
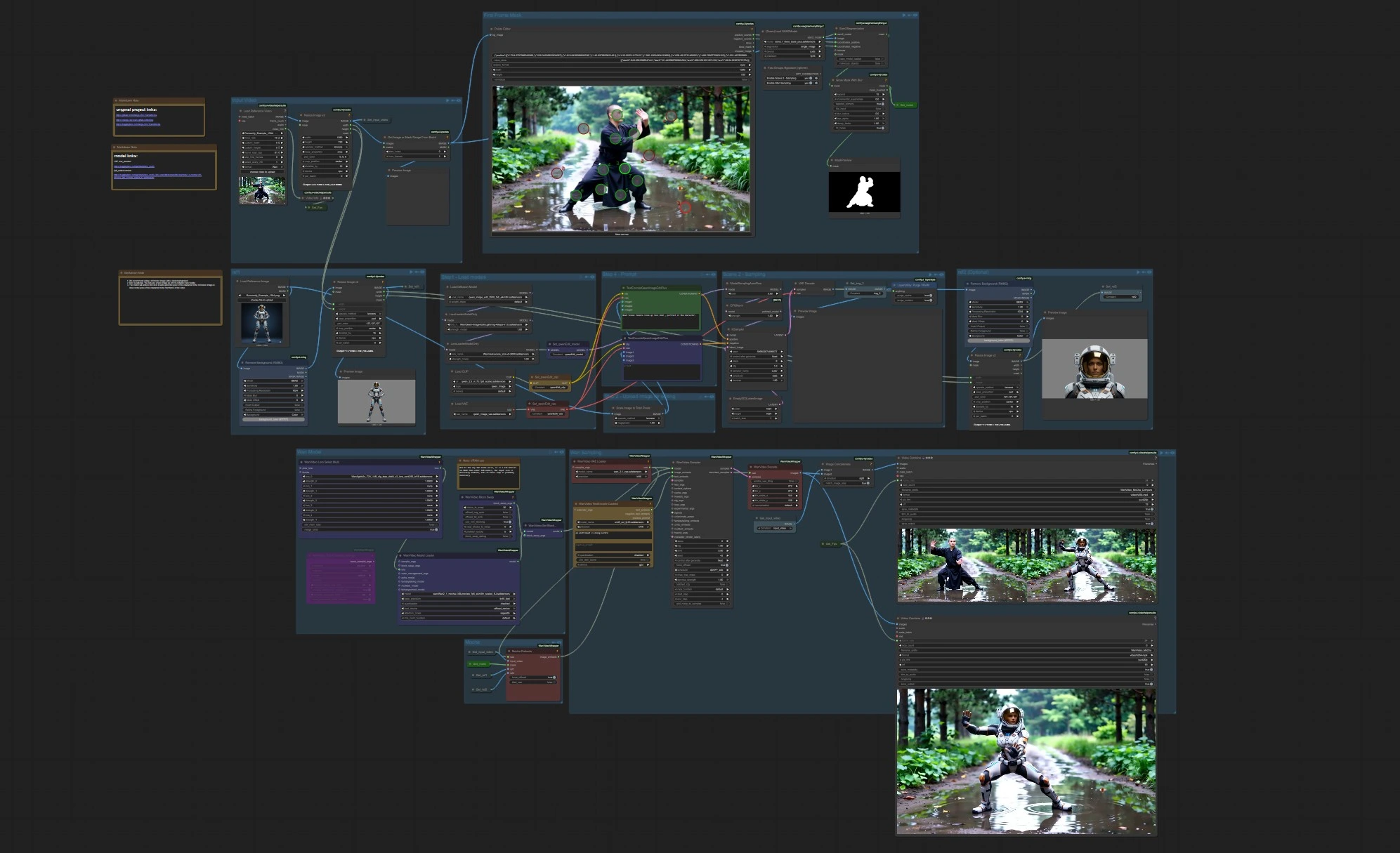
ComfyUI 的影片角色替換 (MoCha) 工作流程#
此工作流程提供端到端的影片角色替換 (MoCha):在實際影片中將表演者替換為新角色,同時保留動作、光影、攝影機視角和場景連續性。基於 Wan 2.1 MoCha 14B 預覽版設計,將參考身份與源表演對齊,然後合成連貫的編輯片段和可選的並排比較。專為需要精確、高質量角色交換且只需最少手動清理的電影製作人、視效藝術家和 AI 創作者設計。
該流程結合了強大的首幀遮罩、Segment Anything 2 (SAM 2)、MoCha 的動作感知圖像嵌入、WanVideo 採樣/解碼,以及可選的肖像輔助來提高面部保真度。您提供一個源視頻和一到兩張參考圖像;該工作流程生成一個完成的替換視頻以及 A/B 比較,使影片角色替換 (MoCha) 的迭代評估快速且實用。
ComfyUI 影片角色替換 (MoCha) 工作流程中的關鍵模型#
- Wan 2.1 MoCha 14B 預覽版。核心視頻生成器,用於角色替換;從 MoCha 圖像嵌入和文本提示中驅動時間一致的合成。模型權重由 Kijai 以 WanVideo Comfy 格式分發,包括效率提升的 fp8 縮放變體。Hugging Face: Kijai/WanVideo_comfy, Kijai/WanVideo_comfy_fp8_scaled
- MoCha (Orange‑3DV‑Team)。身份/動作調節方法和參考實現,啟發了此處使用的嵌入階段;有助於理解參考選擇和姿勢對齊的影片角色替換 (MoCha)。GitHub, Hugging Face
- Segment Anything 2 (SAM 2)。高質量、點引導分割,用於隔離首幀中的演員;乾淨的遮罩對於穩定、無瑕疵的交換至關重要。GitHub: facebookresearch/segment-anything-2
- Qwen‑Image‑Edit 2509 + Lightning LoRA。可選的單圖像輔助,生成乾淨的特寫肖像作為第二個參考,改善困難鏡頭中的面部身份保留。Hugging Face: Comfy‑Org/Qwen‑Image‑Edit_ComfyUI, lightx2v/Qwen‑Image‑Lightning
- Wan 2.1 VAE。由 Wan 採樣器/解碼器階段使用的視頻 VAE,用於高效的潛在處理。Hugging Face: Kijai/WanVideo_comfy
如何使用 ComfyUI 的影片角色替換 (MoCha) 工作流程#
整體邏輯
- 該工作流程接受一個源片段,準備首幀遮罩,並將您的角色參考編碼為 MoCha 圖像嵌入。然後,Wan 2.1 採樣編輯過的幀並解碼為視頻。同時,一個小的圖像編輯分支可以生成一個肖像作為面部細節的可選第二參考。該圖還渲染一個並排比較,以快速評估您的影片角色替換 (MoCha) 結果。
輸入視頻
