
SCAIL-2 Charakterbewegungsübertragung: Referenzbild zu langem Videoworkflow#
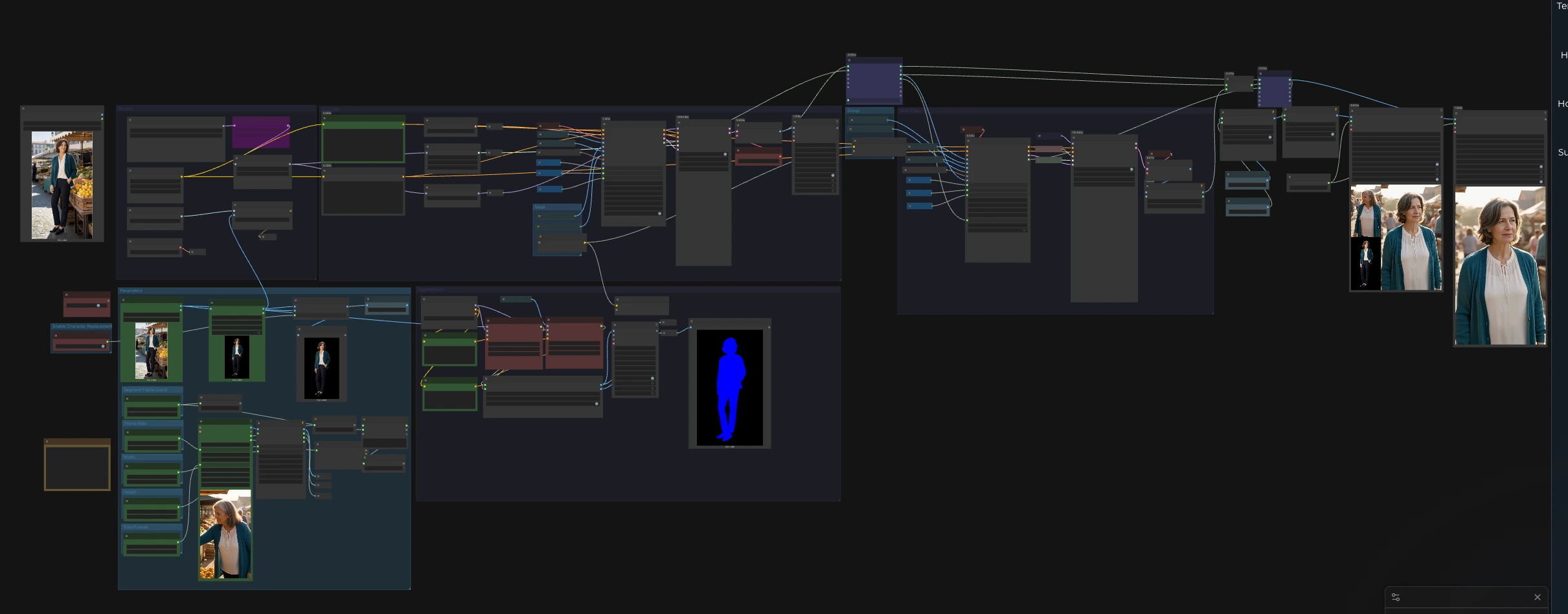
Dieser ComfyUI-Pipeline verwandelt ein einzelnes Referenzbild in eine lange, identitätsgetreue Charakterdarstellung, indem er Bewegung aus einem treibenden Video übernimmt. Basierend auf dem SCAIL-2 Wan 2.1 14B Pfad mit CLIP Vision-Konditionierung, SAM-basierter Personenmaskierung und LightX2V-Beschleunigung ist er für Stabilität über lange Sequenzen und einfache Nebeneinander-Inspektion optimiert. Es ist ein praktischer SCAIL-2 Charakterbewegungsübertragungs-Workflow für Referenzbilder zu langen Videos für Kreative, die konsistente Identität, Garderobe und Stil über Hunderte von Frames benötigen.
Verwenden Sie ihn, um Katalogstil-Bewegungstests, Referenzbild-zu-Video-Demonstrationen und westliche Editorial-Marktvideobeispiele zu erstellen. Der Workflow unterstützt optionale Relight-Anleitungen, sodass das Motiv mit der Fahrszene harmonisiert werden kann, während Gesichts- und Outfitdetails mit Ihrem Referenzbild übereinstimmen.
