
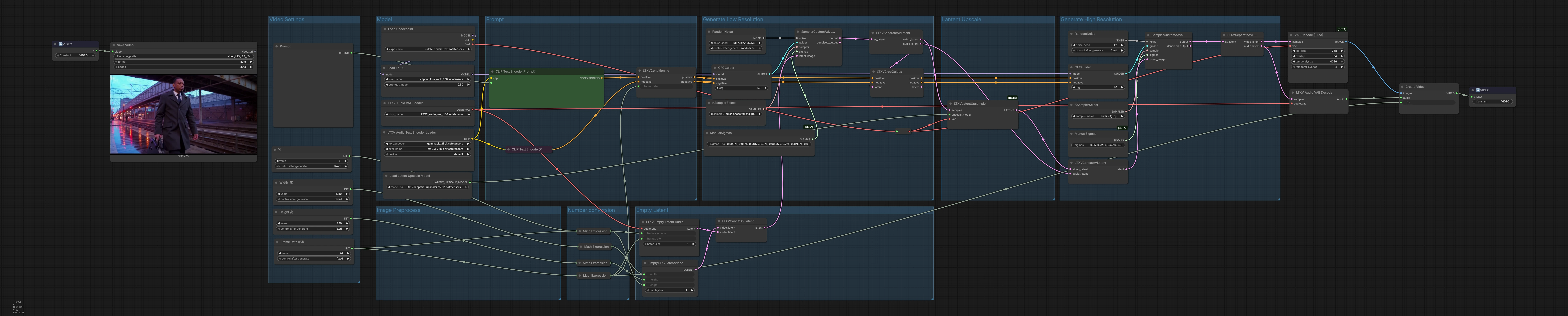
LTX 2.3 Sulphur 2 Text-zu-Video-Workflow für filmische Charakteranimation#
Diese ComfyUI-Pipeline verwandelt natürlichsprachliche Eingaben in kurze, filmische, charakterfokussierte Videos mit optionalem Audio, basierend auf den Lightricks LTX-2.3 und Sulphur 2 Komponenten. Sie plant die Erstellung in niedriger Auflösung zur Bewegungsplanung, skaliert die latente Sequenz hoch und verfeinert dann in hoher Auflösung, bevor sie in Frames dekodiert und eine synchronisierte Audiospur gemischt wird.
Der LTX 2.3 Sulphur 2 Text-zu-Video-Workflow ist ideal für schnelle Charakteranimationstests, D-Human-Stil Bewegungsentwürfe und ausgefeilte Text-zu-Video-Experimente. Er basiert nicht auf Bild-zu-Video-Eingaben oder Prompt-Relais; alles beginnt mit Text, wobei die LTXV-Konditionierung sowohl Video- als auch Audiolatente von Anfang bis Ende leitet.