- 在“輸入視頻”中加載一個視頻。工作流程會自動標準化幀(默認為 1280×720 裁剪)並保留片段的幀率以供最終導出。首幀被暴露以供檢查和下游遮罩。一個預覽節點顯示原始輸入幀,以便您在繼續之前確認裁剪和曝光。
首幀遮罩
- 使用互動點編輯器點擊演員上的正點和背景上的負點;SAM 2 將這些點擊轉換為精確的遮罩。一個小的增長和模糊步驟擴展了遮罩,以防止幀間的邊緣光暈和運動。預覽生成的遮罩,並將相同的遮罩發送到 MoCha 嵌入階段。此組中的良好遮罩在影片角色替換 (MoCha) 中顯著提高了穩定性。
ref1
- “ref1” 是您的主要角色身份圖像。工作流程移除背景,居中裁剪,並調整大小以匹配視頻的工作分辨率。為了獲得最佳效果,請使用乾淨背景的參考,其姿勢大致與首幀中的源演員匹配;MoCha 編碼器受益於類似的視點和光影。
ref2(可選)
- “ref2” 是可選的,但建議用於面部。您可以直接提供肖像,或者讓工作流程在下面的採樣分支中生成一個。圖像與 ref1 一樣移除背景並調整大小。當存在時,ref2 強化面部特徵,因此在運動、遮擋和視角變化期間身份保持不變。
步驟1 - 加載模型
- 該組加載 Wan 2.1 VAE 和 Wan 2.1 MoCha 14B 預覽模型,以及一個選擇性的 WanVideo LoRA 用於蒸餾。這些資產驅動主要視頻採樣階段。此處設置的模型對 VRAM 要求較高;稍後包括一個塊交換助手,以便在小型 GPU 上適應大型序列。
步驟2 - 上傳要編輯的圖像
- 如果您希望從自己的靜態圖像構建 ref2,請將其放在這裡。分支縮放圖像並將其路由到 Qwen 編碼器進行調節。如果您已經有一個好的面部肖像,可以跳過整個分支。
步驟4 - 提示
- 提供描述預期特寫肖像的簡短文本提示(例如,“下一場景:相機特寫面部鏡頭,角色肖像”)。Qwen‑Image‑Edit 使用此提示來完善或合成一個乾淨的面部圖像,成為 ref2。保持描述簡單;這是一個輔助,而不是完整的重塑。
場景2 - 採樣
- Qwen 分支運行快速採樣器,生成一個在 Lightning LoRA 下的單一肖像圖像。該圖像被解碼、預覽,並在輕微去除背景後作為 ref2 轉發。此步驟通常在不改變核心影片角色替換 (MoCha) 外觀的情況下提高面部保真度。
Mocha
MochaEmbeds階段將源視頻、首幀遮罩和您的參考圖像編碼為 MoCha 圖像嵌入。嵌入捕捉身份、紋理和局部外觀提示,同時尊重原始運動路徑。如果存在 ref2,則用於加強面部細節;否則,僅 ref1 攜帶身份。
Wan 模型
- Wan 模型加載器將 Wan 2.1 MoCha 14B 預覽加載到內存中,並(可選)應用 LoRA。塊交換工具已連接,以便在需要時您可以用速度換取內存。此模型選擇設置影片角色替換 (MoCha) 的整體容量和連貫性。
Wan 採樣
- 採樣器消耗 Wan 模型、MoCha 圖像嵌入和任何文本嵌入,生成編輯的潛在幀,然後解碼回圖像。產生兩個輸出:最終交換視頻和與原始幀的並排比較。幀率從加載器傳遞,因此運動速度自動匹配源。
