
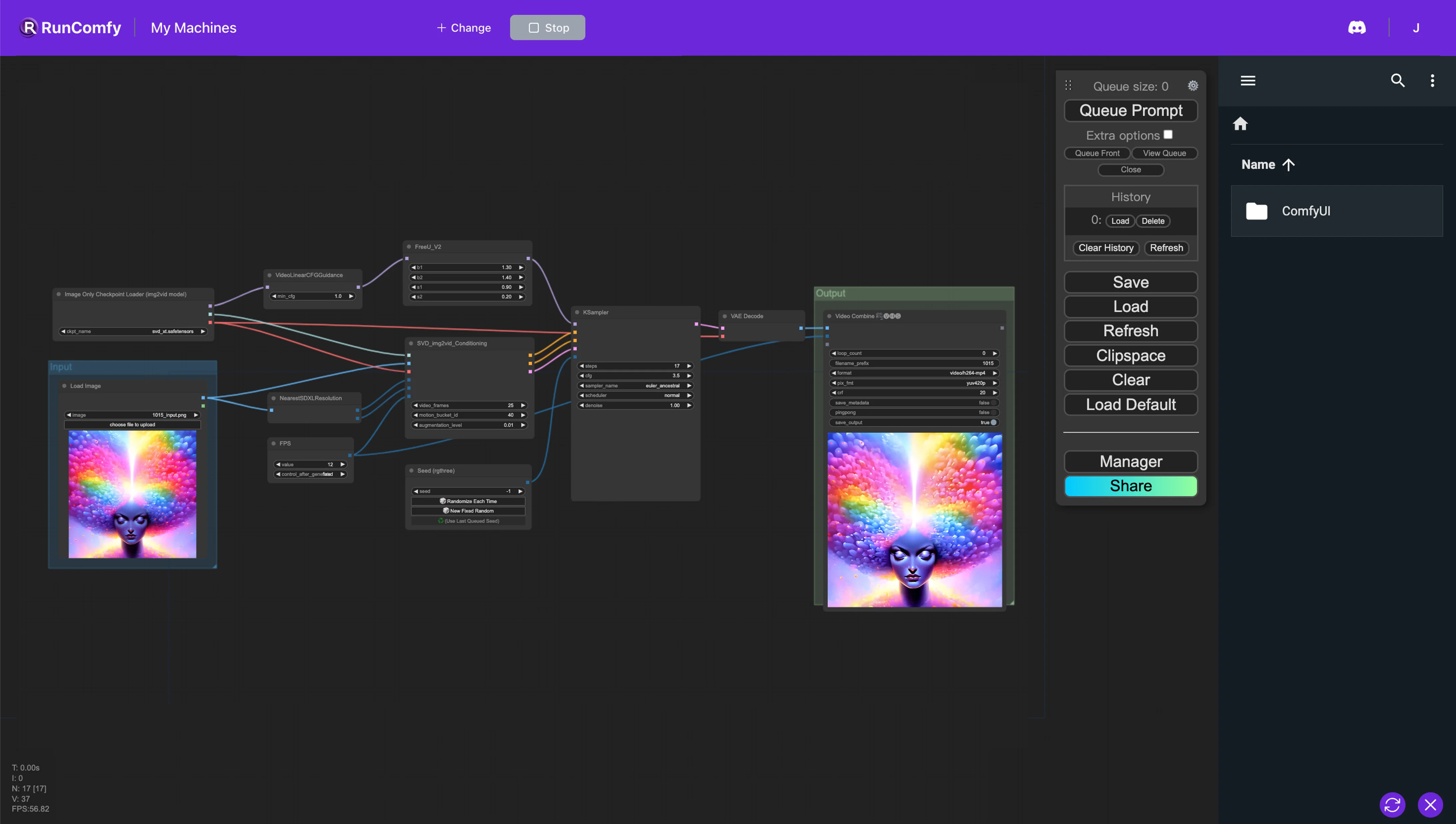
1. ComfyUI Stable Video Diffusion (SVD) und FreeU Workflow#
Dieser ComfyUI-Workflow ermöglicht eine optimierte Pipeline zur Bild-zu-Video-Konvertierung durch den Einsatz von Stable Video Diffusion (SVD) zusammen mit FreeU für eine verbesserte Ausgabequalität. FreeU verbessert die Ergebnisse des Diffusionsmodells, ohne zusätzlichen Aufwand zu verursachen—es ist kein erneutes Training, keine Parametererhöhung und keine Erhöhung von Speicher oder Rechenzeit erforderlich. Diese Integration stellt sicher, dass Sie eine höhere Wiedergabetreue in Video-Outputs erreichen können.
2. Übersicht über Stable Video Diffusion (SVD)#
Bitte lesen Sie die Details in der Einführung in SVD
3. Übersicht über FreeU#
Bitte lesen Sie die Details in dieser Einführung in FreeU