
LTX 2.3 Sincronización Labial de Doble Personaje LoRA: video de sincronización labial de dos personajes a partir de una imagen y una pista de audio#
Este flujo de trabajo de ComfyUI convierte una sola imagen fija y una conversación grabada de dos oradores en un video coherente y estable en identidad con discurso sincronizado para ambos personajes en pantalla. Construido alrededor de la columna vertebral de video LTX‑2.3 y LTX 2.3 Sincronización Labial de Doble Personaje LoRA, mapea fonemas y sincronización de tu diálogo a cada rostro mientras preserva expresiones, mirada y consistencia de escena a través de los fotogramas.
Diseñado para entrevistas, diálogos cinematográficos, podcasts con anfitriones de video e interacciones de personajes virtuales, el flujo de trabajo acopla el texto de aviso para la disposición de la escena con movimiento impulsado por audio. Incluye una etapa de arranque de imagen para un desarrollo rápido de aspecto, muestreo LTX de dos etapas para estabilidad temporal y un aumentador latente para resultados nítidos. La salida final es un MP4 con audio incrustado.
Modelos clave en el flujo de trabajo de Comfyui LTX 2.3 Sincronización Labial de Doble Personaje LoRA#
- Modelo de generación de video LTX‑2.3. Proporciona la columna vertebral de difusión multimodal que sintetiza video consistentemente temporal condicionado por texto, imagen y audio. Lightricks/LTX-2.3
- LTX‑2.3 Video VAE y Audio VAE. Codifican y decodifican latentes de video y audio usados por el modelo para mantener la generación eficiente y sincronizada. Incluido con el lanzamiento de LTX‑2.3. Lightricks/LTX-2.3
- Aumentador latente espacial LTX. Refina detalles después del pase base aumentando en el espacio latente para texturas y bordes más limpios. Las variantes están disponibles junto con los activos LTX. Lightricks/LTX-2
- LTX 2.3 Sincronización Labial de Doble Personaje LoRA. Inyecta entrenamiento que fomenta el movimiento y temporización de la boca por orador para dos rostros en la misma toma mientras retiene la identidad facial.
