
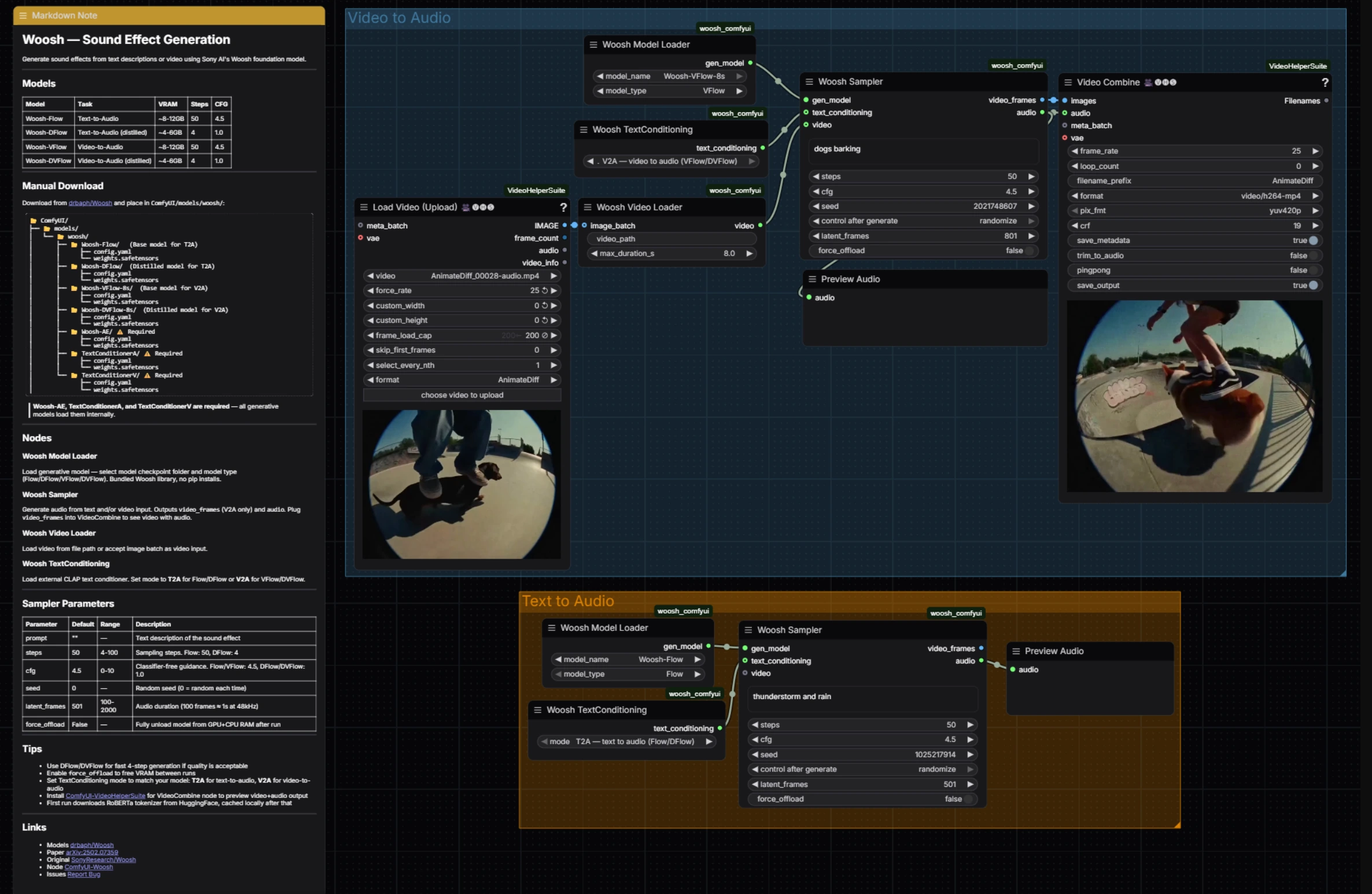
Woosh 音效生成:在 ComfyUI 中基於提示和視頻條件的音頻#
Woosh 音效生成是一個 ComfyUI 工作流程,利用 Sony Research 的 Woosh 基礎模型,將文本提示或視頻剪輯轉換為精緻的音效。它為需要一個基於提示的 Foley、緊密匹配視頻的音效設計,以及快速切換高質量和快速蒸餾變體的創作者而設計。
該工作流程公開了 Woosh 模型的兩個系列:Flow/DFlow 用於文本到音頻,VFlow/DVFlow 用於視頻到音頻。共享的取樣器驅動兩條路徑的生成,輸出音頻以供即時預覽,而在視頻路徑中,幀預覽被重新組合以快速生成日誌。在底層,它依賴於官方的 ComfyUI Woosh 節點和 VideoHelperSuite 進行無縫的視頻 IO,因此 Woosh 音效生成保持快速和簡單,同時保持靈活性。參考資料:SonyResearch/Woosh,drbaph/Woosh on Hugging Face,paper,ComfyUI-Woosh,ComfyUI-VideoHelperSuite。
Comfyui Woosh 音效生成工作流程中的關鍵模型#
- Sony Research Woosh — Flow:核心文本到音頻生成器,用於高保真 Foley 和環境音,通過流匹配目標進行訓練。參見 SonyResearch/Woosh 和 paper。
- Sony Research Woosh — DFlow:優化速度的蒸餾文本到音頻模型,具有更少的取樣步驟,適合快速迭代。權重可通過 drbaph/Woosh 獲得。
- Sony Research Woosh — VFlow‑8s:視頻條件生成器,將音頻開始和紋理與視覺運動提示同步,用於視頻到音頻。參見 SonyResearch/Woosh。
- Sony Research Woosh — DVFlow‑8s:蒸餾視頻到音頻模型,用於實時精簡工作流程和快速預覽。權重:drbaph/Woosh。
- Woosh‑AE:音頻自編碼器,用於從模型潛在變量重建波形;所有生成器都需要。權重:drbaph/Woosh。
- TextConditionerA 和 TextConditionerV:文本條件模塊,適當地嵌入提示,用於文本到音頻或視頻到音頻運行。詳細信息和用法在 ComfyUI-Woosh 和 paper 中記錄。
如何使用 Comfyui Woosh 音效生成工作流程#
該工作流程有兩個可以獨立運行的平行組:視頻到音頻,用於視覺匹配的音效設計;文本到音頻,用於純提示的 Foley。兩者在相同的取樣器邏輯和快速音頻預覽上匯聚,使 Woosh 音效生成無論輸入如何都能一致運行。