Schlüsselmodelle im ComfyUI LTX 2.3 Sulphur 2 Text-zu-Video-Workflow#
- Lightricks LTX-2.3. Kern-Text-zu-Video-Generator für spatiotemporale Synthese und multimodale AV-Latente. Siehe das offizielle Modell-Repository für Gewichte und Hinweise zu Fähigkeiten und Einschränkungen. Hugging Face: Lightricks/LTX-2.3
- Lightricks LTX-2.3 FP8 Checkpoint. Speichereffiziente Variante von LTX-2.3, die die Inferenz beschleunigt und längere Clips oder höhere Auflösungen auf eingeschränkten GPUs ermöglicht. Hugging Face: Lightricks/LTX-2.3-fp8
- Sulphur 2 Basis-Modell. Bietet Stilprioritäten und Charakterdetails über LoRA in diesem Workflow und hilft, klare Gesichter und filmische Tonalität zu erreichen. Hugging Face: SulphurAI/Sulphur-2-base
- LTX-2.3 Spatial Upscaler x2 1.1. Latent-Raum Upscaler, der den räumlichen Detailgrad vor dem Hochauflösungs-Verfeinerungsschritt erhöht. Hugging Face: Lightricks/LTX-2.3 file ltx-2.3-spatial-upscaler-x2-1.1.safetensors
- LTX Text-Encoder (Gemma 3 12B IT, verpackt für LTX). Stellt den Text-Einbettungsraum bereit, der auf die LTX-2.3-Konditionierung abgestimmt ist, um eine treue Befolgung der Vorgaben zu gewährleisten. Hugging Face: Comfy-Org/ltx-2
- LTX Audio VAE. Dekodiert das Audio-Latent, das neben dem Video generiert wird, sodass die endgültige Wiedergabe einen synchronisierten Soundtrack enthalten kann. Hugging Face: Lightricks/LTX-2.3
Verwendung des ComfyUI LTX 2.3 Sulphur 2 Text-zu-Video-Workflows#
Gesamtlogik Die Pipeline läuft in drei Akten: Niedrigauflösende Erstellung zur Festlegung von Bewegung und Komposition, latente Hochskalierung zur Erhöhung des räumlichen Details und ein Hochauflösungs-Verfeinerungsschritt, der auch das endgültige Audio liefert. Latente werden in Frames und Wellenformen dekodiert und dann in einem MP4-Container gemischt, der zur Auslieferung bereit ist.
Videoeinstellungen Verwenden Sie die Gruppe "Videoeinstellungen", um Breite, Höhe, Bildrate und Dauer zu definieren. Die Frame-Anzahl wird automatisch aus Ihrer Dauer und FPS berechnet, sodass Timing und Rhythmus konsistent bleiben. Diese Werte steuern die latente Zuordnung und Dekodierung, stellen Sie sie also zuerst ein, um das gewünschte Seitenverhältnis und die Laufzeit zu erreichen. Die Anpassung der FPS informiert auch die Konditionierung, sodass Bewegungsflüssigkeit und Audioausrichtung denselben Takt verwenden.
Prompt Im "Prompt" laden Sie den LTX Text-Encoder mit LTXAVTextEncoderLoader (#316), dann schreiben Sie Ihre positive Beschreibung in CLIPTextEncode (#303) und alle unerwünschten Merkmale in CLIPTextEncode (#312). Der Knoten LTXVConditioning (#304) kombiniert positive und negative Konditionierung und fügt die gewählte Bildrate hinzu, sodass die zeitliche Führung Ihrer FPS entspricht. Behandeln Sie den positiven Prompt wie eine Shot-Beschreibung: Subjekt, Kamera, Beleuchtung, Stimmung und Stilhinweise. Halten Sie die Negativliste fokussiert auf Artefakte, die Sie regelmäßig sehen und entfernen möchten.
Modell Die Gruppe "Modell" lädt den Haupt-Checkpoint über CheckpointLoaderSimple (#315) und wendet eine Sulphur 2 LoRA mit LoraLoaderModelOnly (#285) an, um filmische Textur und Charaktertreue zu infundieren. Hier können Sie Checkpoints oder LoRAs austauschen, um den Gesamteindruck und die Bewegungsprioritäten zu ändern. Der Modellausgang wird sowohl an die anfänglichen als auch an die Verfeinerungsführer weitergeleitet, sodass Stil und Identität über alle Durchgänge hinweg konsistent sind. Die Kombination von LTX-2.3 mit Sulphur 2 ergibt kräftige Kontraste und detaillierte Gesichter, die sich gut in Bewegung lesen lassen.
Zahlenumwandlung Hilfsausdrücke konvertieren Ihre FPS und Sekunden in die ganzzahlige Frame-Anzahl, die downstream verwendet wird. Dies hält die Audio- und Videotimelines ohne manuelle Mathematik synchron. Wenn Sie später FPS oder Dauer ändern, aktualisiert das Diagramm automatisch abhängige Knoten.
