
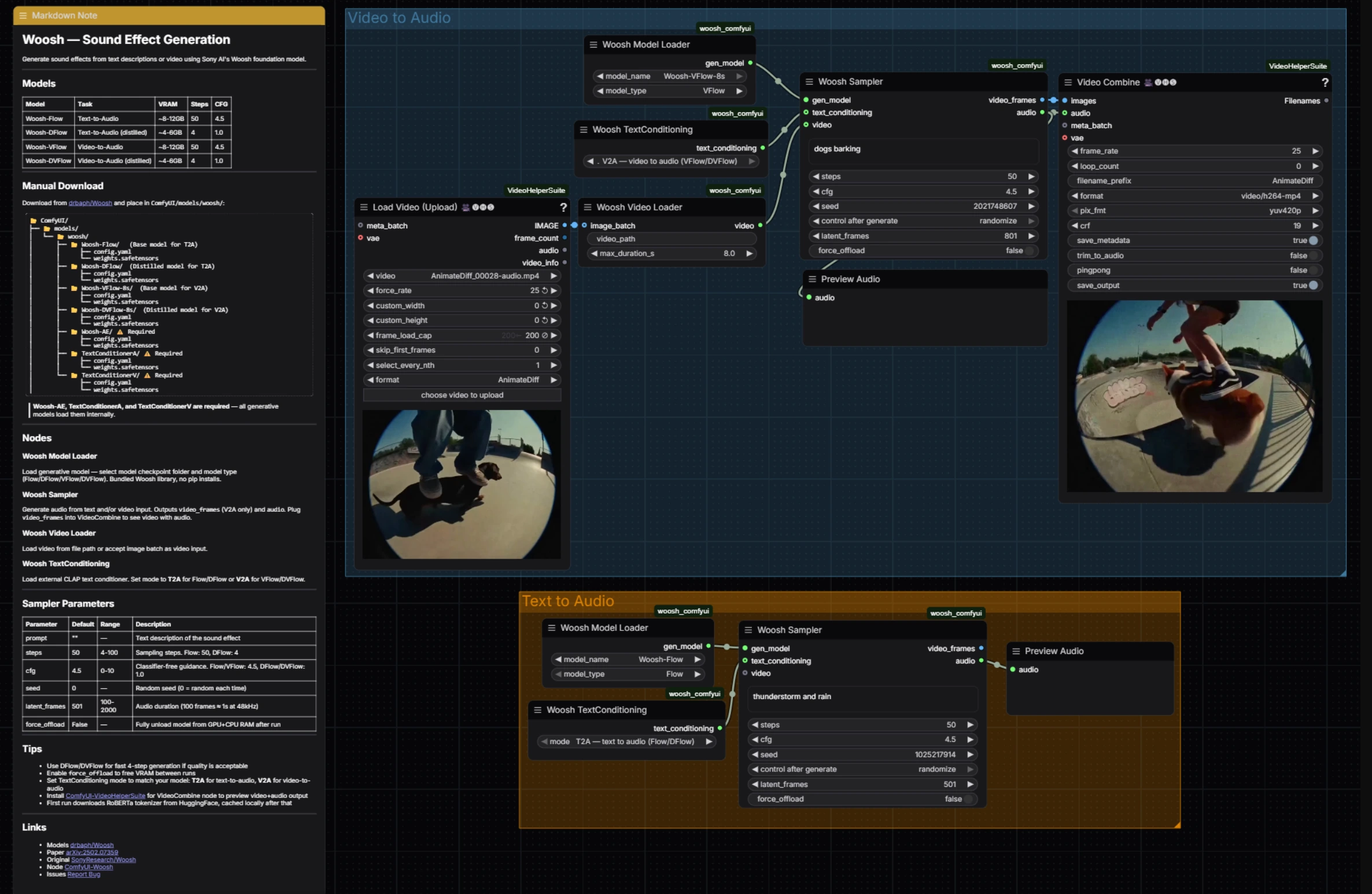
Woosh Sound Effect Generation: prompt- und videobasiertes Audio in ComfyUI#
Woosh Sound Effect Generation ist ein ComfyUI-Workflow, der entweder Texteingaben oder Videoclips in ausgefeilte Soundeffekte umwandelt, wobei das Woosh-Grundmodell von Sony Research verwendet wird. Es ist für Kreative gedacht, die eine zentrale Anlaufstelle für promptbasiertes Foley, eng videomatchtes Sounddesign und schnelles Umschalten zwischen hochwertigen und schnell destillierten Varianten benötigen.
