
InfiniteTalk: video de retrato sincronizado con labios a partir de una sola imagen en ComfyUI#
Este flujo de trabajo InfiniteTalk de ComfyUI crea videos de retrato sincronizados con el habla natural a partir de una imagen de referencia única más un clip de audio. Combina la generación de imagen a video de WanVideo 2.1 con el modelo de cabeza parlante MultiTalk para producir movimiento expresivo de labios y una identidad estable. Si necesitas clips sociales cortos, doblajes de video o actualizaciones de avatar, InfiniteTalk convierte una foto estática en un video parlante fluido en minutos.
InfiniteTalk se basa en la excelente investigación MultiTalk de MeiGen-AI. Para antecedentes y atribuciones, consulta el proyecto de código abierto: MeiGen-AI/MultiTalk.
Modelos clave en el flujo de trabajo InfiniteTalk de Comfyui#
- MultiTalk (GGUF, variante InfiniteTalk): Impulsa el movimiento facial consciente de fonemas a partir de audio para que los movimientos de boca y mandíbula sigan el habla de manera natural. Referencia: Kijai/WanVideo_comfy_GGUF › InfiniteTalk y idea original: MeiGen-AI/MultiTalk.
- WanVideo 2.1 I2V 14B (GGUF): El generador de imagen a video principal que preserva identidad, iluminación y pose mientras anima los fotogramas. Pesos recomendados: city96/Wan2.1-I2V-14B-480P-gguf.
- Wan 2.1 VAE (bf16): Decodifica fotogramas latentes a RGB con un cambio mínimo de color; proporcionado en los paquetes de WanVideo anteriores.
- UMT5-XXL codificador de texto: Interpreta tus prompts positivos y negativos para influir en el estilo, escena y contexto de movimiento. Familia de modelos: google/umt5-xxl.
- CLIP Vision: Extrae incrustaciones visuales de tu imagen de referencia para fijar identidad y apariencia general.
- Wav2Vec2 (Tencent GameMate): Convierte el habla en bruto a características de audio robustas para incrustaciones de MultiTalk, mejorando la sincronización y prosodia: TencentGameMate/chinese-wav2vec2-base.
Consejo: este gráfico de InfiniteTalk está construido para GGUF. Mantén los pesos de MultiTalk de InfiniteTalk y el backbone de WanVideo en GGUF para evitar incompatibilidades. También están disponibles construcciones opcionales fp8/fp16: Kijai/WanVideo_comfy_fp8_scaled y Kijai/WanVideo_comfy.
