
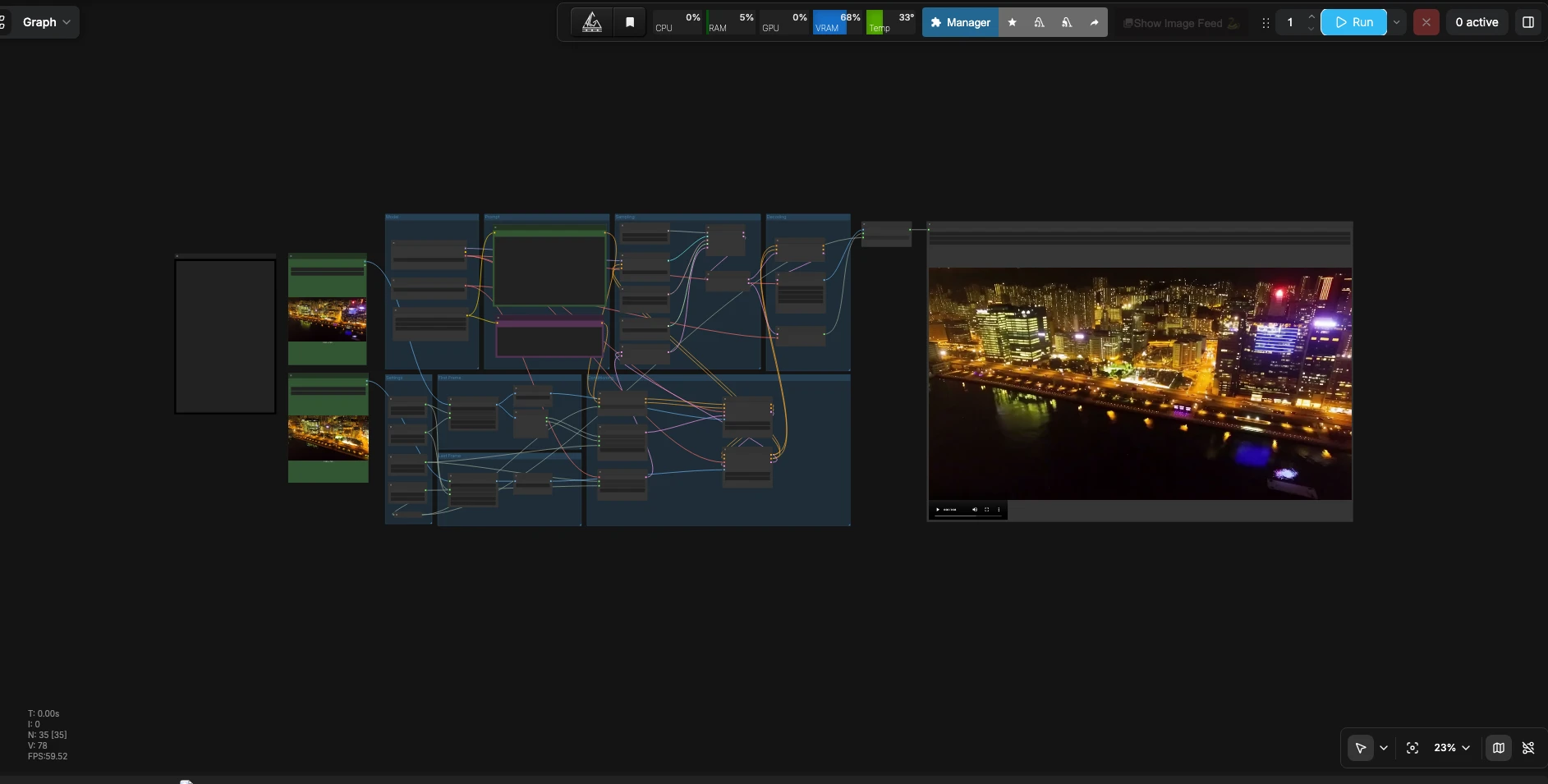
LTX 2.3 First Last Frame zu Video#
LTX 2.3 First Last Frame zu Video ist ein ComfyUI-Workflow, der zwei Standbilder in ein flüssiges, kontinuierliches Video mit synchronisiertem Audio verwandelt. Sie liefern ein erstes Bild, ein letztes Bild und eine in natürlicher Sprache verfasste Eingabe, die Bewegung, Szenendetails und Ton beschreibt. Angetrieben vom LTX-2.3 22B Distilled FP8 Checkpoint interpoliert die Pipeline zwischen den Bildern und bewahrt dabei das konsistente Erscheinungsbild und Timing. Es ist ideal für Editoren, Motion Designer und Storyboard-Künstler, die einen nahtlosen Übergang oder einen kurzen Loop-Clip direkt in ComfyUI erstellen müssen.
