
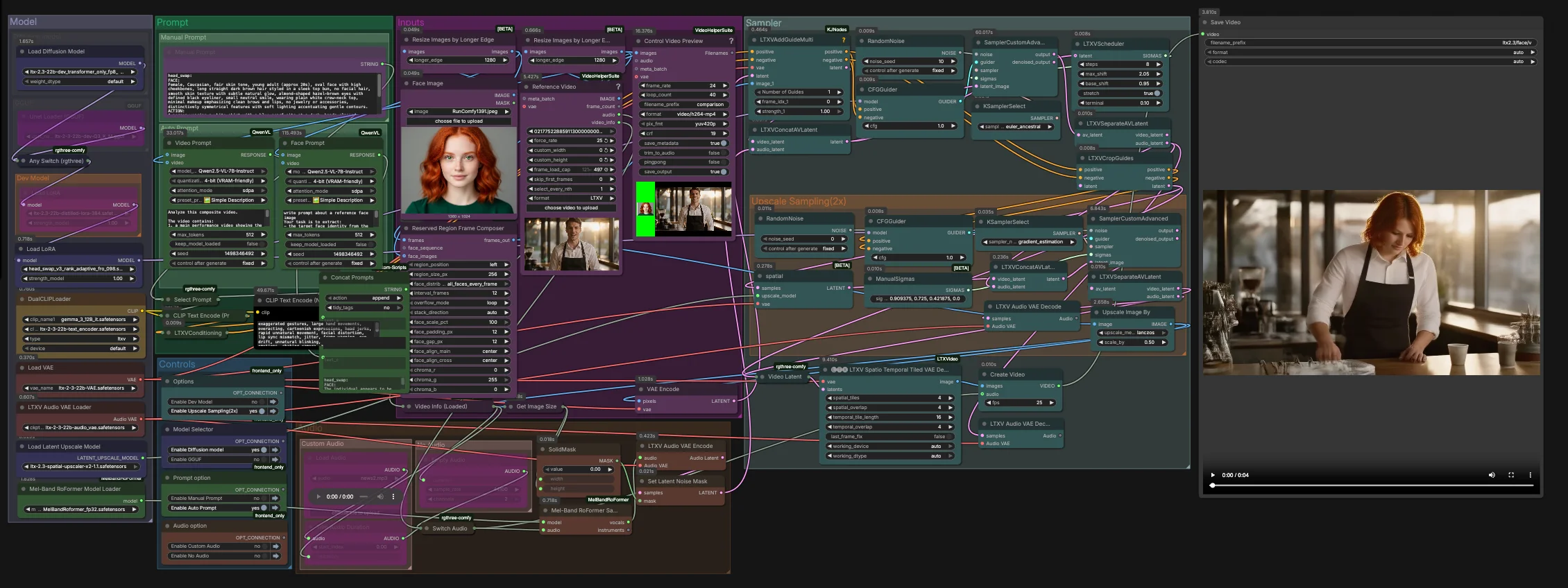
LTX-2.3-Video-Face-Swap para ComfyUI#
Este flujo de trabajo ofrece un reemplazo facial en video de alta fidelidad y estable en el tiempo utilizando la familia LTX 2.3. Diseñado para RunComfy y ComfyUI, fusiona una imagen guía de identidad con un video objetivo y orientación de audio opcional para preservar expresiones, iluminación y movimiento a través de los fotogramas. El resultado es un intercambio realista y resistente al parpadeo que se mantiene en primeros planos y tomas medias.
Los creadores, artistas de VFX y cineastas de IA pueden usar LTX-2.3-Video-Face-Swap para mantener el control creativo total: "prompt" manual o generación de "prompts" estructurados a partir de las entradas, elegir entre variantes dev, distilled, FP8, o GGUF, y finalizar con una decodificación espaciotemporal y una ampliación latente 2x opcional para detalles nítidos.
Modelos clave en el flujo de trabajo Comfyui LTX-2.3-Video-Face-Swap#
- LTX 2.3 22B Video Diffusion Transformer. Modelo principal de generación y edición de video que impulsa la preservación de identidad y la coherencia temporal. Ver la familia de modelos oficial en Lightricks/LTX-2.3.
- LTX 2.3 Text Encoders. El gráfico empareja el codificador de texto LTX 2.3 con un codificador de instrucciones Gemma 3 12B para mejorar la alineación de "prompts" para la edición de video. Ejemplo de artefactos: ltx-2-3-22b-text_encoder.safetensors y gemma_3_12B_it.safetensors.