Cómo usar el flujo de trabajo InfiniteTalk de Comfyui#
El flujo de trabajo se ejecuta de izquierda a derecha. Proporcionas tres cosas: una imagen de retrato limpia, un archivo de audio de habla y un breve prompt para dirigir el estilo. El gráfico luego extrae señales de texto, imagen y audio, las fusiona en latentes de video conscientes del movimiento y renderiza un MP4 sincronizado.
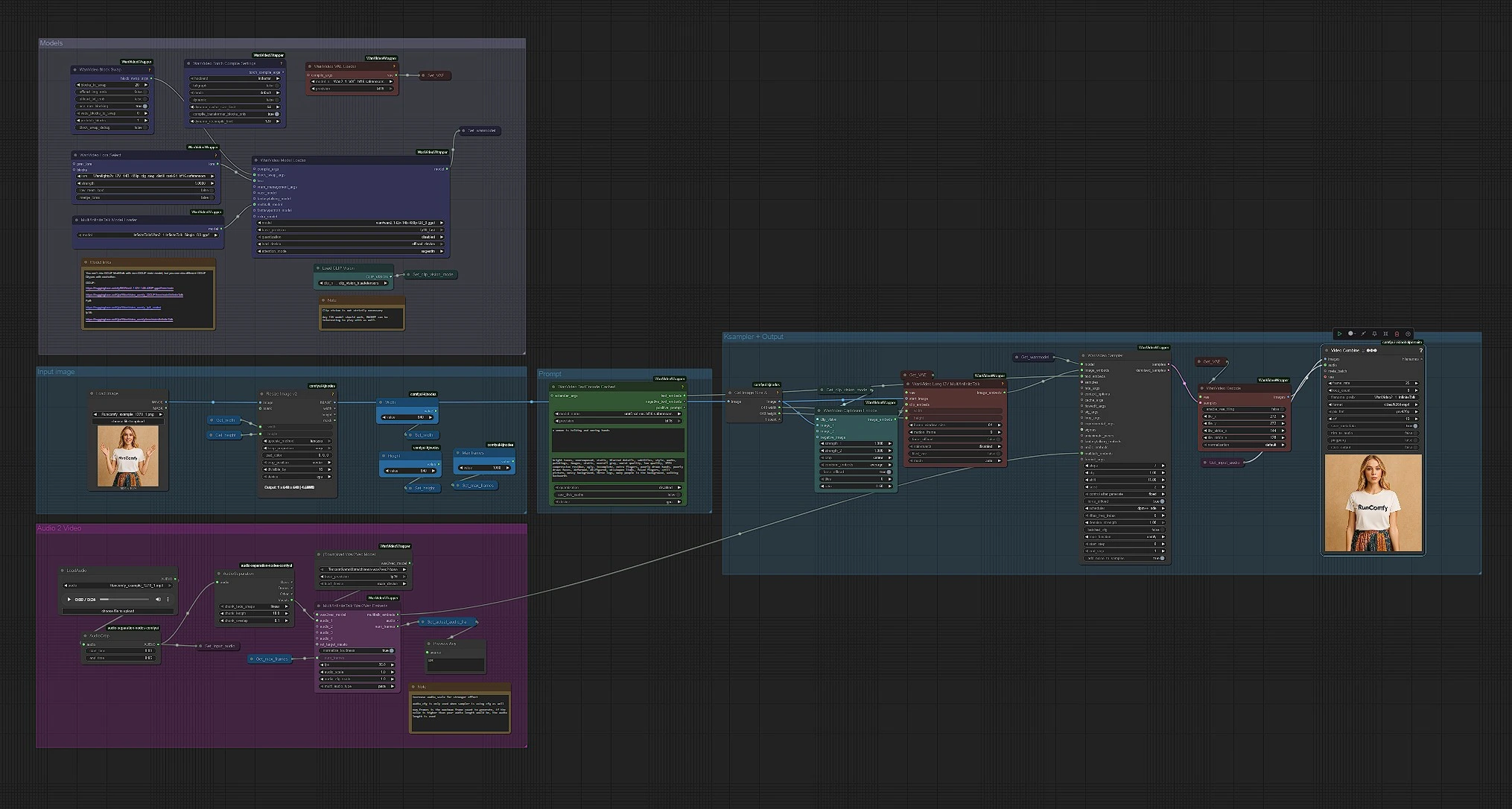
Modelos#
Este grupo carga WanVideo, VAE, MultiTalk, CLIP Vision y el codificador de texto. WanVideoModelLoader (#122) selecciona el backbone Wan 2.1 I2V 14B GGUF, mientras que WanVideoVAELoader (#129) prepara el VAE correspondiente. MultiTalkModelLoader (#120) carga la variante InfiniteTalk que impulsa el movimiento impulsado por el habla. Puedes opcionalmente adjuntar un Wan LoRA en WanVideoLoraSelect (#13) para sesgar apariencia y movimiento. Déjalos sin tocar para una primera ejecución rápida; están preconfigurados para una tubería de 480p amigable para la mayoría de las GPUs.
Prompt#
WanVideoTextEncodeCached (#241) toma tus prompts positivos y negativos y los codifica con UMT5. Usa el prompt positivo para describir el sujeto y el tono de la escena, no la identidad; la identidad proviene de la foto de referencia. Mantén el prompt negativo enfocado en los artefactos que deseas evitar (desenfoques, extremidades extra, fondos grises). Los prompts en InfiniteTalk principalmente moldean la iluminación y la energía del movimiento mientras que el rostro se mantiene consistente.
Imagen de entrada#
CLIPVisionLoader (#238) y WanVideoClipVisionEncode (#237) incrustan tu retrato. Usa una foto nítida de frente, de cabeza y hombros con luz uniforme. Si es necesario, recorta suavemente para que el rostro tenga espacio para moverse; un recorte excesivo puede desestabilizar el movimiento. Las incrustaciones de la imagen se pasan hacia adelante para preservar la identidad y los detalles de la ropa a medida que el video se anima.