Dieser LTX 2.3 First Last Frame-Workflow legt den Schwerpunkt auf effiziente Inferenz und hohe Eingabetreue. FP8-Gewichte halten die VRAM-Nutzung im Zaum, während ein Gemma 3 12B Text-Encoder das semantische Verständnis für sowohl visuelle als auch akustische Anweisungen verbessert. Das Ergebnis ist ein kohärenter visueller Übergang vom ersten zum letzten Bild, der Ihre Eingabe respektiert und synchron mit dem generierten Audio bleibt.
Wichtige Modelle im ComfyUI LTX 2.3 First Last Frame-Workflow#
- LTX-2.3 22B Distilled FP8 Checkpoint von Lightricks. Kernmodell zur Videogenerierung, destilliert für effiziente Inferenz, hier verwendet, um zeitlich konsistente Frames zu synthetisieren, während es auf die beiden Bildanweisungen und die Texteingabe konditioniert wird. Model card
- Gemma 3 12B IT Text-Encoder. Bietet robustes Sprachverständnis für sowohl visuelle als auch akustische Aspekte der Eingabe, was genaue Bewegungs-, Szenenattribute und Soundtrack-Hinweise ermöglicht. Model card
- LTX-2.3 latente VAEs für Video und Audio. Diese Komponenten wandeln Bilder und Wellenform-Audio während der Dekodierung in kompakte Latents und zurück um, wobei die Qualität erhalten bleibt und das Sampling effizient bleibt. Geliefert mit der LTX-2.3 FP8-Veröffentlichung. Model card
Verwendung des ComfyUI LTX 2.3 First Last Frame-Workflows#
Dieser Workflow nimmt zwei Referenzbilder und eine Eingabe, baut eine Konditionierung mit ersten und letzten Bildanweisungen auf, sampelt ein Video-Latent mit synchronisiertem Audio und dekodiert alles in eine abspielbare Datei.
Einstellungen
- Stellen Sie Ihre Zielauflösung, Bildanzahl und Bildrate in der Einstellungsgruppe ein. Breite und Höhe definieren die Arbeitsfläche; die Eingabebilder werden angepasst, damit das Modell sauber interpolieren kann. Die Bildanzahl steuert, wie lange der Übergang dauert, und die Bildrate legt die Wiedergabegeschwindigkeit fest. Wählen Sie ein Seitenverhältnis, das zu Ihren Quellen passt, um unerwünschtes Zuschneiden zu vermeiden. Die Knoten
WIDTH(#113),HEIGHT(#98),Length(#102) undFrame Rate(int)(#114) verankern diese Entscheidungen.
Erstes Bild
- Laden Sie Ihr Startbild in
Load First Frame(#31). Es wird vonResizeImageMaskNode(#124) auf die Zielabmessungen angepasst und vonLTXVPreprocess(#104) normalisiert. Dies bereitet das erste Bild darauf vor, als starke strukturelle und farbliche Leitlinie zu Beginn des Clips zu dienen. Verwenden Sie ein scharfes, gut beleuchtetes Bild für beste Ergebnisse.
