
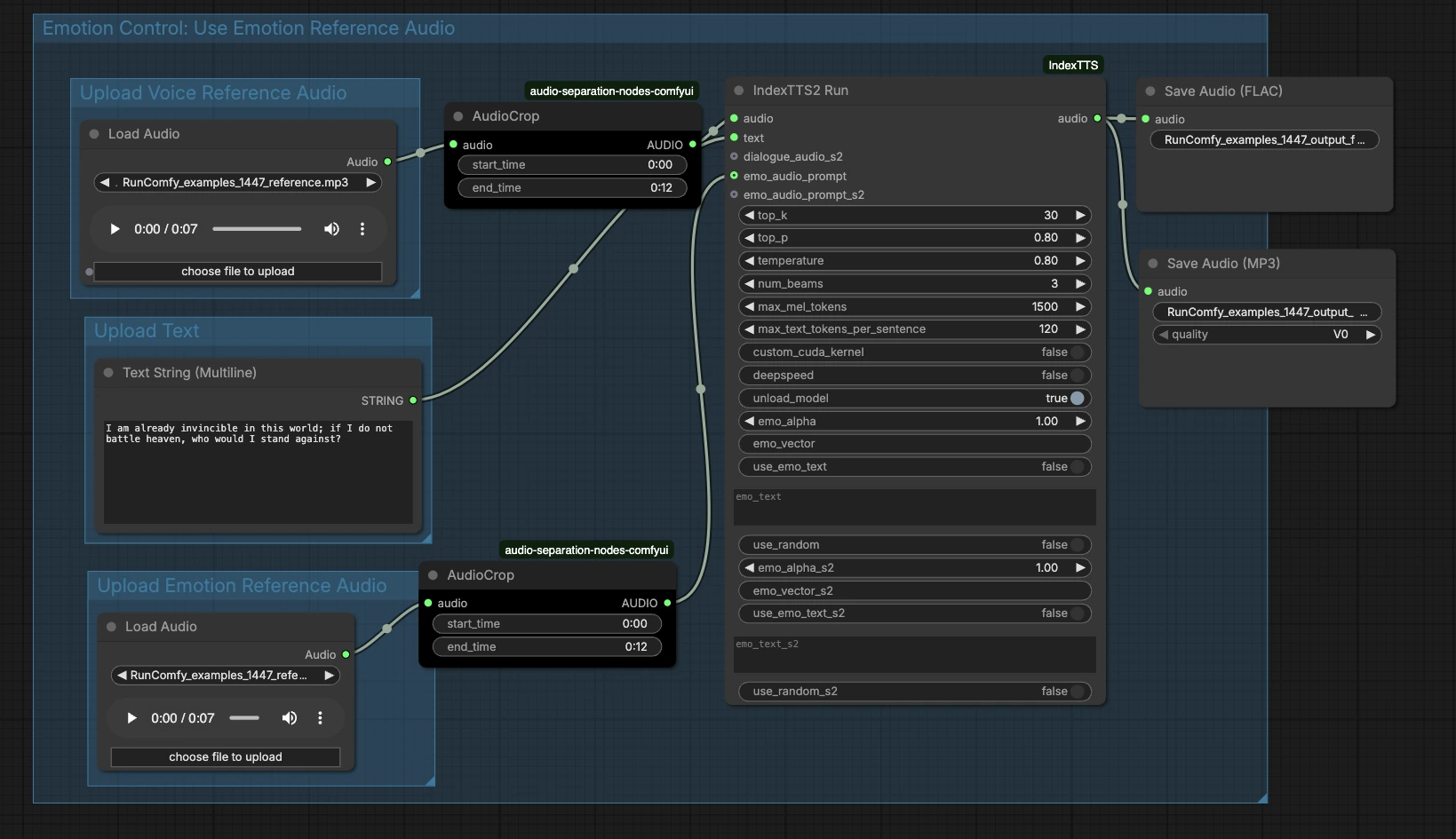
IndexTTS2 ComfyUI-Workflow: Emotionales Stimmenklonen mit Referenzaudio#
Dieser IndexTTS2 ComfyUI-Workflow verwandelt einen kurzen Referenzclip in natürliche, ausdrucksstarke Sprache, die den Klang und Stil des Sprechers widerspiegelt. Sie liefern sauberes Referenzaudio, optionale Emotionseingabe und Ihr Skript; das Diagramm generiert hochwertige Stimmklone und exportiert sie als FLAC zur Archivierung oder als MP3 für schnelles Teilen.