Der Workflow zeigt beide Familien der Woosh-Modelle: Flow/DFlow für Text-zu-Audio und VFlow/DVFlow für Video-zu-Audio. Ein gemeinsamer Sampler steuert die Generierung in beiden Pfaden und gibt Audio für die sofortige Vorschau aus. Im Videopfad werden Frame-Vorschauen ausgegeben, die für schnelle Dailies wieder kombiniert werden. Im Hintergrund verlässt es sich auf die offiziellen ComfyUI Woosh-Nodes und die VideoHelperSuite für nahtloses Video-IO, damit Woosh Sound Effect Generation schnell und einfach bleibt, während es flexibel bleibt. Referenzen: SonyResearch/Woosh, drbaph/Woosh auf Hugging Face, paper, ComfyUI-Woosh, ComfyUI-VideoHelperSuite.
Wichtige Modelle im ComfyUI Woosh Sound Effect Generation Workflow#
- Sony Research Woosh — Flow: Kern-Text-zu-Audio-Generator, der für hochauflösende Foley und Ambiente verwendet wird und mit flow-matching Zielen trainiert wird. Siehe SonyResearch/Woosh und das paper.
- Sony Research Woosh — DFlow: destilliertes Text-zu-Audio-Modell, das für Geschwindigkeit optimiert ist und weit weniger Abtastschritte erfordert, ideal für schnelle Iterationen. Gewichte sind verfügbar unter drbaph/Woosh.
- Sony Research Woosh — VFlow-8s: videobasiertes Generator-Modell, das Audio-Anfänge und -Texturen mit visuellen Bewegungshinweisen für Video-zu-Audio synchronisiert. Siehe SonyResearch/Woosh.
- Sony Research Woosh — DVFlow-8s: destilliertes Video-zu-Audio-Modell für Echtzeit-Workflows und schnelle Vorschauen. Gewichte: drbaph/Woosh.
- Woosh-AE: der Audio-Autoencoder, der verwendet wird, um Wellenformen aus Modell-Latents zu rekonstruieren; erforderlich für alle Generatoren. Gewichte: drbaph/Woosh.
- TextConditionerA und TextConditionerV: Textkonditionierungs-Module, die Eingaben passend für Text-zu-Audio oder Video-zu-Audio-Läufe einbetten. Details und Nutzung sind dokumentiert in ComfyUI-Woosh und dem paper.
Verwendung des ComfyUI Woosh Sound Effect Generation Workflows#
Dieser Workflow hat zwei parallele Gruppen, die Sie unabhängig ausführen können: Video zu Audio für visuell abgestimmtes Sounddesign und Text zu Audio für reine promptbasierte Foley. Beide konvergieren auf die gleiche Sampler-Logik und schnelle Audio-Vorschau, wodurch Woosh Sound Effect Generation konsistent zu bedienen ist, unabhängig vom Input.
Video zu Audio#
Die Video zu Audio-Gruppe lädt einen Clip, richtet Frames und Konditionierung aus und erzeugt dann synchronisierten Sound. Beginnen Sie, indem Sie Ihren Clip in VHS_LoadVideo (#34) einspeisen; es extrahiert Frames mit Ihrer gewählten Rate, sodass nachgelagerte Nodes eine saubere, begrenzte Sequenz sehen. Diese Frames werden als Videokonditionierungsstrom von WooshLoadVideo (#37) gepackt, der die Dauer standardisiert, sodass der Generator gleichmäßige Fenster erhält.
Wählen Sie ein videobasiertes Modell in WooshLoadFlow (#7), typischerweise VFlow für hohe Treue oder DVFlow für Geschwindigkeit. Geben Sie eine kurze beschreibende Eingabeaufforderung im Sampler ein (für Stil oder Absicht) und setzen Sie WooshTextEncode (#19) auf V2A, damit der Text mit dem richtigen Konditionierungszweig eingebettet wird. Führen Sie WooshSample (#38) aus, um Audio zu synthetisieren; es gibt sowohl audio für PreviewAudio (#9) als auch video_frames aus, die in VHS_VideoCombine (#33) für eine schnelle zusammengesetzte Vorschau fließen und Woosh Sound Effect Generation eng für die redaktionelle Überprüfung halten.
Text zu Audio#
Die Text zu Audio-Gruppe konzentriert sich auf saubere, eingabeaufforderungsgesteuerte Generierung. Wählen Sie ein Modell in WooshLoadFlow (#40), wobei Sie Flow verwenden, wenn Sie maximale Qualität wünschen, und DFlow, wenn Sie sehr schnelle, iterative Durchläufe benötigen. Setzen Sie WooshTextEncode (#41) auf T2A, damit Ihre Eingabeaufforderung für eine reine Textgenerierung eingebettet ist. Geben Sie Ihre Beschreibung in WooshSample (#39) ein und führen Sie sie aus; das Ergebnis wird an PreviewAudio (#43) zur sofortigen Wiedergabe gesendet. Dieser Pfad hält Woosh Sound Effect Generation leichtgewichtig, wenn Sie Bibliotheken erstellen oder Effekte ohne Bild überlagern.
