
Wan 2.2 提示中繼:在 ComfyUI 中時間線控制的圖像到視頻#
此工作流程為 Wan 2.2 圖像到視頻帶來了片段級別的場景指導。它使用 Wan 2.2 進行生成,並使用提示中繼方法在單一時間線上路由不同的提示,這樣您可以在不切斷渲染的情況下從一個場景轉移控制到下一個場景。結果是一個平滑的多事件視頻,每個片段都遵循其自身的提示,同時保持物體的身份和風格一致。
Wan 2.2 提示中繼是一種推理時的路由技術,而不是獨立的模型或 LoRA。此圖設計用於 RunComfy 雲,包含一個雙階段採樣器鏈以及可選的 RIFE 幀插值。當您需要緊密的時間場景控制且設置最小時使用:提供一個開始圖像,定義一個全局提示和每段提示,設置視頻長度,然後渲染。
Comfyui Wan 2.2 提示中繼工作流程中的關鍵模型#
- Wan 2.2 圖像到視頻擴散模型 14B。高噪聲和低噪聲變體結合在一起,以在雙階段通過中平衡運動和細節。模型可在 Hugging Face 的 Comfy-Org 重新包裝集中獲得。Comfy-Org/Wan_2.2_ComfyUI_Repackaged
- UMT5-XXL 文本編碼器用於 Wan。此編碼器將您的全局和本地提示翻譯為 Wan 2.2 使用的條件。Comfy-Org/Wan_2.1_ComfyUI_repackaged
- Wan 2.1 VAE。用於在採樣後將潛變量解碼回幀。Comfy-Org/Wan_2.2_ComfyUI_Repackaged/vae
- RIFE 幀插值模型(可選)。增加生成後的時間平滑度或目標幀速率。hzwer/Practical-RIFE
如何使用 Comfyui Wan 2.2 提示中繼工作流程#
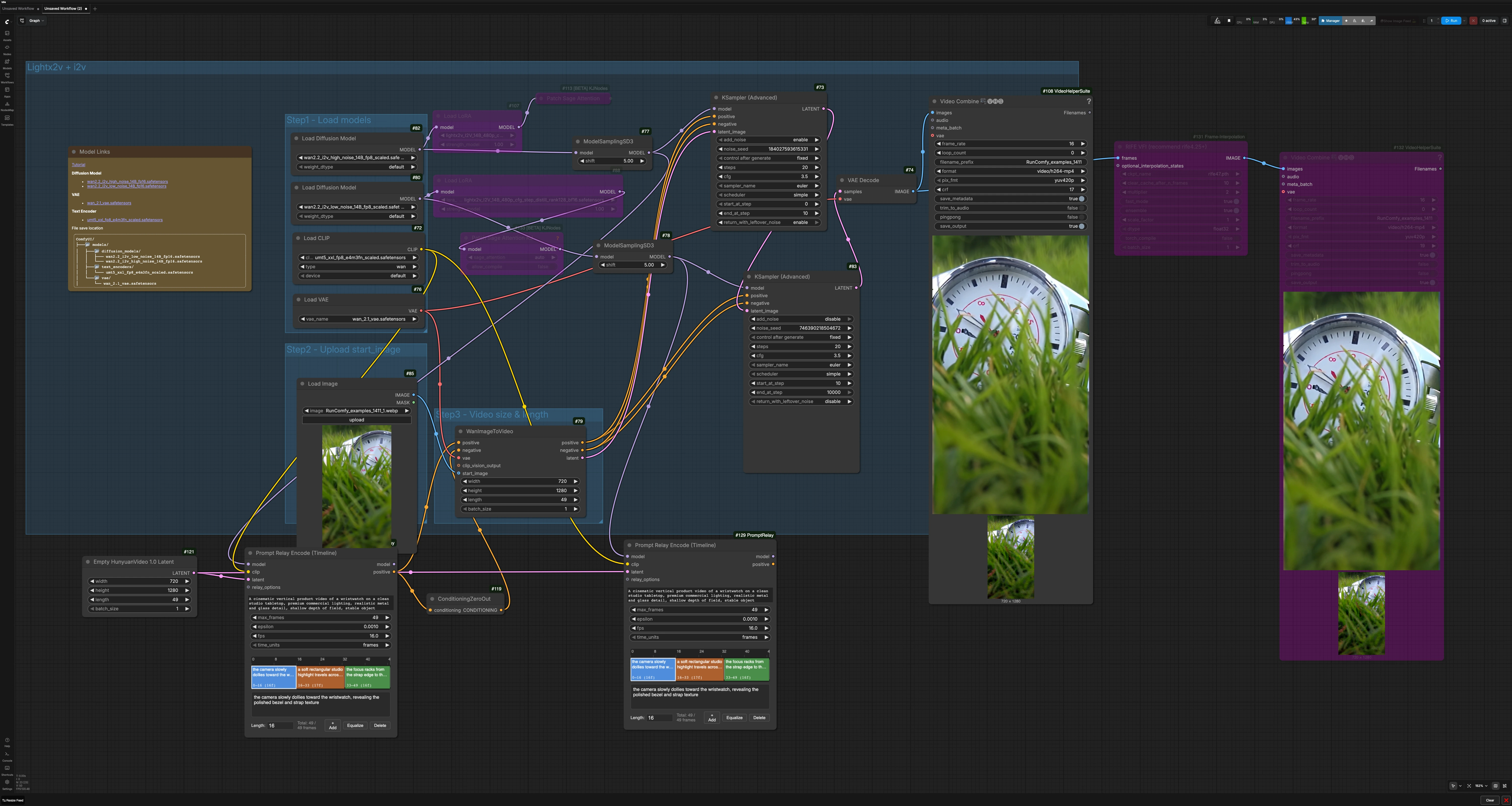
此工作流程隨時間路由文本提示,從開始圖像生成潛在視頻,然後在可選插值和編碼之前細化和解碼幀。它組織成幾個清晰的組,協作產生最終的 MP4。
- 步驟1 - 加載模型 此部分初始化 Wan 2.2、文本編碼器和 VAE。高噪聲和低噪聲 Wan 模型都已準備好,以便管道可以首先建立運動,然後增強細節。如果存在 LoRA,則在採樣前應用於基礎模型。除非您想交換檢查點,否則不需要更改此處的任何內容。
- 步驟2 - 上傳 start_image 導入單個參考圖像,使用
LoadImage(#85) 定義第一幀的構圖、主體身份和照明。開始圖像錨定視頻的外觀,幫助維持跨片段的連續性。使用乾淨的、符合模型的參考以獲得最佳效果。每當您想要不同的主題或佈局時,請更換它。 - 步驟3 - 視頻大小和長度 在潛在視頻初始化器 (
