




Stability AI 推出了 Stable Diffusion 3.5 (SD3.5),這是一個開源的多模態生成 AI 模型,包括多個變體,如 Stable Diffusion 3.5 (SD3.5) Large、Stable Diffusion 3.5 (SD3.5) Large Turbo 和 Stable Diffusion 3.5 (SD3.5) Medium。這些模型高度可定制,能夠在消費級硬體上運行。SD3.5 Large 和 Large Turbo 模型立即可用,而 Medium 版本將於 2024 年 10 月 29 日發布。
1. Stable Diffusion 3.5 (SD3.5) 的工作原理#
在技術層面,Stable Diffusion 3.5 (SD3.5) 將文本提示作為輸入,使用基於 transformer 的文本編碼器將其編碼為潛在空間,然後使用基於 diffusion 的解碼器將該潛在表示解碼為輸出圖像。transformer 文本編碼器,如 CLIP (Contrastive Language-Image Pre-training) 模型,將輸入提示映射到潛在空間中的語義上有意義的壓縮表示。然後,diffusion 解碼器在多個時間步驟中迭代去噪該潛在代碼,以生成最終的圖像輸出。diffusion 過程涉及逐漸從最初噪聲的潛在表示中移除噪聲,條件化於文本嵌入,直到出現清晰的圖像。
Stable Diffusion 3.5 (SD3.5) 的不同模型尺寸(Large、Medium)指的是可訓練參數的數量 - Large 模型為 80 億,Medium 為 25 億。更多的參數通常允許模型從其訓練數據中捕捉更多的知識和細微差別。Turbo 模型是蒸餾版本,犧牲一些質量以換取更快的推理速度。蒸餾涉及訓練一個較小的「學生」模型來模仿較大「教師」模型的輸出,旨在以更高效的架構保留大部分功能。
2. Stable Diffusion 3.5 (SD3.5) 模型的優勢#
2.1. 可定制性#
Stable Diffusion 3.5 (SD3.5) 模型旨在易於微調和構建特定應用。Query-Key 正規化集成到 transformer 塊中,以穩定訓練並簡化進一步的開發。這種技術正規化了 transformer 層中的注意力分數,這可以使模型更穩健,更容易適應新數據集通過遷移學習。
2.2. 輸出的多樣性#
Stable Diffusion 3.5 (SD3.5) 旨在生成代表世界多樣性的圖像,而不需要大量提示。它可以描繪具有不同膚色、特徵和美學的人。這可能是因為該模型在網際網路上的大型和多樣化數據集的圖像上進行訓練。
2.3. 廣泛的風格範圍#
Stable Diffusion 3.5 (SD3.5) 模型能夠生成多種風格的圖像,包括 3D 渲染、寫實主義、油畫、線條藝術、動漫等。這種多樣性使其適合許多用例。風格多樣性源於 diffusion 模型在其潛在空間中捕捉許多不同視覺模式和美學的能力。
2.4. 強大的提示遵從性#
尤其是對於 Stable Diffusion 3.5 (SD3.5) Large 模型,SD3.5 擅長生成與輸入文本提示的語義意義一致的圖像。與其他模型相比,它在提示匹配指標上排名較高。這種準確將文本轉換為圖像的能力由 transformer 文本編碼器的語言理解能力驅動。
