
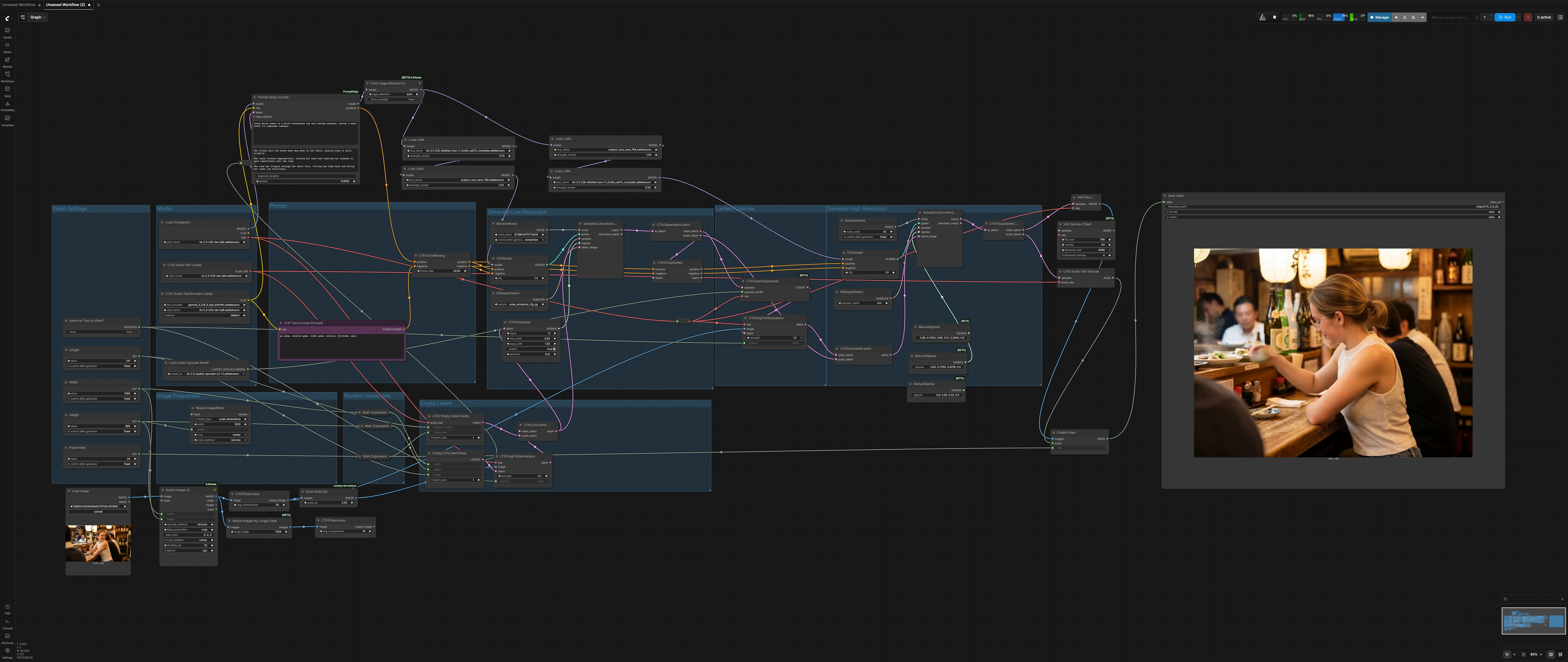
LTX 2.3 Sulphur imagen a video flujo de trabajo: imagen a video cinematográfico con movimiento controlable#
Este flujo de trabajo LTX 2.3 Sulphur imagen a video convierte una sola imagen fija en una toma cinematográfica lista para publicación con microexpresiones naturales, movimiento creíble de personajes y continuidad atmosférica estable. Está diseñado específicamente para tomas narrativas donde se desea controlar la sensación de cámara, el estado de ánimo y la dinámica de la escena sin perderse en los detalles de configuración.
El flujo de trabajo ejecuta una tubería de difusión en dos etapas alrededor de LTX-2.3: un paso de baja resolución para establecer movimiento y sincronización, seguido de una ampliación latente y un paso de refinamiento de alta resolución para el detalle final. Un LoRA de estilo Sulphur dirige el aspecto y los tonos de piel, mientras que la segmentación de prompts apoya la evolución de los beats a lo largo de la toma. Activa un solo interruptor para ejecutar imagen a video clásico o texto a video puro según sea necesario.
Modelos clave en Comfyui LTX 2.3 Sulphur imagen a video flujo de trabajo#
- Lightricks LTX-2.3-22B dev FP8. El punto de control de difusión de video base que impulsa la generación y decodificación mientras mantiene el uso de memoria práctico. Model card
- LTX-2.3 Spatial Upscaler x2. Un modelo de superresolución latente utilizado entre pasos para preservar el movimiento mientras se añade fidelidad espacial. Model page
- Gemma 3 12B encoder de texto ajustado por instrucciones empaquetado para LTX-2. Permite una rica y fundamentada condición para prompts globales y segmentados. Repository
- Estilo Sulphur LoRA y LTX-2.3 LoRA destilado 1.1. LoRAs emparejados que estabilizan el realismo facial y el tono cinematográfico mientras retienen el control de prompts.