ComfyUI 影片角色替換 (MoCha) 工作流程中的關鍵節點#
MochaEmbeds(#302)。將源片段、首幀遮罩和參考圖像編碼為 MoCha 圖像嵌入,以引導身份和外觀。選擇一個與首幀匹配的 ref1 姿勢,並包括 ref2 以獲得乾淨的面部;如果邊緣閃爍,在嵌入前稍微擴大遮罩以避免背景洩漏。Sam2Segmentation(#326)。將您的正/負點擊轉換為首幀遮罩。優先考慮頭髮和肩膀周圍的乾淨邊緣;添加一些負點以排除附近的道具。分割後略微擴大遮罩有助於演員移動時的穩定性。WanVideoSampler(#314)。通過去噪潛在圖像生成幀,推動影片角色替換 (MoCha) 的繁重工作。更多步驟改善細節和時間穩定性;更少的步驟加快迭代速度。在比較參考或遮罩的變化時,保持調度一致。WanVideoSetBlockSwap(#344)。當 VRAM 緊張時,啟用更深的塊交換以適應小型 GPU 上的 Wan 2.1 MoCha 14B 路徑。預期會有一些速度損失;作為回報,您可以保持分辨率和序列長度。VHS_VideoCombine(#355)。寫入最終的 MP4 並嵌入工作流程元數據。使用與源相同的幀率(已經連接)和 yuv420p 輸出,以便廣泛的播放器兼容性。
可選附加功能#
- 乾淨交換的提示
- 使用背景簡單且姿勢接近首幀的 ref1。
- 保持 ref2 為清晰的正面面部肖像,以穩定身份。
- 如果看到邊緣光暈,擴大並輕微模糊首幀遮罩,然後重新嵌入。
- 繁重場景受益於塊交換助手;否則,為了速度,保持關閉。
- 工作流程渲染一個 A/B 比較視頻;用它來快速判斷變更。
- 有用的參考資料
- MoCha by Orange‑3DV‑Team: GitHub, Hugging Face
- Wan 2.1 MoCha 14B (Comfy format): Kijai/WanVideo_comfy, Kijai/WanVideo_comfy_fp8_scaled
- Segment Anything 2: facebookresearch/segment-anything-2
- Qwen Image Edit + Lightning LoRA: Comfy‑Org/Qwen‑Image‑Edit_ComfyUI, lightx2v/Qwen‑Image‑Lightning
致謝#
此工作流程實施並基於以下作品和資源。我們感謝“Video Character Replacement (MoCha)”的 Benji’s AI Playground 為影片角色替換 (MoCha) 的貢獻和維護。欲了解權威的詳細信息,請參閱下面鏈接的原始文檔和儲存庫。
資源#
- “Video Character Replacement (MoCha)”/影片角色替換 (MoCha) 的作者
- 文檔 / 發布說明 @Benji’s AI Playground: YouTube video
注意:所引用的模型、數據集和代碼的使用受其作者和維護者提供的相應許可和條款的約束。