
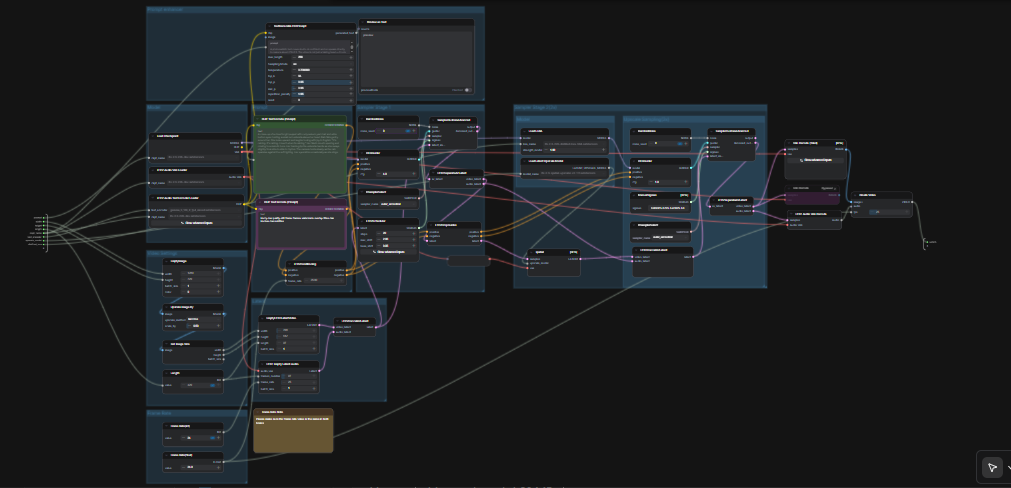
LTX 2.3 ComfyUI: Texto a Video con audio limpio, muestreo en dos etapas y escalado espacial 2×#
Este flujo de trabajo LTX 2.3 ComfyUI convierte indicaciones cortas en videos cinematográficos pulidos con audio sincronizado. Está construido alrededor del modelo LTX‑2.3 de Lightricks y configurado para alta coherencia visual, movimiento estable y salida compatible con transmisiones. Creadores, editores y artistas técnicos pueden pasar de una sola indicación a un MP4 con audio en una sola pasada, utilizando un gráfico simplificado que incluye un potenciador de indicaciones, dos etapas de muestreo y un escalador latente 2×.
En comparación con las configuraciones típicas de texto a video, este gráfico enfatiza la consistencia de escenas y la fidelidad de las indicaciones. El camino predeterminado genera un AV latente, lo escala en el espacio latente para obtener detalles más nítidos y luego decodifica a cuadros y audio antes de empaquetar todo en un archivo de video listo para compartir. Si estás explorando modelos de video de código abierto modernos, este flujo de trabajo LTX 2.3 ComfyUI es una forma rápida de obtener movimiento de calidad de producción.
Modelos clave en el flujo de trabajo Comfyui LTX 2.3 ComfyUI#
- LTX‑2.3 22B (dev) checkpoint por Lightricks. El modelo principal de texto a video que produce movimiento de alta coherencia y fuerte consistencia de escenas. Hugging Face • GitHub
- Gemma 3 12B Instruct text encoder (FP4 mixed). Proporciona una comprensión robusta del lenguaje para un mejor soporte de las indicaciones y detalles más ricos de escenas. Hugging Face
- LTX‑2.3 Spatial Upscaler x2 1.0. Un escalador en espacio latente que agudiza el detalle espacial sin romper la consistencia del movimiento. Hugging Face
- LTX‑2.3 22B Distilled LoRA (384). Un adaptador destilado que refina la fidelidad de textura y estabiliza el estilo durante la etapa de escalado/refinamiento. Hugging Face
- LTX Audio VAE. El módulo de audio emparejado con LTX‑2.3 que permite generar sonido limpio y sincronizado a partir de la misma indicación. Hugging Face
Cómo usar el flujo de trabajo Comfyui LTX 2.3 ComfyUI#
El gráfico se ejecuta en dos pasadas coordinadas. Primero genera un AV latente a una resolución de trabajo con tu indicación. Luego realiza un escalado latente 2× y una segunda pasada de muestreo con un LoRA destilado antes de decodificar a cuadros y audio, finalmente multiplexando a MP4.
Potenciador de indicaciones#
El nodo TextGenerateLTX2Prompt (#149) reescribe el lenguaje simple en una indicación compatible con el modelo que cubre acciones, elementos visuales y señales de audio. Aliméntalo con tu descripción de escena; se pueden conectar imágenes de referencia opcionales cuando desees orientación para encuadre o estilo. El texto generado se dirige a un codificador positivo mientras que una indicación negativa enfocada en la calidad reduce los artefactos. Este equilibrio ayuda al modelo LTX‑2.3 a mantenerse fiel a la indicación sin restringir en exceso la creatividad.
Modelo#
El CheckpointLoaderSimple (#146) carga el checkpoint LTX‑2.3 22B y expone tanto el modelo como su VAE. LTXAVTextEncoderLoader (#147) trae el codificador de texto Gemma 3 12B Instruct que el flujo de trabajo utiliza para el acondicionamiento positivo y negativo. Mantén estas selecciones a menos que estés probando otras variantes de LTX, ya que el resto del gráfico está ajustado para este emparejamiento.
Configuración de Video#
La resolución y la duración se establecen con un andamiaje de imagen ligero y el control Length. El gráfico lee el tamaño de la imagen, lo escala para una resolución de trabajo y reenvía esos valores al creador de video latente. Los modelos LTX tienen restricciones de paso; mantente en tamaños que sigan un patrón de paso de 32 y longitudes que se alineen con la cadencia de cuadros del modelo. El gráfico ajustará suavemente los valores ilegales al más cercano válido, pero elegir tamaños válidos desde el principio produce la mejor composición.
