
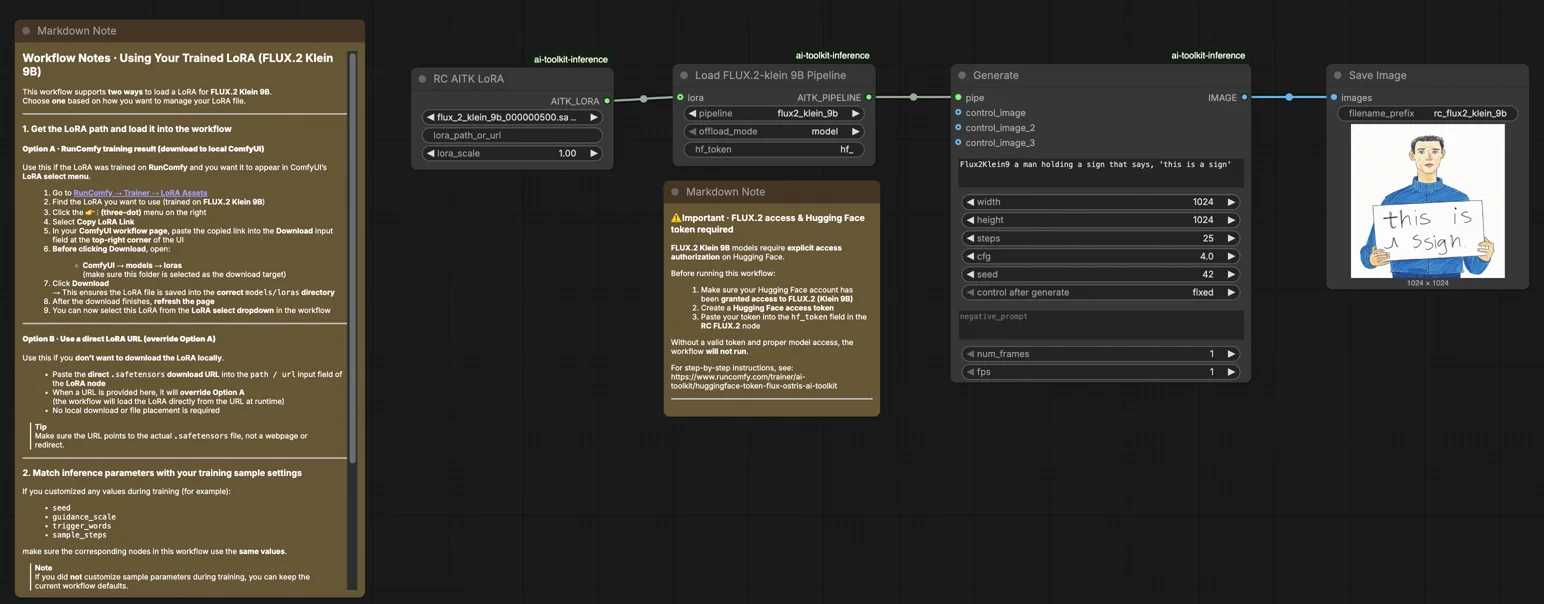
FLUX.2 Klein 9B LoRA ComfyUI Inferenz: Vorschau-abgestimmte AI Toolkit LoRA-Generierung in ComfyUI#
Verwenden Sie diesen RunComfy-Workflow, wenn Sie eine ComfyUI-Inferenz benötigen, die mit den AI Toolkit Trainingsvorschauen für FLUX.2 Klein 9B LoRAs konsistent bleibt. Das Setup leitet die Generierung durch Flux2Klein9BPipeline—einen modellspezifischen Pipeline-Wrapper open-sourced by RunComfy—anstatt eines Standard-Sampler-Graphen. Ihr Adapter wird über lora_path und lora_scale innerhalb dieser Pipeline angewendet, was Ihnen trainingsabgestimmtes LoRA-Verhalten ohne manuelle Pipeline-Rekonstruktion bietet.
Warum FLUX.2 Klein 9B LoRA ComfyUI Inferenz oft anders in ComfyUI aussieht#
Wenn das AI Toolkit eine Trainingsvorschau rendert, läuft die vollständige FLUX.2 Klein 9B Inferenzpipeline—Qwen3-8B Textkodierung, Fluss-Match-Planung und interne LoRA-Injektion geschehen als koordinierte Einheit. Ein typischer ComfyUI-Graph setzt diese Komponenten unabhängig zusammen, was subtile Unterschiede in Konditionierung, Rauschplanung und Adapteranwendungsreihenfolge einführt. Das Ergebnis ist eine Pipeline-Ebene-Drift, kein einzelner falsch konfigurierter Knopf. Flux2Klein9BPipeline überbrückt diese Lücke, indem sie die eigene Pipeline des Modells von Anfang bis Ende ausführt und Ihre LoRA darin injiziert. Referenz: `src/pipelines/flux2_klein.py`.
