación y utilizan la misma lógica de prompt a condicionamiento, por lo que una vez que aprendes una, las demás te resultan familiares.
T2V: genera video y audio desde un prompt#
La ruta T2V comienza con CLIP Text Encode (Prompt) (#3) y un negativo opcional en CLIP Text Encode (Prompt) (#4). LTXVConditioning (#22) une tu texto y la tasa de cuadros elegida al modelo. EmptyLTXVLatentVideo (#43) y LTX LTXV Empty Latent Audio (#26) crean latentes de video y audio que son fusionados por LTX LTXV Concat AV Latent (#28). El bucle de desruido se ejecuta a través de LTXVScheduler (#9) y SamplerCustomAdvanced (#41), después de lo cual VAE Decode (#12) y LTX LTXV Audio VAE Decode (#14) producen cuadros y audio. Video Combine 🎥🅥🅗🅢 (#15) guarda un MP4 H.264 con sonido sincronizado.
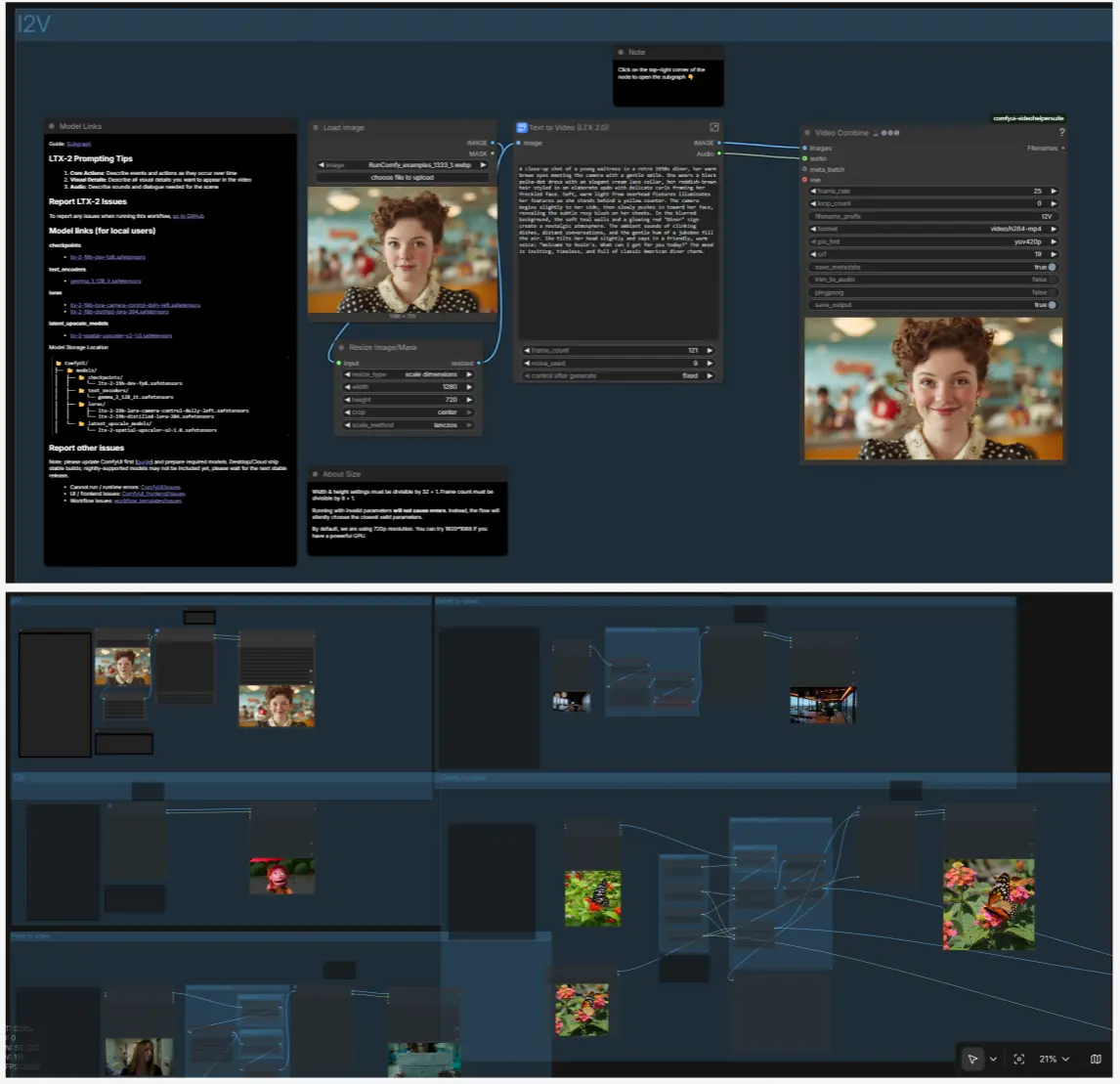
I2V: anima una imagen fija#
Carga una imagen fija con LoadImage (#98) y redimensiona con ResizeImageMaskNode (#99). Dentro del subgráfico T2V, LTX LTXV Img To Video Inplace inyecta el primer cuadro en la secuencia latente para que el movimiento se construya desde tu imagen fija en lugar de ruido puro. Mantén tu prompt textual enfocado en movimiento, cámara y ambiente; el contenido proviene de la imagen.