Letztes Bild
- Laden Sie Ihr Endbild in
Load Last Frame(#39). Das Bild wird mitResizeImageMaskNode(#125) auf die gleiche Größe angepasst und vonLTXVPreprocess(#99) normalisiert. Dies stellt das gewünschte endgültige Aussehen und Layout sicher, das Sie am Ende des Übergangs haben möchten. Für Loops machen Sie das letzte Bild visuell kompatibel mit dem ersten.
Eingabe
- Der
LTXAVTextEncoderLoader(#103) liefert den Text-Encoder, und zweiCLIPTextEncode-Knoten erfassen Ihre positiven und negativen Eingaben. In der positiven Eingabe (CLIPTextEncode(#128)) beschreiben Sie Kamerabewegung, Motive, Beleuchtung und fügen auch akustische Hinweise wie "Musik: Ambient-Pads mit sanfter Percussion" oder "Dialog: kurzes Flüstern" hinzu. Die negative Eingabe (CLIPTextEncode(#112)) kann Artefakte oder Merkmale auflisten, die Sie unterdrücken möchten.
Konditionierung
LTXVConditioning(#109) kombiniert die Textkonditionierung mit Zeitinformationen, damit Bewegung und Audio mit Ihrer gewählten Bildrate übereinstimmen.EmptyLTXVLatentVideo(#108) erstellt ein Video-Latent in Ihrer Auflösung und Länge. Zwei Durchläufe vonLTXVAddGuidefügen zunächst das erste Bild (LTXVAddGuide(#115)) und dann das letzte Bild (LTXVAddGuide(#111)) hinzu, damit das Modell weiß, wo es beginnen und wo es enden soll.LTXVEmptyLatentAudio(#101) initialisiert ein Audio-Latent von passender Dauer, undLTXVConcatAVLatent(#119) bündelt Audio- und Video-Latents zum Sampling.
Modell
CheckpointLoaderSimple(#127) lädt die LTX-2.3 22B destillierten FP8-Gewichte und das Video-VAE, währendLTXVAudioVAELoader(#126) das Audio-VAE bereitstellt. Diese sind vorkonfiguriert, sodass Sie sich auf kreative Eingaben konzentrieren können, anstatt auf Einrichtung.
Sampling
CFGGuider(#116) balanciert die Einhaltung Ihrer Text- und Bildanweisungen gegen kreative Freiheit.RandomNoise(#100) setzt einen Samen für Reproduzierbarkeit. Der Sampler verwendetSamplerEulerAncestral(#117) mit einem benutzerdefinierten Zeitplan vonManualSigmas(#118), orchestriert vonSamplerCustomAdvanced(#120), um das Latent schrittweise in eine kohärente Sequenz zu verfeinern, die Ihren Bewegungs- und Audioanweisungen folgt.
Dekodierung
- Nach dem Sampling trennt
LTXVSeparateAVLatent(#121) das kombinierte Latent wieder in Video und Audio.LTXVCropGuides(#106) verfeinert die räumliche Führung, um Kantenartefakte vor der Bilddekodierung zu reduzieren.VAEDecodeTiled(#105) erzeugt die Bildsequenz undLTXVAudioVAEDecode(#107) generiert die Audio-Wellenform.CreateVideo(#122) muxes Frames und Ton bei Ihrer ausgewählten fps undSaveVideo(#68) schreibt die endgültige Datei in Ihren ComfyUI-Ausgang.
Wichtige Knoten im ComfyUI LTX 2.3 First Last Frame-Workflow#
EmptyLTXVLatentVideo (#108)
- Definiert die Arbeitsauflösung und Dauer Ihres Clips. Passen Sie Breite, Höhe und Länge hier an, um die visuelle Skala und Übergangszeit einzustellen. Längere Dauern benötigen stärkere Bewegungsanweisungen in der Eingabe, um Stagnation zu vermeiden.