- Modelo de texto a imagen Z‑Image Turbo. Produce rápidamente una imagen de referencia de alta calidad que ancla la identidad, el encuadre y la iluminación antes de la síntesis de video. Comfy‑Org/z_image_turbo
Paquetes de nodos relacionados utilizados por este flujo de trabajo: ComfyUI‑KJNodes, ComfyUI‑VideoHelperSuite, rgthree‑comfy, y ComfyUI‑PromptRelay.
Cómo usar el flujo de trabajo de Comfyui LTX 2.3 Sincronización Labial de Doble Personaje LoRA#
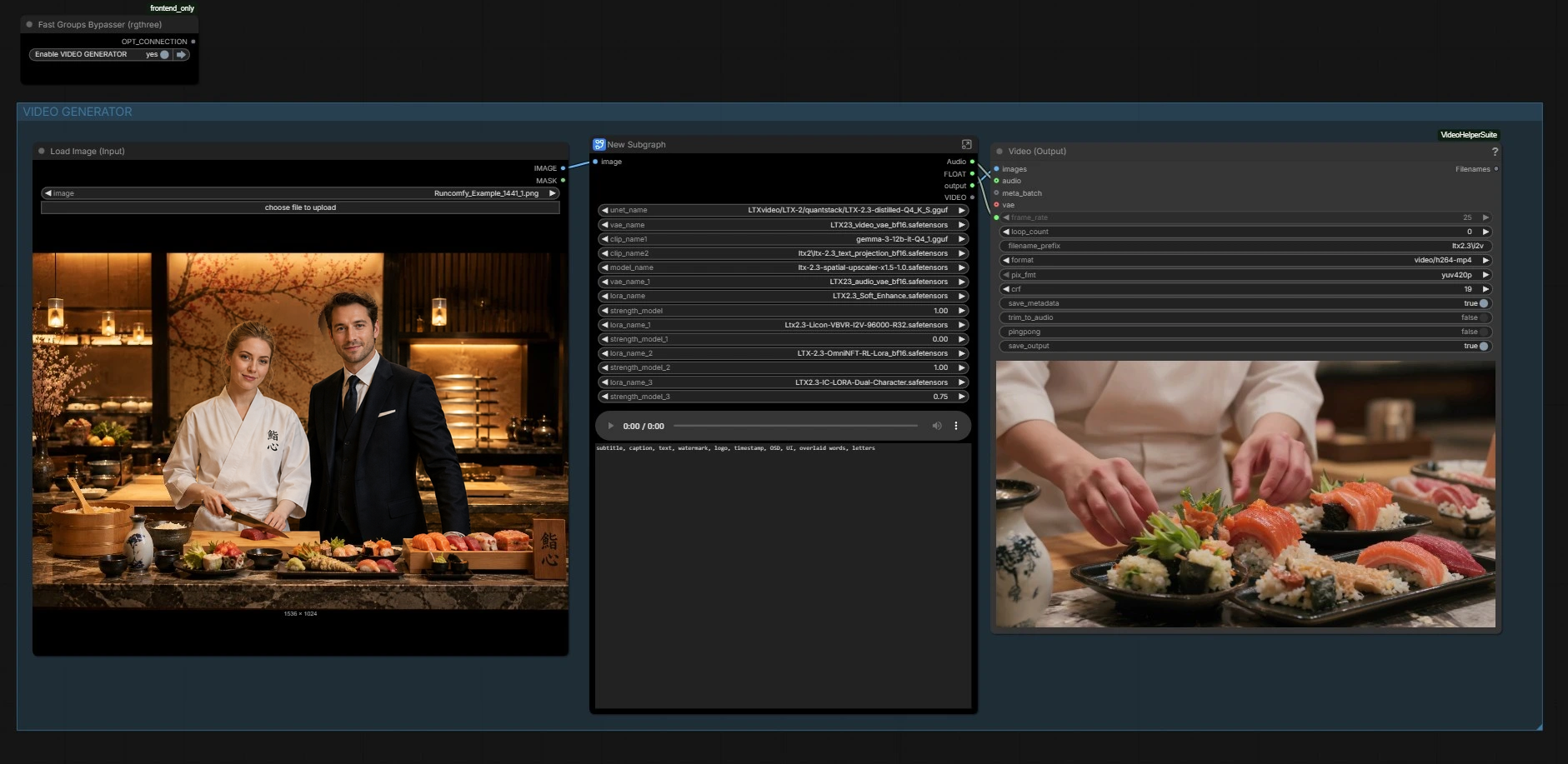
El flujo de trabajo tiene dos partes coordinadas: un generador de imágenes que crea el fotograma principal y un generador de video que impulsa el movimiento y la sincronización labial a partir del audio mientras preserva el aspecto. Usa los grupos a continuación como tu guía.
GENERADOR DE IMAGEN#
Esta sección construye la imagen ancla. Usa los preajustes de escena en la lista de indicaciones para redactar rápidamente composiciones, luego refina el texto con descripciones de personajes para ambas personas. Una pila de difusión de imagen compacta (subgrafo “Z IMG TURBO”) codifica tu aviso y muestra una imagen de referencia limpia. La imagen se decodifica y guarda para inspección, luego se pasa hacia adelante para sembrar la identidad y disposición para el video.
Entradas clave que tocas aquí: el aviso descriptivo para la escena, vestuario y dos personajes distintos; evita la jerga de lentes o renderizado que luche contra el realismo a menos que ese aspecto sea intencional.
Modelos#
Aquí el gráfico carga la columna vertebral LTX‑2.3, sus VAEs de video y audio, los codificadores de texto y el aumentador latente. También aplica la LTX 2.3 Sincronización Labial de Doble Personaje LoRA, además de LoRAs de estilo u optimización opcionales si los habilitas. Aquí es donde las capacidades del modelo base se combinan con el comportamiento de sincronización labial de dos oradores de la LoRA para dirigir el movimiento de la boca sin sacrificar la identidad. No se necesita acción a menos que quieras cambiar pesos o ajustar la influencia de LoRA.