Wichtige Knoten im ComfyUI Woosh Sound Effect Generation Workflow#
WooshSample (#38)#
Zentraler Sampler für videobasiertes Generieren. Passen Sie die Eingabeaufforderung an, um Stil und Anfänge zu steuern, und justieren Sie steps für den Qualitäts-Geschwindigkeits-Kompromiss (weniger Schritte verwenden, wenn DVFlow läuft). cfg steuert die Eingabeaufforderungstreue, und latent_frames bestimmt die Ausgabelänge, sodass sie mit dem Clip übereinstimmt oder absichtlich verschoben wird. Setzen Sie seed, um Takes zu reproduzieren, und aktivieren Sie force_offload, wenn Sie zwischen langen Läufen Speicher freigeben müssen. Die Knotenimplementierung und das Verhalten folgen dem offiziellen ComfyUI-Woosh.
WooshSample (#39)#
Sampler für Text-zu-Audio mit denselben Steuerungen und Verhalten, abzüglich des Videostreams. Für schnelle Ideenfindung wählen Sie DFlow und niedrige steps; für Endversionen wechseln Sie zu Flow und erhöhen steps für Details. Halten Sie cfg moderat für natürliche Texturen, erhöhen Sie es für stilisierte, eingabeaufforderungsgesperrte Ergebnisse. Verwenden Sie latent_frames, um die Dauer präzise festzulegen, wenn Sie Assets für Bibliotheken oder DAW-Zeitachsen erstellen.
WooshLoadFlow (#7)#
Modellwähler für den Video zu Audio-Pfad. Wählen Sie VFlow für höchste Treueanpassung an Bewegungen oder DVFlow, wenn Sie nahezu Echtzeit-Vorschauen benötigen. Stellen Sie sicher, dass WooshTextEncode auf V2A gesetzt ist, damit die Einbettungen zur gewählten Modellfamilie passen. Siehe drbaph/Woosh für Modellvarianten.
WooshLoadFlow (#40)#
Modellwähler für den Text zu Audio-Pfad. Wählen Sie Flow für reichhaltige Details und breitere Texturvielfalt oder DFlow für schnelle Iterationen mit minimalen Schritten. Kombinieren Sie es mit WooshTextEncode im T2A-Modus, um Konditionierungsmismatches zu vermeiden. Das Knotenverhalten und die Optionen folgen dem offiziellen ComfyUI-Woosh.
VHS_VideoCombine (#33)#
Hilfsprogramm zum Zusammenfügen des generierten audio mit der video_frames-Vorschau vom Sampler, um einen überprüfbaren Clip zu erstellen. Verwenden Sie es, um Synchronisation zu prüfen, Übergänge zu bewerten und Dailies zu teilen, ohne ComfyUI zu verlassen. Teil der ComfyUI-VideoHelperSuite.
Optionale Extras#
- Verwenden Sie DVFlow/DFlow für schnelle Erkundungspässe und wechseln Sie dann zu VFlow/Flow für Endversionen, wenn Woosh Sound Effect Generation glänzen muss.
- Halten Sie Ihren Eingabeclip innerhalb des ausgewählten Modellfensters (zum Beispiel die 8-Sekunden-VFlow-Varianten) und verarbeiten Sie längere Szenen in überlappenden Abschnitten, die Sie überblenden können.
- Halten Sie eine konsistente Bildrate von
VHS_LoadVideobisVHS_VideoCombine, um Drift zwischen Audio und Bild zu reduzieren. - Für Eingabeaufforderungen kombinieren Sie Aktionswörter mit Textur- und akustischem Kontext (zum Beispiel "schnelles metallisches Zischen in einem Betontreppenhaus"), um vorhersehbare Ergebnisse zu erzielen.
- Schalten Sie
force_offloadim Sampler zwischen schweren Läufen ein, wenn der GPU-Speicher knapp ist.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Sony Research für Woosh (Projekt und Papier), Saganaki22 für ComfyUI-Woosh (ComfyUI Node) und Kosinkadink für ComfyUI-VideoHelperSuite für ihre Beiträge und Wartung. Für autoritative Details verweisen wir bitte auf die Originaldokumentation und -repositories, die unten verlinkt sind.
Ressourcen#
- Saganaki22/ComfyUI-Woosh
- GitHub: Saganaki22/ComfyUI-Woosh
- drbaph/Woosh
- Hugging Face: drbaph/Woosh
- SonyResearch/Woosh
- GitHub: SonyResearch/Woosh
- Sony Research/Woosh (paper)
- arXiv: 2502.07359
- Kosinkadink/ComfyUI-VideoHelperSuite
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.
