
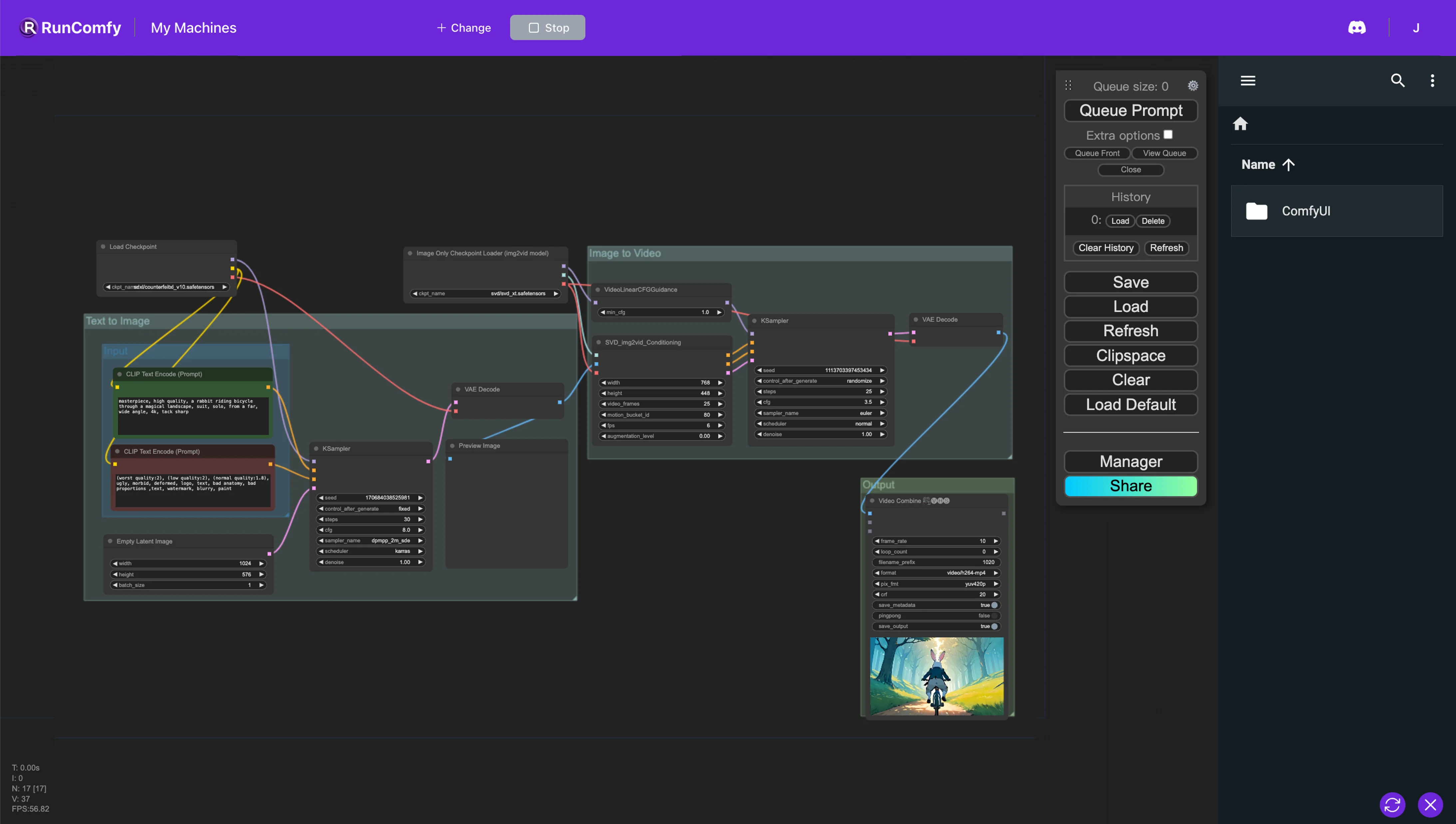
1. ComfyUI Stable Video Diffusion (SVD) Workflow#
Der ComfyUI-Workflow integriert nahtlos Text-zu-Bild- (Stable Diffusion) und Bild-zu-Video-Technologien (Stable Video Diffusion) für eine effiziente Text-zu-Video-Konvertierung. Dieser Workflow ermöglicht es Ihnen, Videos direkt aus Textbeschreibungen zu generieren, beginnend mit einem Basisbild, das sich zu einer dynamischen Videosequenz entwickelt. Dieser Workflow erleichtert die Realisierung von Text-zu-Video-Animationen oder -Videos.