AUDIO PERSONALIZADO#
Proporciona aquí tu pista de conversación. El archivo de audio se carga y codifica en un latente de audio que transporta señales de sincronización y fonéticas a través de la tubería. Si no proporcionas audio, el flujo de trabajo puede generar movimiento usando un latente de audio vacío, pero la LTX 2.3 Sincronización Labial de Doble Personaje LoRA está diseñada para brillar con diálogo real. Usa una mezcla limpia de dos oradores con un claro turno de palabra para la mejor separación de movimientos de boca.
Parámetros de VIDEO#
Establece la duración objetivo y la tasa de fotogramas. Estos valores se almacenan y reutilizan a lo largo del muestreo, programación, guías de recorte y renderizado final para que los labios, parpadeos y sincronización de tomas permanezcan alineados. Mantén la longitud de tu video consistente con el audio proporcionado para evitar comienzo o finalización adicionales.
GENERACIÓN LATENTE#
Tu imagen seleccionada se preprocesa y sus dimensiones se detectan. El flujo de trabajo crea un latente de video de la longitud correcta, luego inserta la imagen en su lugar para que el primer fotograma coincida con tu diseño. Se aplica una máscara de ruido de cuadro completo para controlar cuánto puede evolucionar el fondo versus los rostros. El latente de audio preparado se empareja con el latente de video para que ambas modalidades estén listas para el acondicionamiento.
Nodos notables: LTXVPreprocess escala tu imagen para LTX, EmptyLTXVLatentVideo construye la línea de tiempo, y LTXVImgToVideoInplaceKJ (#5881) bloquea la identidad sembrando el primer fotograma desde la imagen.
Acondicionamiento#
Las indicaciones de texto se codifican y se adjuntan como condiciones positivas y negativas. Usa el cuadro de aviso global para describir la disposición y el propósito en lenguaje natural; puedes incluir una breve lista de tomas si es útil. Un codificador de texto negativo dedicado suprime subtítulos en el cuadro, marcas de agua y UI para que los rostros queden limpios. Los ayudantes de guía de recorte analizan el latente para colocar atención en ambos rostros, mejorando el seguimiento de expresiones por orador con la LTX 2.3 Sincronización Labial de Doble Personaje LoRA activa.
Componentes representativos: PromptRelayEncode (#5903) fusiona tu descripción de escena con el contexto latente, y LTXVConditioning adjunta orientación consciente de la tasa de fotogramas para ambas modalidades.
1er Muestreo#
El primer pase de desruido genera un video base temporalmente coherente con movimiento labial bloqueado. Un programador y muestreador livianos se seleccionan automáticamente, con parámetros enrutados desde los valores de sincronización almacenados. La variante del modelo que sale de LTX2_NAG agrega orientación consciente del ruido para las condiciones de video y audio para que la sincronización del discurso permanezca anclada mientras se forma el contenido.
Ruta del muestreador principal: SamplerCustom (#5891) con KSamplerSelect y un programador básico; ajusta solo si tienes preferencias de muestreador específicas.
Etapa #2 Escalado y refinamiento#
La segunda etapa mejora la nitidez y las microexpresiones. El aumentador latente aumenta el detalle espacial, los latentes de audio y video se vuelven a unir, y un muestreador de refinamiento realiza correcciones sutiles mientras preserva el movimiento establecido. Posteriormente, los latentes se separan y decodifican de nuevo a una secuencia de imágenes y una forma de onda de audio.
Bloques importantes: LTXVLatentUpsampler (#5927) para claridad, SamplerCustomAdvanced (#5929) para el pase de refinamiento, seguido de VAEDecode y LTXVAudioVAEDecode para regresar al espacio de píxeles y audio.