視頻到音頻#
視頻到音頻組加載剪輯,對齊幀和條件,然後生成同步音效。首先將剪輯輸入 VHS_LoadVideo (#34);它以您選擇的速率提取幀,這樣下游節點就能看到乾淨的、有界的序列。這些幀由 WooshLoadVideo (#37) 打包為視頻條件流,標準化持續時間,使生成器接收穩定的窗口。
在 WooshLoadFlow (#7) 中選擇視頻條件模型,通常選擇 VFlow 以獲得保真度,或選擇 DVFlow 以獲得速度。為取樣器提供一個簡短的描述性提示(用於風格或意圖),並將 WooshTextEncode (#19) 設置為 V2A,以便文本嵌入正確的條件分支。運行 WooshSample (#38) 以合成音頻;它輸出 audio 給 PreviewAudio (#9) 和 video_frames,流入 VHS_VideoCombine (#33) 以快速拼接預覽,保持 Woosh 音效生成緊湊以供編輯審查。
文本到音頻#
文本到音頻組專注於純提示驅動的生成。在 WooshLoadFlow (#40) 中選擇一個模型,當您需要最大質量時使用 Flow,當您需要非常快速、迭代的通過時使用 DFlow。將 WooshTextEncode (#41) 設置為 T2A,以便您的提示嵌入文本專用生成。將您的描述輸入 WooshSample (#39) 並執行;結果被發送到 PreviewAudio (#43) 以供即時聆聽。當您在沒有畫面的情況下創建庫或分層效果時,這條路徑保持 Woosh 音效生成輕量。
Comfyui Woosh 音效生成工作流程中的關鍵節點#
WooshSample (#38)#
視頻條件生成的中央取樣器。調整提示以引導風格和開始,然後調整 steps 以獲得質量與速度的權衡(在運行 DVFlow 時使用更少的步驟)。cfg 控制提示的遵循程度,latent_frames 決定輸出長度,以便匹配或有意偏移剪輯。設置 seed 以重現採樣,當您需要在長時間運行之間清除內存時,啟用 force_offload。節點實現和行為遵循官方的 ComfyUI-Woosh。
WooshSample (#39)#
文本到音頻的取樣器,具有相同的控制和行為,減去視頻流。為快速創意選擇 DFlow 和低 steps;為最終切換到 Flow 並提高 steps 以獲得細節。保持 cfg 適中以獲得自然的紋理,稍微提高以獲得風格化、提示鎖定的效果。使用 latent_frames 精確設置持續時間,當為庫或 DAW 時間軸構建資產時。
WooshLoadFlow (#7)#