- LTX 2.3 VAE y Audio VAE. Codificadores/decodificadores utilizados para comprimir y reconstruir fotogramas visuales y pistas de audio mientras se preserva el detalle y la sincronización. Ver Lightricks/LTX-2.3 VAE files y variantes de audio VAE en el repositorio dividido vantagewithai/LTX-2.3-Split.
- LTX 2.3 Spatial Upscaler x2. Ampliador espacial latente 2x que aumenta la fidelidad espacial antes de la decodificación final, ideal para detalles faciales. ltx-2.3-spatial-upscaler-x2-1.1.safetensors.
- Head‑swap LoRA. Una LoRA adaptativa de rango especializada en la transferencia de identidad que mejora la semejanza y la estabilidad al realizar la edición. Ejemplo: head_swap_v3_rank_adaptive_fro_098.safetensors.
- MelBandRoFormer. Modelo opcional de separación de fuentes musicales utilizado aquí para aislar las voces para una orientación más fuerte del movimiento de la boca. Kijai/MelBandRoFormer_comfy.
- Variantes de implementación opcionales. Pesos solo de transformador FP8 para velocidad en GPUs compatibles Kijai/LTX2.3_comfy y construcciones ligeras de UNet GGUF para escenarios de CPU o bajo VRAM vantagewithai/LTX-2.3-GGUF.
Cómo usar el flujo de trabajo Comfyui LTX-2.3-Video-Face-Swap#
Este gráfico se ejecuta en dos etapas. La primera etapa realiza el intercambio principal en la resolución latente nativa con orientación consciente del audio. La segunda etapa amplía en el espacio latente y refina la región facial antes de una decodificación espaciotemporal y el multiplexado final a video.
Entradas#
- Carga tu imagen de identidad en
Face Image(LoadImage(#255)). Usa una toma bien iluminada, frontal o de tres cuartos para la extracción de identidad más confiable. - Carga el metraje objetivo en
Reference Video(VHS_LoadVideo(#393)). Los fotogramas se normalizan y previsualizan a través deResizeImagesByLongerEdgeyControl Video Preview(VHS_VideoCombine(#396)) para revisiones rápidas antes del muestreo. - El
ReservedRegionFrameComposer(#395) prepara fotogramas guía que alinean la imagen facial con el diseño de la escena, ayudando al modelo a centrarse en el área de intercambio durante el condicionamiento.
Prompt#
- Puedes describir el aspecto y la acción deseados manualmente en
Manual Prompto dejar que el gráfico componga automáticamente un "prompt" estructurado.Video Prompt(AILab_QwenVL(#400)) extrae el movimiento corporal y la escena del video mientras queFace Prompt(AILab_QwenVL(#401)) extrae detalles de identidad de la imagen facial. Concat Promptsfusiona identidad y acción en una instrucción concisa, luegoSelect Promptdirige ya sea tu texto manual o el "prompt" automático aCLIP Text Encode. El texto de "prompt" negativo se codifica por separado para suprimir artefactos comunes de video.
Modelo#
- El grupo
Modelcarga el LTX 2.3 UNet o su variante GGUF, aplica el LoRA destilado y el LoRA de intercambio de cabezas, y activa los LTX VAEs y los codificadores de texto duales. La configuración de dos codificadores mejora la alineación para el contenido hablado y el bloqueo de cámara sin restringir en exceso la identidad. - Si estás optimizando para velocidad o memoria, cambia entre dev, destilado, solo transformador FP8 o GGUF en el selector de modelos proporcionado. No se necesita configuración adicional en RunComfy.
Muestrador#
- La primera etapa combina latentes de video y audio en
LTXVConcatAVLatent(#321), luego desruida conCFGGuider(#326),LTXVScheduler(#324), ySamplerCustomAdvanced(#257). ElLTXVAddGuideMulti(#392) inyecta tu guía de identidad para que la cara se establezca temprano y permanezca estable con el tiempo. - Después de un primer paso,
LTXVSeparateAVLatent(#323) divide las corrientes para queLTXVCropGuides(#282) pueda centrar la edición alrededor de la cara. Esto concentra el cálculo donde importa y mejora la consistencia temporal.