Profundidad a video: movimiento consciente de la estructura a partir de mapas de profundidad#
Usa el preprocesador “Image to Depth Map (Lotus)” para transformar una entrada en una imagen de profundidad, decodificada por VAEDecode y opcionalmente invertida para la polaridad correcta. La ruta “Depth to Video (LTX 2.0)” luego alimenta la guía de profundidad a través de LTX LTXV Add Guide para que el modelo respete la estructura global de la escena mientras se anima. La ruta reutiliza las mismas etapas de programador, muestreador y supermuestreador, y termina con decodificación en mosaico a imágenes y audio mezclado para exportar.
Pose a video: impulsa el movimiento desde la pose humana#
Importa un clip con VHS_LoadVideo (#198); DWPreprocessor (#158) estima la pose humana de manera confiable a través de los cuadros. El subgráfico “Pose to Video (LTX 2.0)” combina tu prompt, el condicionamiento de pose y un LoRA de Control de Pose opcional para mantener coherentes las extremidades, la orientación y los ritmos mientras permite que el estilo y el fondo fluyan desde el texto. Usa esto para danza, acrobacias simples o tomas de hablar a cámara donde el tiempo corporal es importante.
Canny a video: animación fiel a los bordes y modo de velocidad destilada#
Alimenta cuadros a Canny (#169) para obtener un mapa de bordes estable. La rama “Canny to Video (LTX 2.0)” acepta los bordes más un LoRA de Control Canny opcional para alta fidelidad a las siluetas, mientras que “Canny to Video (LTX 2.0 Distilled)” ofrece un checkpoint destilado más rápido para iteraciones rápidas. Ambas variantes te permiten inyectar opcionalmente el primer cuadro y elegir la fuerza de la imagen, luego exportar ya sea a través de CreateVideo o VHS_VideoCombine.
Configuración de video y exportación#
Establece el ancho y la altura a través de Width (#175) y height (#173), los cuadros totales con Frame Count (#176), y activa Enable First Frame (#177) si deseas bloquear una referencia inicial. Usa los nodos VHS_VideoCombine al final de cada ruta para controlar crf, frame_rate, pix_fmt, y el guardado de metadatos. Se proporciona un SaveVideo (#180) dedicado para la ruta canny destilada cuando prefieres salida de VIDEO directa.
Rendimiento y multi-GPU#
El gráfico aplica LTXVSequenceParallelMultiGPUPatcher (#44) con torch_compile habilitado para dividir secuencias entre GPUs para menor latencia. KSamplerSelect (#8) te permite elegir entre muestreadores, incluidos estilos de estimación de gradiente y Euler; conteos de cuadros más pequeños y pasos más bajos reducen el tiempo de respuesta para que puedas iterar rápidamente y escalar cuando estés satisfecho.