EmptyHunyuanLatentVideo(#121)) 中設置目標分辨率和總幀數,並保持與您的片段計劃一致。您的片段長度之和應等於總幀數。匹配您打算導出的幀速率與提示中繼設置以及圖中的視頻編寫器。 - Lightx2v + i2v 核心渲染路徑使用雙階段採樣器鏈。第一階段使用高噪聲模型建立運動和場景過渡。第二階段使用低噪聲模型細化細節和質地,同時保留第一階段的運動路徑。這種組合使 Wan 2.2 提示中繼在場景到場景移交時既可控又穩定。
- 提示路由 在
PromptRelayEncodeTimeline(#117) 中輸入應用於整個片段的強global_prompt。然後以 JSON 時間線數據或管道分隔列表的形式定義片段提示。提示中繼編碼每幀調節,僅在片段邊界處變化,可選地緩和過渡以實現自然的移交。此節點為 Wan 的調節提供飼料,確保每個片段遵循其預期方向。 - 採樣和解碼 管道通過
WanImageToVideo(#79),然後是粗略的KSamplerAdvanced(#73) 和精細的KSamplerAdvanced(#83)。幀使用VAEDecode(#74) 解碼並使用VHS_VideoCombine(#108) 寫入視頻。可選地,如果您想要更平滑的運動或更高的輸出幀速率,請在第二個VHS_VideoCombine(#132) 之前使用RIFE VFI(#131)。
Comfyui Wan 2.2 提示中繼工作流程中的關鍵節點#
PromptRelayEncodeTimeline(#117) Wan 2.2 提示中繼的核心,此節點將您的global_prompt和每段提示轉換為時間感知的正向調節流。您可以在timeline_dataJSON 中或使用管道語法在local_prompts中創建片段。使用max_frames以匹配視頻長度,選擇符合您計劃的time_units,並調整epsilon以軟化或加強片段之間的提示移交。保持fps與最終導出一致。WanImageToVideo(#79) 將開始圖像加上調節轉換為 Wan 2.2 的初始潛在時間線。將您的開始參考連接到start_image,並保持寬度、高度和長度與潛在初始化器一致。此圖中的負面調節故意置零,以減少過度限制並維持穩定的身份;只有當您看到您想要抑制的重複工藝品時,才引入明確的負面提示。KSamplerAdvanced(#73) 強調運動和佈局的第一遍採樣器。它與通過ModelSamplingSD3配置的高噪聲 Wan 模型一起工作,以探索軌跡,同時尊重提示中繼調節。調整steps和cfg以獲得指導的強度,並在您希望跨編輯迭代重現運動時保持固定的noise_seed。KSamplerAdvanced(#83) 使用低噪聲 Wan 模型增強細節和時間一致性的第二遍採樣器。它細化紋理、邊緣和微運動,而不與第一遍建立的粗略軌跡作鬥爭。如果您在此處增加保真度,請考慮平衡指導以避免過度銳化,這可能會破壞運動。EmptyHunyuanLatentVideo(#121) 創建定義空間分辨率、幀預算和批量大小的空白潛在視頻。設置總幀數為所有片段長度之和,以便提示中繼可以清晰地映射提示。更改分辨率會影響內存和運動節奏的外觀,因此請謹慎縮放。VHS_VideoCombine(#108, #132) 將幀編碼為 MP4。當不使用插值時,將frame_rate與提示中繼fps匹配。如果您使用RIFE VFI,請將寫入器的幀速率設置為新的有效 fps。調整crf以在大小和質量之間進行權衡。