3. Stable Diffusion 3.5 (SD3.5) 模型的限制和缺點#
3.1. 解剖學和物體交互的困難#
與大多數文本到圖像模型一樣,Stable Diffusion 3.5 (SD3.5) 在呈現逼真的人體解剖學方面仍然存在困難,尤其是手部、足部和面部的複雜姿勢。物體與手部之間的交互通常會變形。這可能是由於從 2D 圖像中學習所有 3D 空間關係和物理細微差別的挑戰。
3.2. 限制的解析度#
Stable Diffusion 3.5 (SD3.5) Large 模型適用於 1 百萬像素圖像(1024x1024),而 Medium 顶多達到 2 百萬像素。生成更高解析度的連貫圖像對 SD3.5 來說是具有挑戰性的。這個限制源於 diffusion 架構的計算和內存限制。
3.3. 偶爾的故障和幻覺#
由於 Stable Diffusion 3.5 (SD3.5) 模型允許從同一提示中產生廣泛多樣的輸出,並使用不同的隨機種子,可能會出現一些不可預測性。缺乏特定性的提示可能會導致出現故障或意外元素。這是 diffusion 取樣過程的固有特性,涉及隨機性。
3.4. 未達到絕對尖端水平#
根據一些早期測試,在圖像質量和連貫性方面,Stable Diffusion 3.5 (SD3.5) 目前尚未達到尖端文本到圖像模型,如 Midjourney 的性能。Stable Diffusion 3.5 (SD3.5) 與 FLUX.1 的早期比較顯示每個模型在不同領域表現卓越。雖然 FLUX.1 在生成寫實主義圖像方面似乎具有優勢,但 SD3.5 Large 在生成動漫風格藝術作品方面更具優勢,無需額外微調或修改。
4. ComfyUI 中的 Stable Diffusion 3.5#
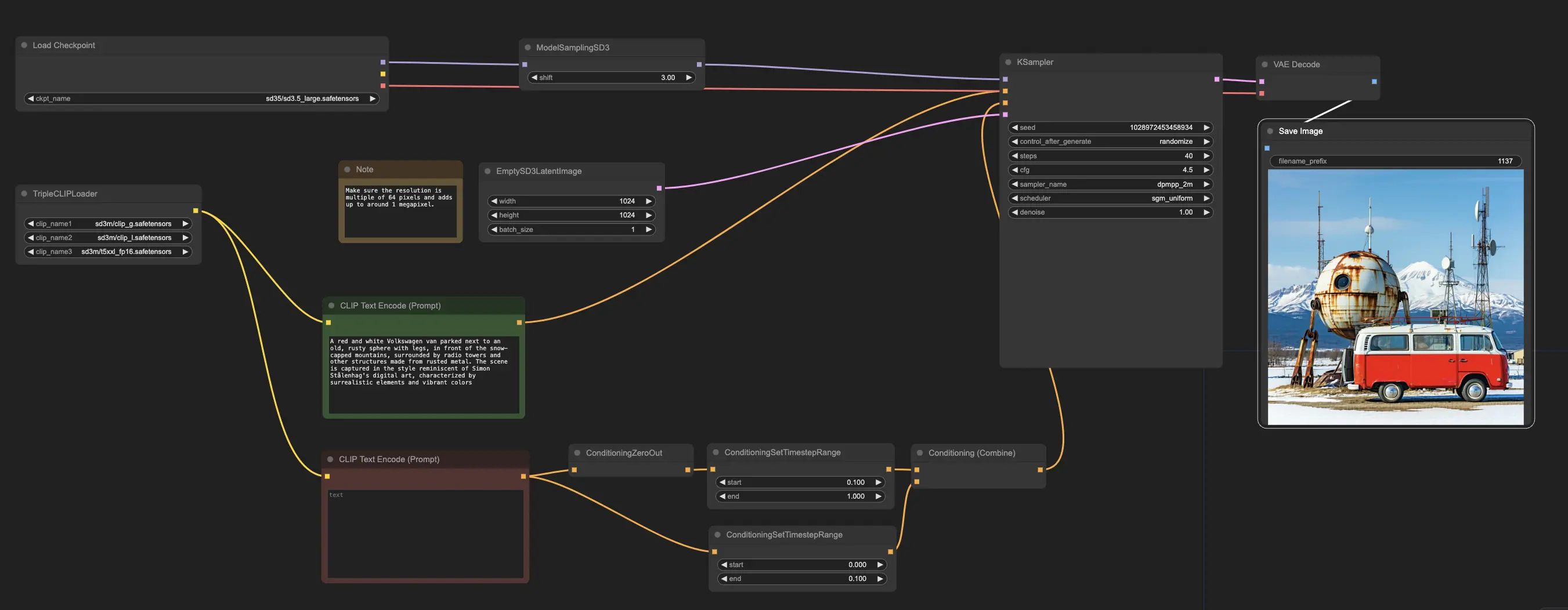
在 RunComfy,我們已經為您預加載了 Stable Diffusion 3.5 (SD3.5) 模型,以便您輕鬆開始使用。您可以直接進入並使用示例工作流程運行推理
示例工作流程從 CheckpointLoaderSimple 節點開始,該節點加載預訓練的 Stable Diffusion 3.5 Large 模型。並且為了幫助將您的文本提示轉換為模型可以理解的格式,使用 TripleCLIPLoader 節點加載相應的編碼器。這些編碼器在根據您提供的文本指導圖像生成過程中至關重要。
然後,EmptySD3LatentImage 節點創建一個具有指定尺寸的空白畫布,通常為 1024x1024 像素,這是模型生成圖像的起點。CLIPTextEncode 節點處理您提供的文本提示,使用加載的編碼器創建一組模型應遵循的指令。
在這些指令被發送到模型之前,它們通過 ConditioningCombine、ConditioningZeroOut 和 ConditioningSetTimestepRange 節點進一步精煉。這些節點移除任何負面提示的影響,指定提示應在生成過程中何時應用,並將指令合併為一個單一的、連貫的集合。
最後,您可以使用 ModelSamplingSD3 節點微調圖像生成過程,允許您調整各種設置,如取樣模式、步數和模型輸出比例。最後,KSampler 節點讓您控制步數、指令影響的強度(CFG 比例)和用於生成的特定算法,使您能夠實現所需的結果。