Basierend auf dem IndexTTS-2-Modell und ComfyUI IndexTTS-Knoten ist der Workflow ideal für Kreative, Charakterdesigner, Pädagogen und RunComfy-Nutzer, die schnelle, reproduzierbare emotionale TTS wünschen. Alles geschieht innerhalb von ComfyUI, sodass Sie Eingaben überprüfen, Einstellungen anpassen und schnell an Erzählungen, Dialogen und Voice-Over-Beispielen arbeiten können.
Wichtige Modelle im Comfyui IndexTTS2 ComfyUI-Workflow#
- IndexTTS-2 von IndexTeam. Ein modernes Text-zu-Sprache-System, das referenzbasiertes Stimmenklonen und ausdrucksstarke Prosodiekontrolle durchführt. Es konditioniert auf einem kurzen Sprecherbeispiel und optional auf Emotionen, um natürliche Sprache aus Text zu erzeugen. Siehe die Modellkarte auf Hugging Face und das begleitende Papier für architektonische und trainingstechnische Details: IndexTTS-2, IndexTTS-Projekt, IndexTTS-2 Papier.
So verwenden Sie den Comfyui IndexTTS2 ComfyUI-Workflow#
Auf hoher Ebene nimmt das Diagramm drei Eingaben – Referenzklangfarbe, Text und optionale Emotion – und führt die Generierung aus und exportiert das Ergebnis. Die unten gezeigten Gruppen zeigen, wo Eingaben hinzugefügt werden können und wie sie zur endgültigen Sprache führen.
Sprachreferenz-Audio hochladen#
Diese Gruppe bereitet die Sprecheridentität vor. Laden Sie ein sauberes Beispiel der Zielstimme in LoadAudio (#13), idealerweise einen einzelnen Sprecher, der klar spricht, ohne Musik oder Effekte. Verwenden Sie AudioCrop (#37), um ein stabiles Segment zu isolieren, damit das System eine konsistente Klangfarbe lernt. Kurze Segmente mit gleichmäßiger Tonhöhe und neutraler Darbietung erzeugen typischerweise die zuverlässigsten Klone. Die zugeschnittene Referenz wird weitergeleitet, um den Generator zu konditionieren.
Text hochladen#
Geben Sie Ihr Skript in PrimitiveStringMultiline (#14) ein. Klare Interpunktion hilft dem Modell, Pausen und Betonungen zu erkennen, also schreiben Sie den Text so, wie Sie ihn gesprochen haben möchten. Wenn Sie mehrsätzige Lesungen planen, halten Sie jeden Satz gut geformt und vermeiden Sie Emojis oder ungewöhnliche Symbole. Der Text fließt direkt in den Syntheseknoten zur Wiedergabe.
Emotionale Referenz-Audio hochladen#
Stellen Sie einen optionalen Clip bereit, der die gewünschte Emotion oder Darbietung einfängt – zum Beispiel aufgeregt, ruhig oder düster – über LoadAudio (#15). Schneiden Sie ihn mit AudioCrop (#38) zu, um nur den ausdrucksstarken Teil zu behalten, den Sie nachahmen möchten. Dies ist getrennt von der Klangfarbenreferenz und konzentriert sich auf Rhythmus, Energie und Ton. Wenn Sie diesen Schritt überspringen, verlässt sich der IndexTTS2 ComfyUI-Workflow nur auf den Text für die Prosodie.
Emotionale Kontrolle: Verwendung von emotionalem Referenzaudio#
Dieser Bereich verbindet Ihre Emotionseingabe mit dem Generator. Der zugeschnittene Emotionsclip speist den emo_audio_prompt Eingang auf IndexTTS2Run (#12), der Kadenz und Intensität leitet, während die Zielstimme erhalten bleibt. Sie können auch die Emotionstext-Steuerungen des Knotens verwenden, um den Stil zu beeinflussen, wenn Sie kein Emotionsaudio-Beispiel haben. In der Praxis tendieren Emotionsaudioclips dazu, stärkere, konsistentere Ausdruckskraft zu geben, während Emotionstext leichtere Steuerung bietet. Kombinieren Sie sie, wenn Sie sowohl ein konkretes Beispiel als auch einen textuellen Hinweis wünschen.
Erzeugen und Exportieren#
IndexTTS2Run (#12) synthetisiert Sprache unter Verwendung Ihres Textes, der Klangfarbenreferenz und etwaiger Emotionsführung. Die Ausgabe wird an SaveAudio (#17) für verlustfreies FLAC und an SaveAudioMP3 (#39) für eine kleine, webfreundliche Vorschau weitergeleitet. Verwenden Sie die Dateinamenfelder an den Speicher-Knoten, um Aufnahmen über Iterationen hinweg organisiert zu halten. Dieses Design erleichtert es, verschiedene Texte oder Emotionen zu vergleichen, während die gleiche Sprecheridentität beibehalten wird.
