
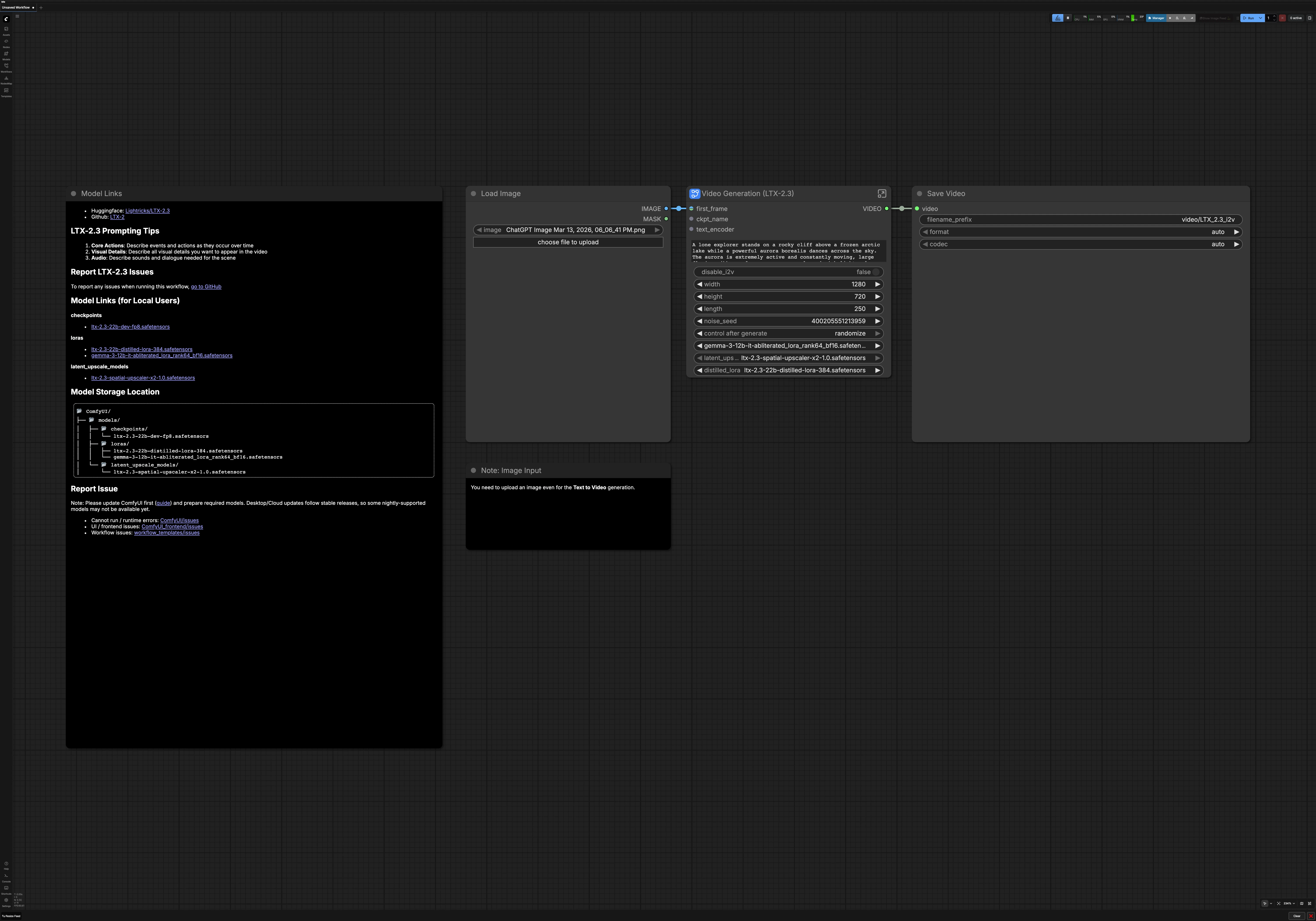
LTX 2.3 Imagen a Video para ComfyUI#
Este flujo de trabajo convierte una sola imagen o un texto puro en video cinematográfico y fluido con LTX 2.3 Imagen a Video. Está diseñado para creadores que buscan alta coherencia visual, fuerte consistencia de escena y movimiento pulido sin cableado manual. Úsalo en RunComfy o cualquier entorno de ComfyUI para generar resultados dinámicos y estilizados que se mantengan fieles a tu prompt.
El gráfico admite dos modos creativos: imagen a video con tu primer cuadro como ancla visual, o texto a video guiado completamente por lenguaje. También incluye mejora automática de prompt, escalado latente para mayor detalle, y decodificación de audio opcional para que tu renderizado final de LTX 2.3 Imagen a Video esté listo para publicarse.