Cómo usar Comfyui LTX 2.3 Sulphur imagen a video flujo de trabajo#
Flujo general: establece las dimensiones y la longitud de la toma, prepara tu imagen fija, define un prompt global más beats opcionales de prompts locales, luego renderiza. La etapa de baja resolución construye el movimiento y la sincronización, el ampliador latente eleva el detalle, y la etapa de alta resolución finaliza la textura y la iluminación antes de decodificar a MP4.
Configuración de Video#
Elige tu objetivo Width, Height, Length (cuadros), y Frame Rate. Las dimensiones están configuradas para ser divisibles por tamaños de cuadrícula de difusión comunes para evitar artefactos. Un solo booleano, Switch to Text to Video? (#28), controla si la imagen fija se inyecta o se omite. Mantén la relación de aspecto consistente con la imagen de entrada para el encuadre más limpio, especialmente para caras y manos.
Preprocesamiento de Imagen#
Tu imagen fija fuente se carga, redimensiona y comprime ligeramente para estar lista para la difusión usando ImageResizeKJv2 (#75) y LTXVPreprocess (#76). Una versión escalada se alimenta al paso de baja resolución para sembrar movimiento estable, mientras que la versión de mayor detalle está disponible para el paso de alta resolución. Usa esta sección para alinear el encuadre y el espacio superior antes de la generación. Ajustes sutiles de pre-recorte aquí rinden más líneas de ojos consistentes y continuidad de fondo.
Latente Vacío#
EmptyLTXVLatentVideo (#21) y LTXVEmptyLatentAudio (#33) construyen latentes de video y audio sincronizados utilizando tus configuraciones de toma. Se fusionan mediante LTXVConcatAVLatent (#32) para establecer un esqueleto de línea de tiempo que los nodos posteriores refinarán. La rama de audio crea una pista silenciosa y válida para que el MP4 final se reproduzca de manera confiable en todas partes. Estos latentes también anclan segmentos de prompts para que los cambios de movimiento aterricen donde esperas.
Prompt#
Escribe la descripción de tu toma en PromptRelayEncode (#80). Usa un prompt global conciso para el aspecto general, luego agrega líneas específicas de beats como prompts locales, separadas por el carácter |, para evolucionar microacciones a lo largo del clip. El encoder de texto LTX de LTXAVTextEncoderLoader (#5) maneja la semántica, mientras que CLIPTextEncode (#41) proporciona un fuerte prompt negativo orientado al realismo. LTXVConditioning (#31) mezcla la condición positiva y negativa y las sincroniza con la tasa de cuadros.
Modelo#
CheckpointLoaderSimple (#44) carga la base LTX-2.3. PathchSageAttentionKJ (#67) optimiza la atención para imágenes grandes. Una breve cadena de LoRA aplica el estilo Sulphur y una estabilidad destilada de LoRA antes de cada etapa de muestreo. Este diseño equilibra la consistencia del aspecto con la capacidad de respuesta del prompt para que la identidad del personaje y la iluminación se mantengan coherentes entre los pasos.
Generar Baja Resolución#
Este primer paso de difusión establece el movimiento. LTXVImgToVideoInplace (#22) inyecta tu imagen fija preprocesada en la línea de tiempo; si Switch to Text to Video? está habilitado, su entrada bypass desactiva limpiamente la inyección de imagen para T2V puro. LTXVScheduler (#47) forma el cronograma sigma para controlar la amplitud del movimiento y la suavidad temporal. SamplerCustomAdvanced (#9), impulsado por CFGGuider (#42) y KSamplerSelect (#17), sintetiza un latente A/V coherente de baja resolución. LTXVSeparateAVLatent (#35) luego divide las rutas de video y audio y reenvía la información de encuadre a LTXVCropGuides (#10) para una composición consciente de la guía.
Ampliación Latente#
LTXVLatentUpsampler (#13) con el LTX-2.3 Spatial Upscaler eleva el detalle espacial en el espacio latente mientras preserva el movimiento aprendido del primer paso. La ampliación aquí evita reinventar la sincronización y reduce el parpadeo que a menudo se ve con la regeneración ingenua de un segundo paso. Entrega un latente más nítido y consistente en movimiento a la etapa de refinamiento final.
Generar Alta Resolución#
La etapa refinada recombina el latente de video ampliado y el latente de audio a través de LTXVConcatAVLatent (#3). CFGGuider (#8) y KSamplerSelect (#6) dirigen un muestreador rápido y orientado a los detalles en SamplerCustomAdvanced (#36) usando un cronograma sigma ajustado para el acabado. Si dejaste habilitada la inyección de imagen, un segundo LTXVImgToVideoInplace (#14) ayuda al modelo a respetar la imagen fija en alta resolución sin perder el movimiento ya establecido. El resultado es una secuencia cinematográfica estable con dinámicas naturales de ojos y boca.
