
Animación Controlable en AI Video: WanVideo + TTM Flujo de Trabajo de Control de Movimiento para ComfyUI#
Este flujo de trabajo de mickmumpitz lleva la Animación Controlable en AI Video a ComfyUI utilizando un enfoque guiado por movimiento, sin necesidad de entrenamiento. Combina la difusión de imagen a video de WanVideo con la guía latente Time-to-Move (TTM) y máscaras conscientes de la región para que puedas dirigir cómo se mueven los sujetos mientras preservas la identidad, textura y continuidad de la escena.
Puedes comenzar desde una placa de video o desde dos fotogramas clave, agregar máscaras de región que enfoquen el movimiento donde lo desees, y dirigir trayectorias sin ningún ajuste fino. El resultado es una Animación Controlable en AI Video precisa y repetible, adecuada para tomas dirigidas, secuencias de movimiento de objetos y ediciones creativas personalizadas.
Modelos clave en el flujo de trabajo de Animación Controlable en AI Video de Comfyui#
- Wan2.2 I2V A14B (HIGH/LOW). El modelo central de difusión de imagen a video que sintetiza el movimiento y la coherencia temporal a partir de indicaciones y referencias visuales. Dos variantes equilibran la fidelidad (HIGH) y la agilidad (LOW) para diferentes intensidades de movimiento. Los archivos del modelo están alojados en las colecciones comunitarias de WanVideo en Hugging Face, por ejemplo, las distribuciones de WanVideo de Kijai. Enlaces: Kijai/WanVideo_comfy_fp8_scaled, Kijai/WanVideo_comfy
- Lightx2v I2V LoRA. Un adaptador ligero que refuerza la estructura y la consistencia del movimiento al componer Animación Controlable en AI Video con Wan2.2. Ayuda a mantener la geometría del sujeto bajo señales de movimiento más fuertes. Enlace: Kijai/WanVideo_comfy – Lightx2v LoRA
- Wan2.1 VAE. El autoencoder de video utilizado para codificar fotogramas a latentes y decodificar las salidas del muestreador de nuevo a imágenes sin sacrificar detalle. Enlace: Kijai/WanVideo_comfy – Wan2_1_VAE_bf16.safetensors
- Codificador de texto UMT5-XXL. Proporciona incrustaciones de texto ricas para el control impulsado por indicaciones junto con señales de movimiento. Enlaces: google/umt5-xxl, Kijai/WanVideo_comfy – pesos del codificador
- Modelos Segment Anything para máscaras de video. SAM3 y SAM2 crean y propagan máscaras de región a través de fotogramas, permitiendo una guía dependiente de la región que agudiza la Animación Controlable en AI Video donde importa. Enlaces: facebook/sam3, facebook/sam2