2. Übersicht über Stable Video Diffusion (SVD)#
2.1. Einführung in Stable Video Diffusion (SVD)#
Stable Video Diffusion (SVD) ist eine hochmoderne Technologie, die entwickelt wurde, um statische Bilder in dynamische Videoinhalte umzuwandeln. Durch die Nutzung des grundlegenden Stable Diffusion-Bildmodells führt SVD Bewegung in Standbilder ein und erleichtert so die Erstellung kurzer Videoclips. Dieser Fortschritt bei latenten Diffusionsmodellen, die ursprünglich für die Bildsynthese entwickelt wurden, beinhaltet nun zeitliche Dimensionen, um statische Bilder zu animieren und Videos zu erstellen, die typischerweise im Bereich von 2 bis 5 Sekunden liegen.
Stable Video Diffusion ist in zwei Varianten verfügbar: das Standard-SVD, das in der Lage ist, Videos mit einer Auflösung von 576×1024 Pixeln über 14 Frames zu generieren, und das erweiterte SVD-XT, das bis zu 25 Frames produzieren kann. Beide Varianten unterstützen einstellbare Bildfrequenzen von 3 bis 30 Frames pro Sekunde und erfüllen damit verschiedene Anforderungen an die Erstellung digitaler Inhalte.
Das Training des SVD-Modells beinhaltet einen dreistufigen Prozess: beginnend mit einem Bildmodell, übergehend zu einem Videomodell, das mit einem umfangreichen Videodatensatz vortrainiert wurde, und verfeinert mit einer Auswahl hochwertiger Videoclips. Dieser sorgfältige Prozess unterstreicht die Bedeutung der Datenqualität bei der Optimierung der Videoproduktionsfähigkeiten des Modells.
Im Mittelpunkt des Stable Video Diffusion-Modells steht das Stable Diffusion 2.1-Bildmodell, das als grundlegendes Bildrückgrat fungiert. Die Integration von temporalen Faltungs- und Aufmerksamkeitsschichten in den U-Net-Rauschschätzer entwickelt dieses zu einem leistungsstarken Videomodell, das latente Tensoren als Videosequenzen interpretiert. Dieses Modell verwendet eine umgekehrte Diffusion, um alle Frames gleichzeitig zu entrauschen, ähnlich wie das VideoLDM-Modell.
Ausgestattet mit 1,5 Milliarden Parametern und trainiert auf einem riesigen Videodatensatz, wird das Modell mit einem hochwertigen Videodatensatz weiter verfeinert, um Spitzenleistungen zu erzielen. Zwei Sätze von SVD-Modellgewichten sind öffentlich zugänglich und für die Erzeugung von 14-Frame- bzw. 25-Frame-Videos mit einer Auflösung von 576×1024 konzipiert.
2.2. Hauptmerkmale von Stable Video Diffusion (SVD)#
Wenn Sie Stable Video Diffusion im ComfyUI-Workflow verwenden, können Sie die Schlüsselparameter für die Anpassung der Videoausgabe einstellen, darunter die Motion Bucket ID, die die Bewegungsintensität des Videos steuert, die Frames pro Sekunde (fps), die die Bildfrequenz bestimmen, und den Augmentationsgrad, der den Rauschpegel des Ausgangsbildes anpasst, um verschiedene Transformationsgrade zu ermöglichen.
2.2.1. Motion Bucket ID: Diese Funktion bietet Benutzern die Möglichkeit, die Bewegungsintensität des Videos zu steuern. Durch Anpassen dieses Parameters können Sie die Bewegungsmenge im Video festlegen, von subtilen Gesten bis hin zu ausgeprägteren Aktionen, abhängig vom gewünschten visuellen Effekt.
2.2.2. Frames pro Sekunde (fps): Dieser Parameter ist entscheidend für die Bestimmung der Wiedergabegeschwindigkeit des Videos. Durch Anpassung der Bilder pro Sekunde können Sie Videos erstellen, die entweder die schnelle Dynamik einer Szene einfangen oder einen Zeitlupeneffekt erzeugen und so den Erzählaspekt des Videoinhalts verbessern. Diese Flexibilität ist besonders vorteilhaft für die Erstellung einer Vielzahl von Videotypen, von schnellen Werbespots bis hin zu kontemplativen, erzählungsgetriebenen Stücken.
2.2.3. Augmentationsgradparameter: Dieser Parameter passt den Rauschpegel des Ausgangsbildes an und ermöglicht verschiedene Transformationsgrade. Durch Manipulation dieses Parameters können Sie steuern, inwieweit das Originalbild während des Videoerstellungsprozesses verändert wird. Die Anpassung des Augmentationsgrads ermöglicht es, eine engere Treue zum Originalbild beizubehalten oder sich auf abstraktere und künstlerischere Interpretationen einzulassen und so die kreativen Möglichkeiten zu erweitern.