Salida#
VAEDecode (#68) convierte el latente de video final en cuadros mientras que LTXVAudioVAEDecode (#23) reconstruye la pista de audio silenciosa. CreateVideo (#38) mezcla cuadros y audio a tu tasa de cuadros seleccionada, y SaveVideo (#45) escribe un MP4 H.264 para revisión y compartición inmediata. Usa un prefijo de nombre de archivo descriptivo por toma para mantener las iteraciones organizadas.
Conversión de número#
Un pequeño bloque de utilidad calcula tamaños a media escala para la construcción latente para gestionar VRAM y velocidad. Normalmente no necesitas tocar estos, pero aseguran que el ancho y la altura ascendentes impulsen todo de manera consistente. Si cambias la resolución base, estos se adaptan automáticamente.
Nodos clave en Comfyui LTX 2.3 Sulphur imagen a video flujo de trabajo#
PromptRelayEncode(#80). Centraliza un prompt global y prompts locales alineados con el cronograma. Úsalo para guiar microexpresiones y pequeñas revelaciones de cámara a lo largo de la toma. Mantén los prompts locales cortos y específicos para que complementen en lugar de luchar contra el aspecto global.LTXVImgToVideoInplace(#22, #14). Inyecta la imagen fija en latentes de baja y alta resolución. Aumentastrengthcuando deseas que el final se adhiera firmemente al cuadro de referencia; redúcelo para más libertad. La entradabypassestá conectada al interruptor de Texto a Video para que puedas desactivar la inyección de imagen limpiamente para ejecuciones de T2V.LTXVScheduler(#47). Controla cómo evolucionan los niveles de ruido durante el paso de baja resolución, lo que afecta directamente la intensidad del movimiento y la suavidad. Úsalo para domar tomas demasiado activas o para añadir un empuje sutil cuando las cosas se sienten estáticas. Los ajustes aquí son más notorios en caras, cabello y energía de cámara tipo handheld.LTXVLatentUpsampler(#13). Realiza una ampliación latente x2 con el ampliador espacial de LTX, preservando las señales de movimiento aprendidas en el primer paso. Úsalo para añadir textura nítida y definición de bordes antes del refinamiento de alta resolución sin re-rodar la sincronización.CFGGuider(#42, #8). Equilibra cuán fuertemente el modelo sigue tus prompts frente a sus priors aprendidos. Si las caras se desvían o el estilo se debilita, aumenta la guía; si los detalles se ven forzados o plásticos, disminúyela. Empareja los cambios con una revisión rápida del prompt negativo para mantener el realismo.KSamplerSelect(#17, #6). Te permite elegir el algoritmo de muestreo por etapa. Favorece un muestreador robusto y expresivo para el paso de baja resolución y una opción rápida y amigable con los detalles para el paso de acabado. Mantén la elección consistente a través de iteraciones al comparar aspectos.
Extras opcionales#
- Para un comportamiento de cámara deliberado, puedes añadir un LoRA de control de cámara como Dolly-Left de la familia LTX a tu cadena de cargadores de LoRA cuando quieras un empuje lateral consistente. Model page
- Mantén el ancho y la altura divisibles por 32 para evitar desalineaciones en las operaciones latentes y mantener la eficiencia de VRAM.
- Usa verbos cortos y activos en prompts locales para coreografiar beats, por ejemplo, aprieta el agarre, desvía la mirada, suaviza la sonrisa.
- Si apuntas a tamaños de salida muy altos, considera cambiar
VAEDecodeporVAEDecodeTiled(#43) para decodificar cuadros de manera más eficiente en memoria. - Cuando las caras son lo más importante, itera ajustando solo el texto del prompt y
CFGGuiderantes de cambiar el muestreador o la resolución. Esto mantiene las comparaciones significativas y resalta la mejor redacción para el flujo de trabajo LTX 2.3 Sulphur imagen a video.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a RunningHub por la referencia del flujo de trabajo, a Lightricks por la familia LTX 2.3 (modelo, ampliador espacial y LoRA de control de cámara), y a Comfy-Org por el encoder de texto LTX por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación y repositorios originales enlazados a continuación.
Recursos#
- Referencia de flujo de trabajo RunningHub/RunningHub
- Documentos / Notas de lanzamiento: runninghub.ai post
- Fuente del modelo Lightricks/LTX 2.3
- Hugging Face: Lightricks/LTX-2.3-fp8
- Fuente del ampliador espacial Lightricks/LTX 2.3
- Hugging Face: Lightricks/LTX-2.3
- Fuente del LoRA de control de cámara Lightricks/LTX
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Fuente del encoder de texto Comfy-Org/LTX
- Hugging Face: Comfy-Org/ltx-2
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.