- Qwen-Image-Edit 2509 (opcional). Una base de edición de imágenes y un LoRA relámpago para limpieza rápida de fotogramas iniciales/finales o eliminación de objetos antes de la animación. Enlaces: QuantStack/Qwen-Image-Edit-2509-GGUF, lightx2v/Qwen-Image-Lightning, Comfy-Org/Qwen-Image_ComfyUI
- Guía Time-to-Move (TTM). El flujo de trabajo integra latentes TTM para inyectar control de trayectoria de manera libre de entrenamiento para Animación Controlable en AI Video. Enlace: time-to-move/TTM
Cómo usar el flujo de trabajo de Animación Controlable en AI Video de Comfyui#
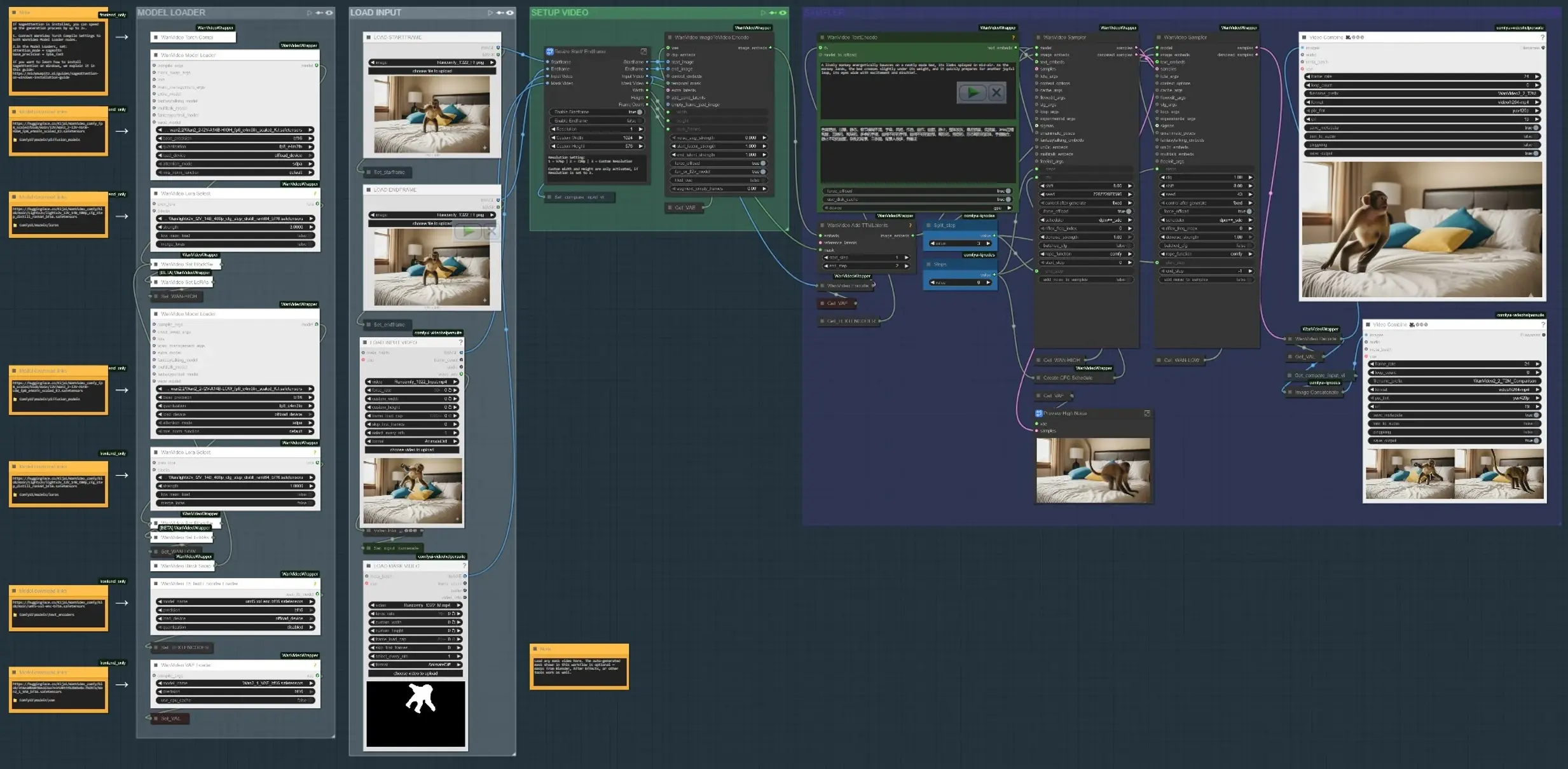
El flujo de trabajo se ejecuta en cuatro fases principales: cargar entradas, definir dónde debería ocurrir el movimiento, codificar señales de texto y movimiento, luego sintetizar y previsualizar el resultado. Cada grupo a continuación se asigna a una sección etiquetada en el gráfico.
- CARGAR ENTRADA Usa el grupo “LOAD INPUT VIDEO” para traer una placa o clip de referencia, o carga fotogramas iniciales y finales si estás construyendo movimiento entre dos estados. El subgrafo “Resize Start/Endframe” normaliza dimensiones y opcionalmente permite el enmarcado inicial y final. Un comparador lado a lado construye una salida que muestra la entrada versus el resultado para una revisión rápida (
VHS_VideoCombine(#613)). - CARGADOR DE MODELO El grupo “MODEL LOADER” configura Wan2.2 I2V (HIGH/LOW) y aplica el Lightx2v LoRA. Un camino de intercambio de bloques mezcla variantes para un buen equilibrio entre fidelidad y movimiento antes del muestreo. El Wan VAE se carga una vez y se comparte a través de codificación/decodificación. La codificación de texto utiliza UMT5-XXL para un fuerte acondicionamiento de indicaciones en Animación Controlable en AI Video.
- SAM3/SAM2 SUJETO DE MÁSCARA En “SAM3 MASK SUBJECT” o “SAM2 MASK SUBJECT”, haz clic en un fotograma de referencia, agrega puntos positivos y negativos, y propaga máscaras a través del clip. Esto produce máscaras temporalmente consistentes que limitan las ediciones de movimiento al sujeto o región que elijas, permitiendo una guía dependiente de la región. También puedes omitir y cargar tu propio video de máscara; las máscaras de Blender/After Effects funcionan bien cuando deseas control dibujado por el artista.