Schlüsselmodelle im ComfyUI SCAIL-2 Charakterbewegungsübertragungs-Workflow für Referenzbilder zu langen Videos#
- SCAIL-2 auf Wan 2.1 14B. Kernidentitätsbewusste Videodiffusion, die für die Bewegungsübertragung verwendet wird. Der Workflow lädt die 14B SCAIL-2 Gewichte, die für ComfyUI verpackt sind, und kombiniert sie mit einem Wan VAE zur Rekonstruktion. Siehe die Modellsammlung in Comfy-Org/SCAIL-2 und die Methodenübersicht in zai-org/SCAIL.
- OpenCLIP ViT-H/14 für CLIP Vision. Extrahiert robuste Identitäts- und Erscheinungsembeddings aus dem Referenzbild, um die Generierung zu konditionieren und die Charaktertreue über die Frames hinweg zu verbessern. Referenzmodellfamilie: laion/CLIP-ViT-H-14-laion2B-s32B-b79K.
- Segment Anything (SAM) Familie. Bietet Personenmasken und per-Frame-Tracks, die das Motiv sowohl im Fahrvideo als auch im Referenzbild lokalisieren und gezielte Konditionierung ermöglichen. Projektreferenz: facebookresearch/segment-anything.
- LightX2V LoRA und WanAnimate Relight LoRA. Optionale Adapter, die der Workflow lädt, um die Frame-zu-Frame-Inferenz zu beschleunigen und Relight-Anleitungen anzubieten, damit der übertragene Charakter zur Beleuchtung des Fahrclips passt.
So verwenden Sie den ComfyUI SCAIL-2 Charakterbewegungsübertragungs-Workflow für Referenzbilder zu langen Videos#
Auf hoher Ebene liefern Sie ein Referenzbild und ein Fahrvideo. Die Segmentation-Gruppe findet und maskiert die Person in beiden Quellen, CLIP Vision kodiert die Referenzidentität, ein First Pass generiert ein erstes Segment, und eine Multi-Pass-Schleife überträgt diese Segmentierungslogik über die gesamte Zeitleiste, um ein langes, kohärentes Video zu liefern. Nebeneinander-Vorschaufenster erleichtern die Inspektion von Identitäts- und Poseausrichtung.
Modelle#
Diese Gruppe initialisiert die Backbone-Modelle und optionalen Adapter. Das UNet lädt den SCAIL-2 Wan 2.1 14B Checkpoint, und das VAE übernimmt das latente Decoding für Videoframes. Der Workflow lädt auch CLIP Vision für Identitätsembeddings und zwei LoRA-Adapter: LightX2V für Geschwindigkeit und WanAnimate Relight für Beleuchtungsanleitung. Text-Prompts werden vom Wan-Text-Stack kodiert, um Szene und Ton zu beeinflussen, was praktisch ist, wenn man ein Beispiel des westlichen Editorial-Marktes erstellt.
Parameter#
Verwenden Sie die Parametergruppe, um projektweite Steuerungen einzustellen. Die Auflösung ist freigelegt, sodass Sie eine schnelle Basislinie oder eine schärfere Einstellung wählen können, die zu Ihrem GPU-Budget passt. Die Bildrate bestimmt, wie das Fahrvideo abgetastet und wie der Output für die Wiedergabe kodiert wird. Die Segmentlänge definiert, wie viele Frames jedes Inferenzstück enthält, wodurch der Speicher auf langen Zeitleisten vorhersehbar bleibt. Ein abschließendes Frame-Limit steht zur Verfügung, um die Verarbeitung während der Look-Entwicklung zu begrenzen, bevor der vollständige Clip ausgeführt wird.
Segmentation#
Die Segmentation-Gruppe bereitet saubere, gezielte Anleitungen für die Bewegungsübertragung vor. VHS_LoadVideo (#33) importiert das Fahrvideo, und die Frames werden auf Ihre gewählte Auflösung skaliert, damit sie zum SCAIL-2 Pfad passen. Zwei Tracker, SAM3_VideoTrack (#85) für das Pose-Video und SAM3_VideoTrack (#91) für die Referenz, führen Personenerkennung durch, die durch einfache "person" Textkonditionierung geleitet wird, um die Rückrufquote zu erhöhen. SCAIL2ColoredMask (#104) kombiniert die Tracks in zwei konsistente Masken, eine für das Pose-Video und eine für das Referenzbild, die die Generierungsknoten nutzen, um Bearbeitungen auf das Motiv zu konzentrieren.
First Pass#
Der First Pass bootstrapt die Sequenz und etabliert die Identitätssperre. CLIPVisionEncode (#76) extrahiert Embeddings aus dem Referenzbild, dann kombiniert WanSCAILToVideo (#114) diese Embeddings mit dem Pose-Video und den beiden Masken, um eine latente Sequenz für das erste Segment zu produzieren. Ein einfacher Sampler-Stack SamplerCustom (#19) mit BasicScheduler (#18) rendert dieses Latent in Bilder, dekodiert von VAEDecode (#6). Dieser Pass legt auch einen Frame-Offset fest, den die Multi-Pass-Phase verwendet, um nachfolgende Segmente auszurichten.