Modelos clave en el flujo de trabajo LTX 2.3 Imagen a Video de ComfyUI#
- Lightricks LTX 2.3 22B modelo de video. El núcleo del transformador de difusión de video que sintetiza movimiento y visuales temporalmente consistentes a partir de texto y guía de imagen opcional. Los archivos del modelo y la documentación están disponibles en Hugging Face y referencias a nivel de código en GitHub.
- LTX Audio VAE. El codificador auto-regresivo variacional de audio utilizado para decodificar el latente de audio del modelo en una pista de audio para mezclar con los cuadros. Distribuido con la versión LTX 2.3 en Hugging Face.
- LTX 2.3 Spatial Upscaler x2. Un modelo de superresolución en espacio latente que mejora la nitidez y la fidelidad espacial antes del paso final de muestreo de alta resolución. Disponible en el repositorio LTX 2.3 en Hugging Face.
- Gemma 3 12B Instruct codificador de texto más LoRA. Un codificador de texto compacto ajustado por instrucciones y LoRA utilizado aquí para mejorar la comprensión y redacción de prompts para video. El codificador empaquetado y los pesos LoRA utilizados por esta plantilla se proporcionan en los activos LTX-2 de Comfy-Org en Hugging Face.
Cómo usar el flujo de trabajo LTX 2.3 Imagen a Video de ComfyUI#
A un nivel alto, tu prompt y el primer cuadro opcional se codifican, se muestrea un video latente de baja resolución, luego se escala en espacio latente y se refina a mayor resolución. El resultado se decodifica en cuadros y audio, luego se compone en un MP4 final. Puedes cambiar entre imagen a video y texto a video en cualquier momento antes de ejecutar.
- Modelo
- Este grupo carga el punto de control LTX 2.3, el VAE de audio, y el codificador de texto. También aplica el LTX 2.3 LoRA al modelo base para mejorar el seguimiento de instrucciones. Juntos definen la base sobre la que se construye el resto de la canalización LTX 2.3 Imagen a Video. Normalmente no cambiarás nada aquí a menos que intercambies variantes de modelo o estilos de LoRA.
- Prompt
- Introduce la descripción de tu escena y negativos opcionales. El texto se codifica tanto para el acondicionamiento positivo como negativo y se empareja con tu tasa de cuadros seleccionada para que la planificación del movimiento se alinee con el tiempo. Mantén el lenguaje consciente del tiempo con verbos que describan cambios, por ejemplo, "la cámara avanza" o "las hojas giran en el viento". Los prompts negativos ayudan a evitar artefactos no deseados como marcas de agua o simplificaciones caricaturescas.
- Mejora de Prompt
- El gráfico incluye un asistente que analiza tu imagen y texto, luego genera un borrador de prompt más fuerte y consciente del tiempo que puedes adoptar o editar. Esto facilita guiar a LTX 2.3 Imagen a Video hacia descripciones cinematográficas y orientadas a la acción. Es especialmente útil cuando comienzas desde una sola imagen fija y deseas un movimiento que se sienta intencional. El nodo de vista previa te permite inspeccionar el texto mejorado antes de la generación.
- Configuración de Video
- Elige si ejecutar imagen a video o cambiar a texto a video con un simple interruptor. Establece ancho, alto, duración y tasa de cuadros para que se adapten a tu plataforma objetivo. Estas configuraciones impulsan la asignación latente y la decodificación posterior, así que mantenlas sincronizadas con tu intención creativa. Si planeas publicar ampliamente, favorece dimensiones y tiempos que sean amigables para el códec.
- Preprocesamiento de Imagen
- Tu primer cuadro se redimensiona y normaliza a un aspecto amigable para el modelo mientras se preserva la composición. Un prefiltro ligero ayuda a estabilizar bordes y reducir el ruido de compresión que puede causar parpadeo durante el movimiento. Este paso es importante incluso cuando solo usas la imagen para sugerir diseño y color.
- Latente Vacío
- El flujo de trabajo asigna latentes vacíos de video y audio en función de tus dimensiones, duración y tasa de cuadros. Esto proporciona un lienzo limpio para el muestreador y asegura que el audio y el video se mantengan alineados en longitud. El ruido se genera de manera determinista cuando deseas reproducibilidad o se aleatoriza para variación entre ejecuciones.
- Generar Baja Resolución
- Una primera pasada de muestreo esculpe movimiento y estructura en un video latente compacto. Si estás usando imagen a video,
LTXVImgToVideoInplace(#249) inyecta tu primer cuadro como ancla visual para que el movimiento evolucione desde un punto de partida coherente. El acondicionamiento de tu texto positivo y negativo guía el contenido y el estilo, mientras queManualSigmas(#252) yKSamplerSelectdefinen cuán agresivamente se elimina el ruido con el tiempo.LTXVCropGuides(#212) ayuda a mantener el encuadre que coincide con tu prompt. El latente de audio-video resultante se divide para procesamiento separado.