LTXVAddGuide (#115)
- Fügt das erste Bild als strukturelle und farbliche Anker am Anfang der Sequenz ein. Wenn der Beginn von Ihrer Quelle abweicht, erhöhen Sie den Einfluss dieses Guides; wenn es zu übermäßig eingeschränkt wirkt, reduzieren Sie ihn leicht, um mehr Bewegung zuzulassen.
LTXVAddGuide (#111)
- Verankert das Zielbild am Ende des Clips mit dem letzten Bild. Wenn der Übergang überschießt oder nie ganz auf Ihrem letzten Bild landet, erhöhen Sie den Guide-Einfluss; wenn es zu stark am Ende einrastet, verringern Sie ihn.
CFGGuider (#116)
- Kontrolliert, wie stark das Modell den Text- und Bildkonditionierungen folgt. Höhere Führung betont Ihre Eingaben und Guides, kann jedoch die Glätte reduzieren; niedrigere Werte fühlen sich freier an, können jedoch vom beabsichtigten Aussehen abweichen. Passen Sie in kleinen Schritten an und verwenden Sie denselben Samen, wenn Sie vergleichen.
SamplerCustomAdvanced (#120) mit SamplerEulerAncestral (#117) und ManualSigmas (#118)
- Treibt das Denoising mit einem konsistenten Zeitplan für stabile Bewegung an. Kürzere Zeitpläne rendern schneller, können aber rau sein; längere oder sanftere Zeitpläne verbessern die Konsistenz bei zusätzlichen Rechenkosten. Halten Sie den Zeitplan konsistent, wenn Sie andere Parameter A/B-testen.
CreateVideo (#122)
- Muxes dekodierte Frames und Audio in einen finalen Clip bei Ihrer gewählten Bildrate. Verwenden Sie dasselbe fps, das Sie konditioniert haben, damit Lippenformen, Schritte oder Musikpulse synchron bleiben.
Optionale Extras#
- Schreiben Sie Eingaben mit Verben und Timing: "Kamera fährt vorwärts", "Lichter dimmen, wenn wir uns nähern", "Musik: spärliches Klavier mit sanftem Nachhall." Klare Verben helfen der LTX 2.3 First Last Frame-Pipeline, Bewegung und Rhythmus zu erkennen.
- Passen Sie das Seitenverhältnis und die Ausrichtung Ihrer beiden Bilder an. Große Unterschiede können unerwünschtes Zuschneiden oder Dehnen verursachen.
- Für nahtlose Loops machen Sie das letzte Bild zu einem nahezu gleichen wie das erste und halten Sie die Kamerabewegung zyklisch.
- Verwenden Sie einen Samen in
RandomNoise, um ein Aussehen zu reproduzieren, während Sie an Eingaben oder Guide-Stärken arbeiten; ändern Sie den Samen, um neue Variationen zu erkunden. - Wenn Sie Implementierungsdetails oder benutzerdefinierte Knotenreferenzen benötigen, siehe ComfyUI’s LTX-Integrationen und Hilfsmittel wie ComfyUI-LTXTricks. Repository
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Lightricks für den LTX-2.3 22B Distilled FP8 Checkpoint, Google für den Gemma 3 12B IT FP4 Text-Encoder, logtd für ComfyUI-LTXTricks Custom Nodes und Comfy.org für den Comfy.org Official Workflow für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- Lightricks/LTX-2.3 22B Distilled FP8 Checkpoint
- Hugging Face: Lightricks/LTX-2.3-fp8
- Google/Gemma 3 12B IT FP4 Text Encoder
- Hugging Face: google/gemma-3-12b-it
- logtd/ComfyUI-LTXTricks Custom Nodes
- GitHub: logtd/ComfyUI-LTXTricks
- Comfy.org/Comfy.org Official Workflow
- Docs / Release Notes: comfy.org/workflows/video_ltx2_3_flf2v
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.