Muestreo de Ampliación (2x)#
LTXVLatentUpsampler(#279) aplica el ampliador espacial x2 de LTX 2.3 en el espacio latente. El latente de video ampliado luego se vuelve a unir con el latente de audio enLTXVConcatAVLatent(#287) y se refina mediante un segundo paso deSamplerCustomAdvanced(#288) guiado porCFGGuider(#284).- Esta estrategia de dos etapas produce piel, ojos y cabello más nítidos mientras mantiene el intercambio bloqueado a la identidad deseada.
Audio#
- El grupo
Audiote permite dirigir el audio original, silencio o un segmento recortado a través deSwitch Audio. Para señales de movimiento de labios más fuertes, la pista seleccionada se envía a través deMelBandRoFormerSampler(#355) para aislar voces, luego se codifica conLTXVAudioVAEEncode(#364). - Una máscara de ruido sólida (
SetLatentNoiseMask(#365)) previene cambios no deseados impulsados por audio fuera de la región de la boca mientras sigue aprovechando el tiempo del habla para guiar expresiones.
Decodificar y exportar#
- Los fotogramas finales se reconstruyen con
LTXVSpatioTemporalTiledVAEDecode(#377), que decodifica con mosaicos conscientes del tiempo para evitar costuras y mantener la continuidad del movimiento.CreateVideo(#292) multiplexa las imágenes con el audio elegido, ySaveVideoescribe el clip terminado.
Nodos clave en el flujo de trabajo Comfyui LTX-2.3-Video-Face-Swap#
LTXVAddGuideMulti(#392). Alimenta la guía facial alineada en la corriente de condicionamiento para que el modelo se fije en la identidad objetivo desde los primeros pasos. Si la semejanza se desvía en movimientos rápidos, aumenta el número o la frecuencia de los fotogramas guía en lugar de aumentar la guía globalmente.LTXVCropGuides(#282). Enfoca automáticamente la segunda pasada en la región facial derivada de los latentes y "prompts" de la primera etapa. Úsalo para ajustar el área de edición cuando los fondos o las manos compiten por atención.SamplerCustomAdvanced(#257). Paso principal de desruido que establece identidad, iluminación y movimiento grueso. Combínalo con elLTXVSchedulerpara dar forma a los pasos y mantener la elección del muestreador estable a través de experimentos para hacer comparaciones significativas.LTXVLatentUpsampler(#279). Realiza una ampliación latente 2x usando el ampliador espacial LTX antes de la refinación. Usa esto cuando necesites poros, pestañas y costuras de sombrero más nítidos sin introducir parpadeo de ampliadores de píxeles post-decodificación.SamplerCustomAdvanced(#288). Paso de refinamiento después de la ampliación. Ajusta la guía moderadamente aquí para afilar características mientras preservas la identidad establecida por el primer paso.LTXVSpatioTemporalTiledVAEDecode(#377). Decodificador consciente del tiempo que reduce costuras de mosaico a través de los fotogramas. Si alcanzas límites de VRAM en clips largos, prefiere ajustar su diseño de mosaico en lugar de bajar la resolución.MelBandRoFormerSampler(#355). Separación vocal utilizada solo para orientación. Si el audio fuente es ruidoso, cambia a audio original o silencioso para evitar propagar artefactos en el movimiento de la boca.
Extras opcionales#
- La calidad de la imagen facial importa. Usa una foto neutra, bien iluminada, de frente o de tres cuartos a una edad y expresión similar a la actuación.
- Mantén el video de referencia estable. Las tomas estáticas o con trípode producen los resultados más estables de LTX-2.3-Video-Face-Swap, especialmente en tomas medias y cercanas.
- Los "prompts" deben ser concisos. Indica la escena y la acción en un solo párrafo y reserva adjetivos de identidad para el "prompt" facial, no para el "prompt" de acción.
- La orientación de audio es opcional. El habla clara mejora las formas de la boca; las pistas solo de música proporcionan poco beneficio, así que elige silencio para enfocar el cálculo en los visuales.
- Para ejecuciones con bajo VRAM o solo CPU, prefiere la construcción GGUF de UNet; para alto rendimiento en GPUs modernas, los pesos solo de transformador FP8 son una buena opción predeterminada.
- Usa responsablemente. Obtén consentimiento para cualquier semejanza que intercambies y cumple con las leyes y políticas de plataforma aplicables.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a LTX-2.3 por el modelo LTX-2.3, y a EyeForAILabs por el tutorial de YouTube, por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- LTX-2.3/LTX-2.3 Model
- Hugging Face: Hugging Face Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.