可選附加功能#
- 寫入
global_prompt以鎖定音調、攝影機語言和質量標籤,然後保持片段提示簡短且以行動為中心。 - 確保您的片段長度總和等於視頻長度,以避免提示錯位。
- 在對提示進行迭代時保持種子固定,然後僅在您想要新想法時隨機化種子。
- 使用較高或較寬的開始圖像來建議長寬比偏好,但始終設置明確的寬度和高度以獲得可預測性。
- 如果您看到跨片段的身份漂移,請使用顯著的物體描述詞來加強
global_prompt並簡化本地提示。
探索此處使用的組件的資源:
- ComfyUI 的 Prompt Relay 節點由 kijai GitHub
- Wan 2.2 重新包裝模型 Hugging Face
- 為 Wan 2.x 重新包裝的 UMT5-XXL 文本編碼器 Hugging Face
鳴謝#
此工作流程實施並構建在以下作品和資源之上。我們對 ComfyUI-PromptRelay 節點的 kijai、Prompt-Relay 項目的 gordonchen19 和 Wan_2.2_ComfyUI_Repackaged 模型的 Comfy-Org 的貢獻和維護表示感謝。如需權威詳細信息,請參考下方鏈接的原始文檔和存儲庫。
資源#
- YouTube/Workflow @Ai Verse source tutorial
- Docs / Release Notes: @Ai Verse Workflow source tutorial
- AI Verse/AI Verse workflow page
- Docs / Release Notes: AI Verse workflow page
- kijai/ComfyUI-PromptRelay node repo
- GitHub: kijai/ComfyUI-PromptRelay
- gordonchen19/Prompt Relay project page
- GitHub: gordonchen19/Prompt-Relay
- Docs / Release Notes: Prompt Relay project page
- Comfy-Org/Wan 2.2 ComfyUI repackaged models
- Hugging Face: Comfy-Org/Wan_2.2_ComfyUI_Repackaged (split_files)
注意:引用的模型、數據集和代碼的使用受其作者和維護者提供的各自許可和條款的約束。