Leeres Latent "Leeres Latent" erstellt ausgerichtete Container für die Erstellung: EmptyLTXVLatentVideo (#295) definiert die räumliche Größe und Länge des Video-Latents, LTXVEmptyLatentAudio (#305) weist das Audio-Latent bei derselben Bildrate zu, und LTXVConcatAVLatent (#321) kombiniert sie zu einem einzigen AV-Latent. Beginnend mit leeren Latents sorgt dafür, dass der Diffusionsdurchgang vollständig Ihre Vorgabe und Konditionierung widerspiegelt, anstatt vorhandene Inhalte.
Niedrigauflösende Erstellung Die erste Abtaststufe legt Bewegung und Komposition zu geringeren Kosten fest. CFGGuider (#313), KSamplerSelect (#291) und ManualSigmas (#306) steuern, wie stark die Vorgabe die Erstellung lenkt und den gesamten Geräuschplan. SamplerCustomAdvanced (#283) entstört dann das AV-Latent zu einem kohärenten Clip. Das Ergebnis wird durch LTXVSeparateAVLatent (#307) aufgeteilt und LTXVCropGuides (#284) verfeinert die räumliche Aufmerksamkeit, sodass die von Ihnen gewünschte Subjektgestaltung bei späterem Hochskalieren erhalten bleibt.
Latent Upscale LTXVLatentUpsampler (#287) verwendet den LTX-2.3 x2 Upscaler, um räumliche Details zu erhöhen, während er im latenten Raum bleibt, um Geschwindigkeit und Stabilität zu gewährleisten. Das nach oben skalierte Video-Latent nach vorne zu füttern, verbessert die Textur und Lesbarkeit vor der Hochauflösungs-Verfeinerung. Dies bewahrt die Bewegung, die Ihnen im ersten Durchgang gefallen hat, und eröffnet Spielraum für schärfere Kanten und reichere Materialien.
Hochauflösende Erstellung Das nach oben skalierte Video-Latent wird mit dem Audio-Latent in LTXVConcatAVLatent (#278) wieder vereint und erneut für die endgültige Qualität geführt. CFGGuider (#282), KSamplerSelect (#280) und ManualSigmas (#281) geben das letzte Wort zur Stärke der Vorgabe, Details und zeitlicher Kohärenz, wobei SamplerCustomAdvanced (#308) das verfeinerte AV-Latent produziert. LTXVSeparateAVLatent (#309) übergibt das Video an VAEDecodeTiled (#314) zur speicherschonenden Frame-Dekodierung und das Audio an LTXVAudioVAEDecode (#297) zur Wellenformrekonstruktion. CreateVideo (#310) mischt Frames und Audio bei Ihrer Ziel-FPS und SaveVideo (#75) schreibt eine MP4/H.264-Datei.
Bildvorverarbeitung Dieser Bereich leitet die Basis-VAE- und Upscaler-Modelle, sodass Tiling und latente Hochskalierung innerhalb Ihres VRAM-Budgets arbeiten. Wenn Sie Druck auf den Speicher erleben, bevorzugen Sie die FP8 LTX-2.3-Gewichte und halten Sie die gekachelte Dekodierung aktiviert, um Durchsatz und Qualität zu erhalten.
Wichtige Knoten im ComfyUI LTX 2.3 Sulphur 2 Text-zu-Video-Workflow#
LTXVConditioning (#304) Kombiniert positive und negative Textkonditionierung und fügt die Arbeitsbildrate an, sodass die zeitliche Führung Ihrer Wiedergabe entspricht. Starke, spezifische Szenensprache verbessert die Shot-Struktur; prägnante Negative reduzieren Artefakte. Siehe die LTX-2.3-Modellkarte für Konditionierungshinweise. Hugging Face: Lightricks/LTX-2.3
LTXVCropGuides (#284) Lenkt sanft die Komposition, um das Hauptmotiv wie beabsichtigt im Bild zu halten. Verwenden Sie es, um die Gesichtsgröße, die Horizontplatzierung oder ein zentriertes Subjekt vor dem Hochskalieren und Verfeinern zu schützen. Es ist besonders hilfreich für Dialog-Style-Aufnahmen und mittlere Nahaufnahmen.