Salida#
Finalmente, los fotogramas y el audio se empaquetan en un MP4 para reproducción y revisión. La tasa de fotogramas utilizada para el acondicionamiento se reutiliza aquí para que la cadencia visual y la sincronización de fonemas coincidan con lo que el modelo vio durante la generación. También puedes previsualizar el audio a mitad del gráfico si necesitas una verificación rápida.
Ruta de salida: CreateVideo (#5931) construye el clip; se proporciona una ruta auxiliar VHS_VideoCombine (#5905) para exportaciones alternativas con controles de metadatos.
Nodos clave en el flujo de trabajo de Comfyui LTX 2.3 Sincronización Labial de Doble Personaje LoRA#
LTXICLoRALoaderModelOnly(#5958) Carga la LTX 2.3 Sincronización Labial de Doble Personaje LoRA en la columna vertebral LTX‑2.3. Aumentastrength_modelcuando necesites una articulación de boca más precisa y separación de oradores; redúcelo cuando quieras que el movimiento y estilo del modelo base dominen, especialmente si apilas LoRAs de estilo adicionales.PromptRelayEncode(#5903) Lugar central para escribir la descripción de la escena y, opcionalmente, un breve plan de tomas. Fusiona el aviso global con el contexto del modelo y el latente actual para que la orientación permanezca consistente a lo largo de la línea de tiempo. Mantén el lenguaje claro y describe ambos personajes de manera distinta para ayudar a la separación de identidad y roles.LTXVImgToVideoInplaceKJ(#5881) Siembra el primer fotograma del latente de video directamente desde tu imagen generada o cargada. Esto asegura la identidad, vestuario e iluminación, reduciendo la deriva con el tiempo. Usa una toma media o media‑amplia con ambos rostros sin obstrucciones para obtener los mejores resultados.LTXVAudioVAEEncode(#5851) Convierte la pista de diálogo proporcionada en un latente de audio que el modelo puede usar para la sincronización de fonemas. Alimenta una mezcla limpia sin compresión excesiva; asegúrate de que el tiempo de inicio corresponda al primer discurso en pantalla para evitar un movimiento labial desfasado.SamplerCustom(#5891) ySamplerCustomAdvanced(#5929) Dos etapas de desruido complementarias. Mantén las familias de muestreadores consistentes entre etapas para mantener la continuidad del movimiento y evita cambios drásticos en la programación de ruido una vez que tienes un aspecto que te gusta.LTXVLatentUpsampler(#5927) Aplica el aumentador latente LTX antes del refinamiento para añadir nitidez sin desestabilizar el movimiento establecido. Elige una variante de aumentador adecuada para tu resolución objetivo y realismo de textura.
Extras opcionales#
- Usa un WAV de dos oradores a 24 kHz con ruido de fondo mínimo; añade pausas naturales cortas entre líneas para ayudar a la LTX 2.3 Sincronización Labial de Doble Personaje LoRA a separar turnos.
- Genera o proporciona una imagen donde ambos sujetos sean visibles, mirando generalmente hacia la cámara, con iluminación consistente en los rostros.
- Mantén la indicación de texto negativa que excluye “subtítulo, leyenda, logo, marca de tiempo” para evitar elementos de UI incrustados durante el muestreo.
- Comienza con un clip corto para validar la sincronización, luego extiende la duración o aumenta la resolución una vez que te guste el comportamiento.
- Si añades LoRAs de estilo, equilíbralos contra la LTX 2.3 Sincronización Labial de Doble Personaje LoRA para que la articulación se mantenga precisa mientras la escena retiene tu estética elegida.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a los creadores de “LTX 2.3 Dual Character Lip Sync LoRA Workflow Source” por el flujo de trabajo. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- LTX 2.3 Dual Character Lip Sync LoRA Workflow Source/LTX 2.3 Dual Character Lip Sync LoRA Workflow Source
- Documentos / Notas de lanzamiento: YouTube video
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las licencias y términos respectivos proporcionados por sus autores y mantenedores.