- Una primera pasada de muestreo esculpe movimiento y estructura en un video latente compacto. Si estás usando imagen a video,
- Escalado Latente
- Antes de comprometerse con el refinamiento de alta resolución,
LTXVLatentUpsampler(#253) aplica el escalador espacial x2 al latente de baja resolución. Hacer esto en espacio latente es rápido y preserva el movimiento aprendido mientras aumenta la capacidad de detalle. Es una forma segura de agregar nitidez sin introducir artefactos.
- Antes de comprometerse con el refinamiento de alta resolución,
- Generar Alta Resolución
- Un segundo muestreador refina el latente escalado a mayor tamaño espacial para fijar texturas, iluminación y pequeños movimientos. Al ejecutar texto a video, el paso anterior de imagen a video puede omitirse y
LTXVImgToVideoInplace(#230) simplemente pasa el latente.VAEDecodeTiled(#251) luego decodifica el latente de video en cuadros de manera eficiente. En paralelo, el latente de audio se decodifica con el LTX Audio VAE para que ambos flujos terminen siendo precisos por cuadro.
- Un segundo muestreador refina el latente escalado a mayor tamaño espacial para fijar texturas, iluminación y pequeños movimientos. Al ejecutar texto a video, el paso anterior de imagen a video puede omitirse y
- Exportar
CreateVideo(#242) mezcla cuadros y audio en un solo video a la tasa de cuadros elegida. El nodo de nivel superiorSaveVideoescribe el archivo final en tu salida de ComfyUI para que puedas descargarlo de inmediato. Tu renderizado LTX 2.3 Imagen a Video ahora está listo para previsualizar o publicar.
Nodos clave en el flujo de trabajo LTX 2.3 Imagen a Video de ComfyUI#
LTXVImgToVideoInplace(#249 y #230)- Convierte una imagen fija en un latente de video o pasa el latente cuando está desactivado. Úsalo cuando desees que el primer cuadro defina el diseño, la paleta y la colocación de personajes. Cambia el interruptor de texto a video si prefieres que el movimiento surja únicamente del prompt. La documentación para la familia de operadores se mantiene en la integración de ComfyUI en GitHub.
LTXVConditioning(#239)- Combina texto positivo y negativo codificado con tu tasa de cuadros para producir un acondicionamiento que dirige tanto el contenido como el ritmo del movimiento. Favorece oraciones cortas y claras que describan cambios a lo largo del tiempo y reserva los negativos para artefactos que ves consistentemente y deseas suprimir. Este nodo es el lugar más efectivo para ajustar el estilo y el comportamiento de la escena sin tocar los muestreadores.
ManualSigmas(#252) conKSamplerSelect- El programa de ruido y el muestreador trabajan juntos para intercambiar gran movimiento versus detalle fino. Un ruido temprano más alto fomenta un movimiento más amplio mientras que los pasos posteriores consolidan la textura. Ajusta estos solo después de tener buenos prompts y guía de imagen en su lugar. Los controles de muestreo subyacentes siguen las semánticas estándar de ComfyUI, consulta implementaciones de referencia en el repositorio LTX en GitHub.
LTXVLatentUpsampler(#253)- Aplica el escalador espacial LTX 2.3 en espacio latente para que puedas refinar a mayor resolución en la siguiente etapa. Úsalo cuando necesites nitidez extra o planees entregar formatos más grandes. El modelo x2 se distribuye con LTX 2.3 en Hugging Face.
VAEDecodeTiled(#251) yCreateVideo(#242)- La decodificación en mosaico previene picos de memoria a resoluciones más altas y asegura calidad de cuadro consistente.
CreateVideoluego ensambla los cuadros y la pista de audio decodificada en un MP4 final a tus fps seleccionados. Mantén tus fps consistentes con el valor usado durante el acondicionamiento para evitar desajuste de reproducción.
- La decodificación en mosaico previene picos de memoria a resoluciones más altas y asegura calidad de cuadro consistente.
Extras opcionales#
- Aún debes cargar una imagen de primer cuadro incluso cuando uses texto a video. El interruptor lo ignorará durante la generación pero la interfaz requiere una imagen de marcador de posición.
- Para el prompting de LTX 2.3 Imagen a Video, comienza con la acción principal, luego detalles visuales, luego atmósfera. Palabras de tiempo como "lentamente," "repentinamente," y "continúa" ayudan al modelo a planificar el movimiento.
- Usa prompts negativos para evitar superposiciones y artefactos de interfaz de usuario como "marca de agua," "subtítulos," o "cuadro fijo."
- Si el estilo parece demasiado fuerte o demasiado débil, prueba un LoRA diferente o ajusta su peso en el cargador de LoRA. También puedes eliminar el LoRA para apoyarte en el aspecto del modelo base.
- Reutiliza una semilla de ruido fija para reproducibilidad al iterar en texto, luego aleatoriza para variación una vez que bloquees la toma.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Lightricks por LTX-2.3 y a EyeForAILabs por el Tutorial de YouTube de EyeForAILabs por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.