CFGGuider (#313, #282) Steuert, wie aggressiv die Vorgabe den Diffusionstrajektorien in beiden Durchgängen beeinflusst. Verwenden Sie den ersten Guider, um Bewegung und Inszenierung zu fixieren, dann den zweiten, um Schärfe hinzuzufügen, ohne sich von der etablierten Aufnahme zu entfernen.
ManualSigmas (#306, #281) Definiert den Geräuschplan. Mehr Geräusch am Anfang fördert größere Bewegungserkundung; ein sanfterer Plan betont zeitliche Konsistenz. Halten Sie die niedrigauflösenden und hochauflösenden Pläne komplementär statt identisch.
LTXVLatentUpsampler (#287) Führt x2 latente Hochskalierung mit dem offiziellen LTX-Upscaler durch, sodass Sie Details vor dem Verfeinerungssampler gewinnen. Der Wechsel zu einer anderen LTX-2.3-Upscaler-Variante kann die Schärfe und Körnigkeit leicht verändern. Hugging Face: Lightricks/LTX-2.3
VAEDecodeTiled (#314) Dekodiert lange oder große Clips in handhabbare Kacheln, um VRAM-Spitzen zu vermeiden. Wenn Sie die räumliche Größe oder die Clip-Länge ändern, passen Sie das Tiling an, um das Speicher-Headroom und die Dekodiergeschwindigkeit auszugleichen.
LoraLoaderModelOnly (#285) Wendet die Sulphur 2 LoRA auf den Basis-Modellpfad an, sodass Charaktertreue und Stilhinweise in beide Abtaststufen übertragen werden. Verwenden Sie dies, um Looks schnell zu wechseln und dabei das gleiche LTX-2.3-Backbone zu behalten. Hugging Face: SulphurAI/Sulphur-2-base
Optionale Extras#
- Seed-Kontrolle: Setzen Sie feste Werte in beiden
RandomNoise-Knoten, damit Takes reproduzierbar sind; ändern Sie einen Seed, um Alternativen zu erkunden. - Prompting: Schreiben Sie Prompts als Shot-Anweisungen (Subjekt, Kamera, Beleuchtung, Stimmung). Halten Sie die Negativliste fokussiert und kurz.
- Leistung: Wenn der VRAM begrenzt ist, bevorzugen Sie die FP8 LTX-2.3-Gewichte und halten Sie die gekachelte Dekodierung aktiviert.
- Ausgabe: Das Diagramm schreibt MP4/H.264; ändern Sie Container oder Codec in
SaveVideo, wenn Sie ProRes-Proxy-Workflows benötigen.
Dieser LTX 2.3 Sulphur 2 Text-zu-Video-Workflow bietet einen klaren, End-to-End-Pfad von der Vorgabe bis zum polierten Video mit synchronisiertem Audio, der für schnelle Iterationen bei filmischen Charakteranimationen entwickelt wurde.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken RunningHub für den Sulphur2 Basic Workflow für Video Production, SulphurAI für das Sulphur-2-base Modell, Lightricks für die LTX-2.3 und LTX-2.3-fp8 Modelle und Comfy-Org für den LTX-2 Text-Encoder für ihre Beiträge und Pflege. Für autoritative Details verweisen wir auf die unten verlinkte Originaldokumentation und Repositories.
Ressourcen#
- RunningHub/Sulphur2 Basic Workflow for Video Production
- Docs / Release Notes: Sulphur2 Basic Workflow for Video Production
- SulphurAI/Sulphur-2-base
- Hugging Face: SulphurAI/Sulphur-2-base
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Lightricks/LTX-2.3-fp8
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-fp8
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
Hinweis: Die Nutzung der genannten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Pfleger.