Nodos clave en el flujo de trabajo LTX-2 ComfyUI#
LTX Multimodal Guider(#17). Coordina cómo el condicionamiento de texto dirige las ramas de video y audio. Ajustacfgymodalityen losLTX Guider Parametersvinculados (#18 para VIDEO, #19 para AUDIO) para equilibrar fidelidad vs creatividad; aumentacfgpara una mayor adherencia al prompt y aumentamodality_scalepara enfatizar una rama específica.LTXVScheduler(#9). Construye un programa de sigma adaptado al espacio latente de LTX‑2. Usastepspara intercambiar velocidad por calidad; al prototipar, menos pasos reducen la latencia, luego aumenta los pasos para renders finales.SamplerCustomAdvanced(#41). El desruido que uneRandomNoise, el muestreador elegido deKSamplerSelect(#8), las sigmas del programador, y el latente AV. Cambia muestreadores para diferentes texturas de movimiento y comportamiento de convergencia.LTX LTXV Img To Video Inplace(ver ramas I2V, por ejemplo, #107). Inyecta una imagen en un latente de video para que el primer cuadro ancle el contenido mientras el modelo sintetiza el movimiento. Ajustastrengthpara cuán estrictamente se preserva el primer cuadro.LTX LTXV Add Guide(en rutas guiadas, por ejemplo, profundidad/pose/canny). Añade una guía estructural (imagen, pose, o bordes) directamente en el espacio latente. Usastrengthpara equilibrar la fidelidad de la guía con la libertad generativa y habilita el primer cuadro solo cuando deseas anclaje temporal.Video Combine 🎥🅥🅗🅢(#15 y sus similares). Empaqueta cuadros decodificados y el audio generado en MP4. Para vistas previas, aumentacrf(más compresión); para finales, bajacrfy confirma queframe_ratecoincide con lo que configuraste en el condicionamiento.LTXVSequenceParallelMultiGPUPatcher(#44). Habilita la inferencia en secuencia paralela con optimizaciones de compilación. Déjalo activado para mejor rendimiento; desactívalo solo al depurar la colocación de dispositivos.
Extras opcionales#
- Consejos de prompting para LTX-2 ComfyUI
- Describe acciones principales a lo largo del tiempo, no solo la apariencia estática.
- Especifica detalles visuales importantes que debes ver en el video.
- Escribe la banda sonora: ambiente, efectos de sonido, música y cualquier diálogo.
- Reglas de tamaño y tasa de cuadros
- Usa ancho y altura que sean múltiplos de 32 (por ejemplo, 1280×720).
- Usa conteos de cuadros que sean múltiplos de 8 (121 en este template es una buena longitud).
- Mantén la tasa de cuadros consistente donde aparezca; el gráfico incluye tanto cajas de float como de int y deben coincidir.
- Guía LoRA
- Las LoRAs de cámara, profundidad, pose y canny están integradas; comienza con fuerza 1 para movimientos de cámara, luego agrega una segunda LoRA solo cuando sea necesario. Navega por la colección oficial en Lightricks/LTX‑2.
- Iteraciones más rápidas
- Reduce el conteo de cuadros, reduce pasos en
LTXVScheduler, y prueba el checkpoint destilado para la ruta canny. Cuando el movimiento funcione, escala la resolución y los pasos para los finales.
- Reduce el conteo de cuadros, reduce pasos en
- Reproducibilidad
- Bloquea
noise_seeden los nodos de Ruido Aleatorio para obtener resultados repetibles mientras ajustas prompts, tamaños y LoRAs.
- Bloquea
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Lightricks por el modelo de generación de video multimodal LTX-2 y el código base de investigación LTX-Video, y a Comfy Org por los nodos/integración socios de ComfyUI LTX-2, por sus contribuciones y mantenimiento. Para detalles autoritativos, consulta la documentación y repositorios originales vinculados a continuación.
Recursos#
- Comfy Org/LTX-2 ¡Ahora Disponible en ComfyUI!
- GitHub: Lightricks/LTX-Video
- Hugging Face: Lightricks/LTX-Video-ICLoRA-detailer-13b-0.9.8
- arXiv: 2501.00103
- Docs / Notas de Lanzamiento: LTX-2 Ahora Disponible en ComfyUI!
Nota: El uso de los modelos, conjuntos de datos y códigos referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.