Wie man den FLUX.2 Klein 9B LoRA ComfyUI Inferenz-Workflow verwendet#
Schritt 1: Holen Sie sich den LoRA-Pfad und laden Sie ihn in den Workflow (2 Optionen)#
Option A — RunComfy Trainingsergebnis > Download auf lokales ComfyUI:
- Gehen Sie zu Trainer > LoRA Assets
- Finden Sie die FLUX.2 Klein 9B LoRA, die Sie verwenden möchten
- Klicken Sie auf das ... (Drei-Punkte) Menü rechts > wählen Sie LoRA-Link kopieren
- Auf der ComfyUI-Workflow-Seite, fügen Sie den kopierten Link in das Download-Eingabefeld in der oberen rechten Ecke der Benutzeroberfläche ein
- Bevor Sie auf Download klicken, stellen Sie sicher, dass der Zielordner auf ComfyUI > models > loras eingestellt ist (dieser Ordner muss als Download-Ziel ausgewählt sein)
- Klicken Sie auf Download — die LoRA-Datei wird im richtigen
models/lorasVerzeichnis gespeichert - Nachdem der Download abgeschlossen ist, aktualisieren Sie die Seite
- Die LoRA erscheint jetzt im LoRA-Auswahl-Dropdown — wählen Sie sie aus

Option B — Direkte LoRA URL (überschreibt Option A):
- Fügen Sie die direkte
.safetensorsDownload-URL in daspath / urlEingabefeld des LoRA-Knotens ein - Wenn hier eine URL angegeben wird, überschreibt sie Option A — der Workflow ruft die LoRA direkt von der URL zur Laufzeit ab
- Kein lokales Herunterladen oder Dateiablage ist erforderlich
Tipp: Bestätigen Sie, dass die URL zur tatsächlichen .safetensors Datei führt, nicht zu einer Zielseite oder Umleitung.

Schritt 2: Inferenzparameter mit Ihren Trainingsmuster-Einstellungen abgleichen#
Setzen Sie lora_scale auf dem LoRA-Knoten, um die Adapterstärke zu kontrollieren—beginnen Sie mit dem Wert, den Sie während der Trainingsvorschauen verwendet haben, und passen Sie von dort aus an.
Die verbleibenden Parameter befinden sich auf den Generate und Load Pipeline Knoten:
prompt— Ihr Text-Prompt; enthalten Sie alle Triggerwörter aus dem Trainingwidth/height— Ausgabeauflösung; passen Sie Ihre Trainingsvorschau-Größe für einen direkten Vergleich an (Vielfache von 16)sample_steps— Inferenzschritte; FLUX.2 Klein 9B Standard ist 25guidance_scale— CFG-Stärke; der Standard ist 4.0 (Klein 9B ist nicht guidance-distilled, daher beeinflusst dieser Wert direkt die Ausgabequalität)seed— Fixieren Sie einen Seed, um eine spezifische Ausgabe zu reproduzieren; ändern Sie ihn, um Variationen zu erkundenseed_mode—fixedoderrandomizehf_token— ein gültiger Hugging Face Token ist erforderlich, da FLUX.2 Klein 9B ein gesperrtes Modell ist; fügen Sie Ihren Token in dashf_tokenFeld auf dem Load Pipeline-Knoten ein
Training-Ausrichtungstipp: Wenn Sie während des Trainings Abtastwerte angepasst haben (Seed, guidance_scale, sample_steps, Triggerwörter), kopieren Sie diese genauen Werte in die entsprechenden Felder. Wenn Sie auf RunComfy trainiert haben, öffnen Sie Trainer > LoRA Assets > Config, um das aufgelöste YAML anzuzeigen und Vorschau-/Abtasteinstellungen zu übertragen.

Schritt 3: FLUX.2 Klein 9B LoRA ComfyUI Inferenz ausführen#
Klicken Sie auf Queue/Run — der SaveImage-Knoten schreibt die Ergebnisse in Ihren ComfyUI-Ausgabeordner.
⚠️ Wichtig · FLUX.2 Zugriff & Hugging Face Token erforderlich#
FLUX.2 Klein 9B Modelle erfordern explizite Zugriffsautorisierung auf Hugging Face.
Bevor Sie diesen Workflow ausführen:
- Stellen Sie sicher, dass Ihrem Hugging Face-Konto Zugriff auf FLUX.2 (Klein 9B) gewährt wurde
- Erstellen Sie einen Hugging Face Zugriffstoken
- Fügen Sie Ihren Token in das
hf_tokenFeld im RC FLUX.2 Knoten ein
Ohne einen gültigen Token und ordnungsgemäßen Modellzugriff wird der Workflow nicht ausgeführt.
Für Schritt-für-Schritt-Anleitungen siehe: https://www.runcomfy.com/trainer/ai-toolkit/huggingface-token-flux-ostris-ai-toolkit
Schnell-Checkliste:
- ✅ Hugging Face-Konto hat FLUX.2 Klein 9B Zugriff und ein gültiger Token ist in
hf_token - ✅ LoRA ist entweder: heruntergeladen in
ComfyUI/models/loras(Option A), oder über eine direkte.safetensorsURL geladen (Option B) - ✅ Seite nach lokalem Download aktualisiert (nur Option A)
- ✅ Inferenzparameter stimmen mit Trainings-
sample-Konfiguration überein (wenn angepasst)
Wenn alles oben Genannte korrekt ist, sollten die Inferenzresultate hier eng mit Ihren Trainingsvorschauen übereinstimmen.