- PREPARACIÓN DE FOTOGRAMA INICIAL/FINAL (opcional) Los grupos “STARTFRAME – QWEN REMOVE” y “ENDFRAME – QWEN REMOVE” proporcionan un pase de limpieza opcional en fotogramas específicos usando Qwen-Image-Edit. Úsalos para eliminar aparejos, palos o artefactos de placa que de otro modo contaminarían las señales de movimiento. La pintura sobre cultivos y costuras edita de nuevo al fotograma completo para una base limpia.
- CODIFICACIÓN DE TEXTO + MOVIMIENTO Las indicaciones se codifican con UMT5-XXL en
WanVideoTextEncode(#605). Las imágenes de fotograma inicial/final se transforman en latentes de video enWanVideoImageToVideoEncode(#89). Los latentes de movimiento TTM y una máscara temporal opcional se combinan a través deWanVideoAddTTMLatents(#104) para que el muestreador reciba tanto señales semánticas (texto) como de trayectoria, central para la Animación Controlable en AI Video. - MUESTREADOR Y PREVISUALIZACIÓN El muestreador Wan (
WanVideoSampler(#27) yWanVideoSampler(#90)) elimina el ruido de los latentes utilizando una configuración de doble reloj: un camino gobierna la dinámica global mientras que el otro preserva la apariencia local. Los pasos y un programa configurable de CFG moldean la intensidad del movimiento versus la fidelidad. El resultado se decodifica en fotogramas y se guarda como un video; una salida de comparación ayuda a juzgar si tu Animación Controlable en AI Video coincide con el resumen.
Nodos clave en el flujo de trabajo de Animación Controlable en AI Video de Comfyui#
WanVideoImageToVideoEncode(#89) Codifica imágenes de fotograma inicial/final en latentes de video que inician la síntesis de movimiento. Ajusta solo al cambiar la resolución base o el conteo de fotogramas; mantén estos alineados con tu entrada para evitar estiramientos. Si usas un video de máscara, asegúrate de que sus dimensiones coincidan con el tamaño latente codificado.WanVideoAddTTMLatents(#104) Fusiona latentes de movimiento TTM y máscaras temporales en el flujo de control. Alterna la entrada de máscara para restringir el movimiento a tu sujeto; dejarlo vacío aplica movimiento globalmente. Usa esto cuando quieras Animación Controlable en AI Video específica de trayectoria sin afectar el fondo.SAM3VideoSegmentation(#687) Recoge algunos puntos positivos y negativos, elige un fotograma de pista, luego propaga a través del clip. Usa la salida de visualización para validar el desplazamiento de la máscara antes del muestreo. Para flujos de trabajo sensibles a la privacidad o sin conexión, cambia al grupo SAM2 que no requiere bloqueo de modelo.WanVideoSampler(#27) El eliminador de ruido que equilibra movimiento e identidad. Acopla “Steps” con la lista de programas CFG para empujar o relajar la fuerza del movimiento; una fuerza excesiva puede superar la apariencia, mientras que muy poca no cumple con el movimiento. Cuando las máscaras están activas, el muestreador concentra actualizaciones dentro de la región, mejorando la estabilidad para Animación Controlable en AI Video.
Extras opcionales#
- Para iteraciones rápidas, comienza con el modelo LOW Wan2.2, ajusta el movimiento con TTM, luego cambia a HIGH para el pase final para recuperar textura.
- Usa videos de máscara dibujados por artistas para siluetas complejas; el cargador acepta máscaras externas y las redimensionará para que coincidan.
- Los interruptores de “fotograma inicial/final” te permiten bloquear visualmente el primer o último fotograma, útil para transferencias sin interrupciones en ediciones más largas.
- Si está disponible en tu entorno, habilitar atención optimizada (por ejemplo, SageAttention) puede acelerar significativamente el muestreo.
- Haz coincidir la tasa de fotogramas de salida con la fuente en el nodo de combinación para evitar diferencias de tiempo percibidas en Animación Controlable en AI Video.
Este flujo de trabajo ofrece control de movimiento consciente de la región y libre de entrenamiento combinando indicaciones de texto, latentes TTM y segmentación robusta. Con algunas entradas específicas, puedes dirigir Animación Controlable en AI Video matizada y lista para producción mientras mantienes los sujetos en modelo y las escenas coherentes.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a Mickmumpitz quien es el creador de Animación Controlable en AI Video para el tutorial/publicación, y al equipo de time-to-move por TTM por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Patreon/Controllable Animation in AI Video
- Documentación / Notas de lanzamiento: Publicación de Mickmumpitz en Patreon
- time-to-move/TTM
- GitHub: time-to-move/TTM
Nota: El uso de los modelos, conjuntos de datos y códigos referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.