視頻到音頻路徑的模型選擇器。選擇 VFlow 以獲得最高保真度的運動對齊,或在需要近乎實時預覽時選擇 DVFlow。確保 WooshTextEncode 設置為 V2A,以便嵌入匹配所選的模型系列。參見 drbaph/Woosh 以獲取模型變體。
WooshLoadFlow (#40)#
文本到音頻路徑的模型選擇器。選擇 Flow 以獲得豐富的細節和更廣泛的紋理變化,或選擇 DFlow 以最小步驟進行快速迭代。將其與 T2A 模式中的 WooshTextEncode 配對,以避免條件不匹配。節點行為和選項遵循官方的 ComfyUI-Woosh。
VHS_VideoCombine (#33)#
用於將生成的 audio 與取樣器的 video_frames 預覽組合以生成可審查的剪輯的實用工具。使用它來檢查同步,評估過渡,並在不離開 ComfyUI 的情況下共享日誌。屬於 ComfyUI-VideoHelperSuite。
可選附加項#
- 使用 DVFlow/DFlow 進行快速偵察通過,然後在 Woosh 音效生成必須閃耀時切換到 VFlow/Flow 以獲得最終效果。
- 保持輸入剪輯在所選模型的窗口內(例如,8 秒的 VFlow 變體),並在重疊的塊中處理更長的場景,您可以進行交叉淡入淡出。
- 保持從
VHS_LoadVideo到VHS_VideoCombine的一致幀率,以減少音頻和畫面之間的漂移。 - 對於提示,將動作詞與紋理和聲學背景(例如,“在混凝土樓梯間的快速金屬呼嘯聲”)配對,以獲得可預測的結果。
- 在取樣器中打開
force_offload,以備在 GPU 記憶體緊張時,進行繁重運行之間的內存清除。
致謝#
此工作流程實現並建立在以下作品和資源的基礎上。我們感謝 Sony Research 提供的 Woosh(項目和論文),Saganaki22 提供的 ComfyUI-Woosh (ComfyUI 節點),以及 Kosinkadink 提供的 ComfyUI-VideoHelperSuite 的貢獻和維護。欲了解權威細節,請參考以下鏈接的原始文檔和存儲庫。
資源#
- Saganaki22/ComfyUI-Woosh
- GitHub: Saganaki22/ComfyUI-Woosh
- drbaph/Woosh
- Hugging Face: drbaph/Woosh
- SonyResearch/Woosh
- GitHub: SonyResearch/Woosh
- Sony Research/Woosh (paper)
- arXiv: 2502.07359
- Kosinkadink/ComfyUI-VideoHelperSuite
注意:引用的模型、數據集和代碼的使用受其作者和維護者提供的相應許可和條款的約束。