Wichtige Knoten im Comfyui IndexTTS2 ComfyUI-Workflow#
IndexTTS2Run (#12)#
Dies ist der Kern-Generator, der IndexTTS-2 umschließt und Steuerungen für Sampling, Balkensuche und Emotionskonditionierung bietet. Passen Sie top_p, top_k und temperature an, um Stabilität und Vielfalt auszugleichen – niedrigere Werte liefern konsistentere Lesungen, höhere Werte erhöhen die Spontaneität. Verwenden Sie num_beams, wenn Sie möchten, dass der Knoten mehr Kandidatenlesungen sucht, wobei Geschwindigkeit gegen Qualität getauscht wird. Für lange Skripte helfen max_mel_tokens und max_text_tokens_per_sentence, Überläufe zu verhindern, indem sie Audio- und Textgrößen begrenzen. Emotionen können mit emo_audio_prompt, emo_alpha für Mischstärke oder mit use_emo_text und emo_text gesteuert werden, wenn Sie einen textuellen Hinweis bevorzugen. Leistungshelfer wie deepspeed, custom_cuda_kernel und unload_model sind je nach Hardware verfügbar. Die Knotenimplementierung wird von den ComfyUI IndexTTS-Benutzerdefinierten Knoten bereitgestellt: ComfyUI_IndexTTS, und das zugrunde liegende Modell ist hier dokumentiert: IndexTTS-2, IndexTTS-Projekt.
AudioCrop (#37) — Referenzklangfarbe#
Verwenden Sie diesen Knoten, um einen sauberen, stabilen Ausschnitt aus Ihrem Sprecherbeispiel zu isolieren. Vermeiden Sie Hintergrundgeräusche, Lachen oder extreme Emotionen, da diese Details in die geklonte Stimme durchsickern können. Das Zuschneiden auf einen konsistenten Ton verbessert die Identitätssperre und reduziert unerwünschte Artefakte.
AudioCrop (#38) — Emotionseingabe#
Dieser Ausschnitt wählt den ausdrucksstarken Hinweis, der die Darbietung steuert. Wählen Sie einen Abschnitt mit dem genauen Rhythmus oder der Intensität, die Sie wünschen, und halten Sie ihn prägnant, um das Signal nicht zu verwässern. Für beste Kohärenz verwenden Sie Emotionseingaben vom gleichen Sprecher wie die Klangfarbenreferenz, wenn möglich.
Optionale Extras#
- Halten Sie das Referenzaudio trocken und monophon; entfernen Sie Hall, Hintergrundmusik und starke Kompression für saubereres Klonen.
- Setzen Sie bewusst Interpunktion. Kommas, Punkte und Fragezeichen helfen dem Modell, Pausen und Betonungen zu setzen, die Ihrer Absicht entsprechen.
- Für reproduzierbare Aufnahmen deaktivieren Sie die Zufälligkeit im Knoten oder führen Sie Notizen zu Text- und Audioauswahlen, damit Sie später die gleiche Ausgabe regenerieren können.
- Wenn der VRAM knapp ist, aktivieren Sie das Entladen des Modells zwischen den Läufen; es kann einen kleinen Zeitaufwand hinzufügen, aber Speicher für andere Diagramme freisetzen.
- Respektieren Sie Stimmrechte. Verwenden Sie nur Referenzaufnahmen, die Sie berechtigt sind zu klonen, und geben Sie synthetische Sprache an, wo erforderlich.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken RunningHub für das Workflow-Referenz, RunComfy für den Cloud-Speicher-Workflow, Index Team für IndexTTS und IndexTTS-2, den Autoren des IndexTTS2-Papiers und billwuhao für die ComfyUI IndexTTS-Benutzerdefinierten Knoten für ihre Beiträge und Wartung. Für autoritative Details lesen Sie bitte die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- RunningHub/Workflow-Referenz
- Dokumente / Versionshinweise: RunningHub post
- RunComfy/Cloud-Speicher-Workflow
- Dokumente / Versionshinweise: RunComfy workflow
- index-tts/index-tts
- GitHub: index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face: IndexTeam/IndexTTS-2
- IndexTTS2/Paper
- arXiv: 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub: billwuhao/ComfyUI_IndexTTS
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den entsprechenden Lizenzen und Bedingungen der jeweiligen Autoren und Betreuer.