Tasa de Cuadros#
Dos pequeños controles establecen los FPS tanto para el acondicionamiento como para la codificación final: Frame Rate(int) (#141) y Frame Rate(float) (#140). Manténlos idénticos para que el tiempo de movimiento y la alineación de audio se mantengan consistentes en toda la tubería. Elige una tasa fílmica si deseas un movimiento más suave o iguala los valores predeterminados de la plataforma al apuntar a formatos sociales.
Latente#
EmptyLTXVLatentVideo (#121) inicializa el video latente y LTXVEmptyLatentAudio (#119) hace lo mismo para el audio. LTXVConcatAVLatent (#122) los fusiona en un solo AV latente para que la guía de texto pueda dirigir ambas modalidades juntas. LTXVConditioning (#120) adjunta el acondicionamiento positivo y negativo, y LTXVCropGuides (#115) adapta la guía al diseño espacial del latente para un encuadre más confiable.
Etapa de Muestreo 1#
Esta etapa crea el AV latente inicial usando RandomNoise (#151), KSamplerSelect (#144) y el LTXVScheduler (#112) compatible con LTX con un CFGGuider (#139). El planificador está adaptado para LTX para equilibrar la estabilidad temporal con la adherencia a la indicación. Si deseas más variación, cambia la semilla de ruido; para una mayor adherencia al guion, favorece muestreadores que mantengan la coherencia temporal.
Modelo (LoRA)#
LoraLoaderModelOnly (#143) aplica el LoRA destilado LTX‑2.3 antes del refinamiento. Este adaptador mejora sutilmente el pulido de textura y la fidelidad de estilo sin perder la consistencia del movimiento. Es más notable en piel, tela y reflejos especulares.
Muestreo de Escalado (2×)#
LTXVLatentUpsampler (#130) realiza un escalado espacial 2× en espacio latente utilizando el LatentUpscaleModelLoader (#114) cargado y el VAE base. Debido a que el escalado ocurre antes de la decodificación, retienes la suavidad temporal mientras ganas detalles espaciales finos. Los latentes de video y audio escalados se vuelven a unir con LTXVConcatAVLatent (#129) para la pasada de refinamiento.
Etapa de Muestreo 2 (2×)#
La segunda pasada refina el latente escalado usando RandomNoise (#127), KSamplerSelect (#145) y un planificador ManualSigmas (#113) bajo un CFGGuider (#116). Esta etapa es donde se finalizan los detalles micro y la nitidez de los bordes. Funciona mejor cuando el LoRA está activo y la indicación es específica sobre texturas e iluminación.
Decodificación y Salida#
LTXVSeparateAVLatent (#135) divide el latente refinado para que VAEDecodeTiled (#137) pueda reconstruir cuadros mientras LTXVAudioVAEDecode (#138) restaura el audio. CreateVideo (#133) multiplexa cuadros y audio a los FPS elegidos, y el nodo de nivel superior SaveVideo escribe un MP4 en la carpeta de video del flujo de trabajo. El resultado es un archivo limpio y listo para compartir producido enteramente dentro del pipeline LTX 2.3 ComfyUI.
Nodos clave en el flujo de trabajo Comfyui LTX 2.3 ComfyUI#
TextGenerateLTX2Prompt(#149): Convierte descripciones simples en indicaciones estructuradas que cubren movimiento, atributos visuales y audio. Ajusta tu redacción aquí primero al dirigir ritmos de historia o ritmo; generalmente produce mayores ganancias que los ajustes de muestreo.LTXVScheduler(#112): Un planificador específico de LTX que da forma a cómo se elimina el ruido con el tiempo. Empareja con cuidado con tu muestreador elegido para equilibrar la estabilidad temporal y la fidelidad a la indicación.LTXVLatentUpsampler(#130): Realiza un escalado espacial 2× directamente en espacio latente, preservando la continuidad del movimiento mientras añade un detalle nítido. Úsalo cuando desees resultados más nítidos sin recurrir a escaladores post-decodificación.LoraLoaderModelOnly(#143): Aplica el LoRA destilado LTX‑2.3 para el refinamiento. Aumenta la influencia para un control de estilo más ajustado; redúcela si deseas el aspecto más amplio del modelo base.CreateVideo(#133): Multiplexa cuadros decodificados con audio generado a los FPS seleccionados para que el tiempo y la sincronización de labios se mantengan intactos. Si cambias los FPS, mantén ambos controles de tasa de cuadros igualados.
Extras opcionales#
- Consejos para indicaciones: Describe acciones a lo largo del tiempo, enumera elementos visuales clave y especifica el sonido o diálogo que esperas. Una redacción clara y concisa da al codificador LTX‑2.3 la mejor señal.
- Dimensiones y longitud: Prefiere tamaños en un paso de 32 y longitudes que respeten la cadencia de cuadros del modelo. Aunque el gráfico ajusta automáticamente los valores cercanos, las entradas válidas mejoran la composición y reducen el temblor sutil.
- Iteración rápida: Cambia la semilla de
RandomNoiseentre ejecuciones para explorar variantes mientras mantienes la misma indicación y configuraciones. - Cambio de modelo: Los valores predeterminados están ajustados para LTX‑2.3 22B con Gemma 3 12B IT y el escalador espacial 2×. Cambia de modelos solo si entiendes cómo afecta cada uno al acondicionamiento y la decodificación.
Reconocimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Lightricks por el modelo LTX-2.3 y a EyeForAILabs por el tutorial de YouTube por sus contribuciones y mantenimiento. Para obtener detalles autorizados, consulte la documentación y los repositorios originales enlazados a continuación.
Recursos#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: 2601.03233
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: YouTube Channel from @eyeforailabs
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.