Fehlerbehebung FLUX.2 Klein 9B LoRA ComfyUI Inferenz#
Die meisten „Trainingsvorschau vs ComfyUI Inferenz“-Lücken auf FLUX.2 Klein 9B entstehen durch Unterschiede auf Pipeline-Ebene (Textkodiererpfad, Scheduler/Konditionierung und wo/wie der Adapter angewendet wird). Der RunComfy-Workflow vermeidet es, die Pipeline manuell wieder aufzubauen, indem er die Generierung durch Flux2Klein9BPipeline laufen lässt und die LoRA innerhalb dieser Pipeline über lora_path / lora_scale injiziert, was der nächstgelegene Weg ist, um das AI Toolkit Vorschauverhalten in ComfyUI zu reproduzieren.
(1) 401 Client Error.#
Warum das passiert FLUX.2 Klein 9B ist ein gesperrtes Hugging Face Modell. Wenn Ihr Konto keinen Zugriff hat oder kein gültiger Token bereitgestellt wird, können Modellgewichte nicht heruntergeladen werden und die Inferenz schlägt mit einem 401-Fehler fehl.
Wie man es behebt
- Stellen Sie sicher, dass Ihrem Hugging Face-Konto Zugriff gewährt wurde auf
black-forest-labs/FLUX.2-klein-base-9B. - Erstellen Sie einen Hugging Face Zugriffstoken und fügen Sie ihn in das
hf_tokenFeld auf dem Load Pipeline Knoten ein. - Nachdem Zugriff und Token bestätigt wurden, führen Sie die Inferenz durch die RunComfy AI Toolkit-Pipeline-Knoten aus, sodass Authentifizierung und Modellladung in einer konsistenten Pipeline geschehen.
- Für Schritt-für-Schritt-Anleitungen siehe: https://www.runcomfy.com/trainer/ai-toolkit/huggingface-token-flux-ostris-ai-toolkit
(2) Flux 2 Klein Modelle CLIPLoader Fehler#
Warum das passiert Diese Fehler werden durch eine Textkodierer-Fehlanpassung verursacht—zum Beispiel das Laden eines inkompatiblen Kodierers oder das Mischen von Klein 4B und Klein 9B Kodierer-Assets. Dies erscheint oft als Einbettungs- oder Vokabulargrößenfehler während des CLIP/Text-Kodierer-Ladens.
Wie man es behebt
- Aktualisieren Sie ComfyUI auf die neueste Version, um die vollständige Unterstützung von FLUX.2 Klein zu gewährleisten.
- Stellen Sie sicher, dass der korrekte Textkodierer für Klein 9B verwendet wird (Klein 9B erfordert Qwen3-8B; die Verwendung eines 4B-Kodierers wird fehlschlagen).
- Für Vorschau-abgestimmte LoRA-Inferenz bevorzugen Sie den RunComfy-Pipeline-Wrapper, der den richtigen Kodierer lädt und die LoRA in der gleichen Pipeline anwendet, die für AI Toolkit Vorschauen verwendet wird.
(3) mat1 und mat2 Formen können nicht multipliziert werden (512x2560 und 7680x3072)#
Warum das passiert Dieser Fehler weist auf eine Konditionierungsdimensions-Fehlanpassung hin, typischerweise verursacht durch die Verwendung des falschen Kodierers oder eines falschen Clip/Konditionierungstyps für FLUX.2 Klein 9B. Das Modell erhält Einbettungen der falschen Form, was dazu führt, dass die Matrixmultiplikation während des Samplings fehlschlägt.
Wie man es behebt
- Wenn Sie Graphen manuell erstellen, verifizieren Sie, dass Sie den FLUX.2 Klein–spezifischen Textkodierer verwenden und dass der Clip/Konditionierungstyp den Erwartungen von FLUX.2 Klein entspricht.
- Für die zuverlässigste Lösung führen Sie die Inferenz durch den RunComfy FLUX.2 Klein 9B Pipeline-Wrapper (
model_type = flux2_klein_9b) aus und injizieren Sie Ihre LoRA überlora_path. Dies hält den gesamten Inferenzstapel—Kodierer, Scheduler und Adapter—pipeline-abgestimmt mit AI Toolkit Vorschauen.
Führen Sie jetzt FLUX.2 Klein 9B LoRA ComfyUI Inferenz aus#
Laden Sie den Workflow, fügen Sie Ihren lora_path ein, geben Sie einen gültigen hf_token ein und lassen Sie Flux2Klein9BPipeline die ComfyUI-Ausgabe mit Ihren AI Toolkit Trainingsvorschauen abgestimmt halten.