Multi-Pass#
Die Multi-Pass-Gruppe skaliert den Lauf auf lange Videos, ohne an Konsistenz zu verlieren. Ein For-Schleifen-Paar, easy forLoopStart (#233) und easy forLoopEnd (#234), iteriert über die gesamte Zeitleiste in festen Segmentgrößen, während die dekodierten Frames als zeitlicher Kontext weitergegeben werden. WanSCAILToVideo (#115) nutzt diesen Kontext über seinen previous_frames Eingang, um die Kontinuität von Gesicht, Haar und Garderobe über Segmentgrenzen hinweg zu verbessern. Der Sampling-Stack SamplerCustom (#63) wird von Ihrem gewählten Sampler und Sigma-Zeitplan angetrieben, sodass Sie Geschwindigkeit und Einhaltung ausbalancieren können, und VAEDecode (#66) gibt jedes Segment als Bilder zurück. Der Workflow fügt dann die Bereiche zusammen und bereitet sie für den Export vor.
Mask#
Die Mask-Gruppe leitet die in Segmentation berechneten Personenmasken weiter, damit sowohl die First Pass- als auch die Multi-Pass-Knoten die richtigen Motivregionen erhalten. Get_pose_video_mask (#122) und Get_reference_image_mask (#120) sorgen dafür, dass Stilübertragung und Identitätserhaltung genau dort angewendet werden, wo sie benötigt werden, um Hintergrunddrift zu reduzieren und Szenendetails außerhalb des Motivs zu schützen.
Charakterersetzung aktivieren#
Diese Gruppe lässt Sie zwischen Identitätsübertragung, die den ursprünglichen Hintergrund respektiert, und vollständigem Vordergrundersatz wechseln. easy imageRemBg (#204) entfernt den Hintergrund aus dem Referenzbild, und ImpactConditionalBranch (#270) schaltet um, ob der gereinigte Vordergrund stromabwärts verwendet wird. Aktivieren Sie es, wenn Sie einen strikten Charaktertausch wünschen, der nützlich für katalogartige Tests oder ein Beispiel des westlichen Editorial-Marktes ist, bei dem ein Motiv einem standardisierten Look entsprechen muss.
Vorschau und Export#
Der Workflow bietet Nebeneinander-Visualisierung und Endrenderings. ImageConcatMulti (#153) komponiert ein schnelles Panel, das die Fahrpose-Frames und das Referenzbild für Plausibilitätsprüfungen zeigt. Ein weiteres ImageConcatMulti (#72) kann die Modellausgabe neben Eingaben für shot-by-shot QA anzeigen. Endvideos werden von VHS_VideoCombine (#71) und VHS_VideoCombine (#236) geschrieben, die bei Bedarf Audio aus der Quelle enthalten können, sodass Rezensionen dem Timing treu bleiben.
Schlüsselnoten im ComfyUI SCAIL-2 Charakterbewegungsübertragungs-Workflow für Referenzbilder zu langen Videos#
WanSCAILToVideo (#114)#
Generiert das anfängliche latente Segment, indem es Pose-Frames, Motivmasken und CLIP Vision-Identitätsembeddings aus dem Referenzbild zusammenführt. Passen Sie pose_strength an, um zwischen dem Kopieren der genauen Bewegung und der Zulassung subtiler Stiladaptionen abzuwägen. Verwenden Sie length, um Ihre Segmentgröße zu entsprechen, damit der Sampler jedes Mal ein vorhersehbares Stück verarbeitet. Wenn Sie die Person auf dem Bildschirm strikt ersetzen, setzen Sie replacement_mode, um die Identität gegenüber dem Hintergrundstil zu bevorzugen. Unterstützt von SCAIL-2 auf Wan 2.1 14B, wie in Comfy-Org/SCAIL-2 verpackt, mit Methoden-Kontext von zai-org/SCAIL.
WanSCAILToVideo (#115)#
Läuft während der Schleife, um den Rest der Zeitleiste mit verbesserter zeitlicher Stabilität abzudecken. Stellen Sie previous_frames aus dem vorherigen Segment bereit, um dem Modell zu helfen, Kleidungsdetails und Gesichtserkennung über Grenzen hinweg stabil zu halten. video_frame_offset und previous_frame_count halten Segmente im Einklang mit dem Fahrclip. Wenn Relight-Anleitungen über das LoRA aktiviert sind, drücken Sie das Stil-Matching in diesem Durchlauf etwas stärker, um die globale Beleuchtung zu harmonisieren.