Audio a MultiTalk#
Carga tu habla en LoadAudio (#125); recórtala con AudioCrop (#159) para previsualizaciones rápidas. DownloadAndLoadWav2VecModel (#137) descarga Wav2Vec2, y MultiTalkWav2VecEmbeds (#194) convierte el clip en características de movimiento conscientes de fonemas. Cortes cortos de 4 a 8 segundos son excelentes para iterar; puedes ejecutar tomas más largas una vez que te guste el aspecto. Las pistas de voz limpias y secas funcionan mejor; la música de fondo fuerte puede confundir la sincronización de labios.
Imagen a video, muestreo y salida#
WanVideoImageToVideoMultiTalk (#192) fusiona tu imagen, incrustaciones CLIP Vision y MultiTalk en incrustaciones de imagen por fotograma dimensionadas por las constantes Width y Height. WanVideoSampler (#128) genera los fotogramas latentes usando el modelo WanVideo de Get_wanmodel y tus incrustaciones de texto. WanVideoDecode (#130) convierte los latentes a fotogramas RGB. Finalmente, VHS_VideoCombine (#131) mezcla fotogramas y audio en un MP4 a 25 fps con un ajuste de calidad equilibrado, produciendo el clip final de InfiniteTalk.
Nodos clave en el flujo de trabajo InfiniteTalk de Comfyui#
WanVideoImageToVideoMultiTalk (#192)#
Este nodo es el corazón de InfiniteTalk: condiciona la animación de cabeza parlante al fusionar la imagen inicial, características CLIP Vision y guía MultiTalk a tu resolución objetivo. Ajusta width y height para establecer el aspecto; 832×480 es un buen valor por defecto para velocidad y estabilidad. Úsalo como el lugar principal para alinear identidad con movimiento antes de muestrear.
MultiTalkWav2VecEmbeds (#194)#
Convierte características Wav2Vec2 en incrustaciones de movimiento MultiTalk. Si el movimiento de labios es demasiado sutil, aumenta su influencia (escalado de audio) en esta etapa; si está sobreexagerado, disminuye la influencia. Asegúrate de que el audio sea dominante en habla para una sincronización de fonemas confiable.
WanVideoSampler (#128)#
Genera los latentes de video dados imagen, texto e incrustaciones MultiTalk. Para las primeras ejecuciones, mantén el planificador y los pasos predeterminados. Si ves parpadeo, aumentar los pasos totales o habilitar CFG puede ayudar; si el movimiento se siente demasiado rígido, reduce CFG o la fuerza del muestreador.
WanVideoTextEncodeCached (#241)#
Codifica prompts positivos y negativos con UMT5-XXL. Usa lenguaje conciso y concreto como "luz de estudio, piel suave, color natural" y mantén los prompts negativos enfocados. Recuerda que los prompts refinan el encuadre y el estilo, mientras que la sincronización de labios proviene de MultiTalk.
Extras opcionales#
- Mantén MultiTalk y WanVideo en la misma familia de implementación (todo GGUF o todo no-GGUF) para evitar incompatibilidades.
- Itera con un recorte de audio de 5 a 8 segundos y el tamaño predeterminado de 480p; aumenta la escala más tarde si es necesario.
- Si la identidad tambalea, prueba con una foto de origen más limpia o un LoRA más suave. Los LoRAs fuertes pueden anular la semejanza.
- Graba el habla en una habitación silenciosa y normaliza los niveles; InfiniteTalk sigue mejor los fonemas con una voz clara y seca.
Agradecimientos#
El flujo de trabajo InfiniteTalk representa un gran avance en la generación de video impulsada por IA al combinar el sistema de nodos flexible de ComfyUI con el modelo de IA MultiTalk. Esta implementación fue posible gracias a la investigación original y el lanzamiento de MeiGen-AI, cuyo proyecto MultiTalk impulsa la sincronización natural del habla de InfiniteTalk. Un agradecimiento especial también al equipo del proyecto InfiniteTalk por proporcionar la referencia fuente, y a la comunidad de desarrolladores de ComfyUI por permitir la integración fluida del flujo de trabajo.
Además, el crédito va a Kijai, quien implementó InfiniteTalk en el nodo Wan Video Sampler, facilitando a los creadores la producción de retratos parlantes y cantantes de alta calidad directamente dentro de ComfyUI. El enlace al recurso original para InfiniteTalk está disponible aquí: InfiniteTalk Example Workflow.
Juntos, estas contribuciones hacen posible que los creadores transformen simples retratos en avatares parlantes continuos y realistas, desbloqueando nuevas oportunidades para la narración, el doblaje y el contenido de rendimiento impulsado por IA.