SAM3_VideoTrack (#85, #91)#
Erkennt und verfolgt die Person sowohl im Pose-Video als auch im Referenzbild. Die "person" Textkonditionierung verbessert die Robustheit, wenn mehrere Objekte vorhanden sind. Wenn der Tracker abdriftet, erhöhen Sie das Erkennungsniveau oder begrenzen Sie max_objects, sodass dasselbe Motiv während des gesamten Prozesses ausgewählt wird. Das Tracking-Konzept folgt der Segment Anything-Familie, siehe facebookresearch/segment-anything für Hintergrundinformationen.
CLIPVisionEncode (#76)#
Erzeugt das Referenzidentitäts-Embedding, das jedes Frame konditioniert. Für Kopf-und-Schulter-Referenzen halten Sie crop auf einer neutralen Wahl, damit der Encoder die gesamte Silhouette und das Outfit sieht. Wenn das Motiv klein im Frame ist, bereiten Sie stattdessen ein engeres Referenzbild vor, anstatt im Node zu stark zu beschneiden. Dieser Node basiert auf OpenCLIP ViT-H/14 Style Vision Features wie in laion/CLIP-ViT-H-14-laion2B-s32B-b79K.
VHS_LoadVideo (#33)#
Importiert und optional resampelt das Fahrvideo für konsistentes Timing. Passen Sie force_rate an die gewünschte Ausgabefrequenz an, halten Sie es dann während der Look-Entwicklung fest, um vergleichbare Ergebnisse über Iterationen hinweg zu erzielen. Verwenden Sie die optionale Frame-Obergrenze beim Testen, um die Durchlaufzeiten zu beschleunigen, heben Sie sie dann für Endrenderings auf.
Optionale Extras#
- Für schnelle Iterationen wählen Sie eine porträtfreundliche Auflösung, dann steigen Sie auf, wenn Sie Finals genehmigen. Der Workflow ist für typische 9:16 Einstellungen abgestimmt, mit einer höheren Option, wenn GPU-Speicher es erlaubt.
- Schreiben Sie Prompts, die Garderobe, Alter und Umgebung in einfacher Sprache beschreiben, um mit den Normen des westlichen Editorial-Marktes übereinzustimmen, zum Beispiel "eine mittelalte Person in einem blauen Pullover in einer hellen Küche".
- Wenn das Outfit des Motivs genau sein muss, senken Sie künstlerische Prompts und erhöhen Sie die Maskenabhängigkeit, sodass das System Kleidungsstücke und Farben gegenüber der Hintergrundstimmung priorisiert.
- Verwenden Sie Charakterersetzung, wenn Sie einen strikten Austausch der Person auf dem Bildschirm wünschen. Lassen Sie es ausgeschaltet, wenn Sie möchten, dass das Modell den Charakter sanft mit der Szene harmonisiert.
- Vermeiden Sie starke Verdeckungen oder schnelle Schnitte im Fahrvideo. Moderate Kamerabewegung und saubere, frontale Bewegungen erzeugen die stabilste Identitätsübertragung.
- Wenn Sie Relight-Anleitungen hinzufügen, beginnen Sie konservativ, sodass Hauttöne und Materialien natürlich bleiben, während sie immer noch die Lichtausrichtung der Szene anpassen.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken zai-org und teal024 für SCAIL/SCAIL-2, Comfy-Org für die SCAIL-2 Modell-Dateien und den Wan 2.1 14B FP8 Checkpoint sowie den RunningHub und RunComfy-Teams für Workflow-Referenzen und Cloud-Save-Workflow für ihre Beiträge und Wartung. Für autoritative Details verweisen Sie bitte auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- RunningHub/Workflow-Referenz
- Docs / Release Notes: RunningHub workflow reference
- zai-org/SCAIL-2 Projekt
- GitHub: zai-org/SCAIL
- teal024/SCAIL Projektseite
- Docs / Release Notes: SCAIL project page
- zai-org/SCAIL-2
- Hugging Face: zai-org/SCAIL-2
- Comfy-Org/SCAIL-2
- Hugging Face: Comfy-Org/SCAIL-2
- Comfy-Org/SCAIL-2 Wan 2.1 14B FP8 Checkpoint
- Hugging Face: wan2.1_14B_SCAIL_2_fp8_scaled.safetensors
- RunComfy/Cloud Save Workflow
- Docs / Release Notes: RunComfy Cloud Save workflow
Hinweis: Die Verwendung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.