
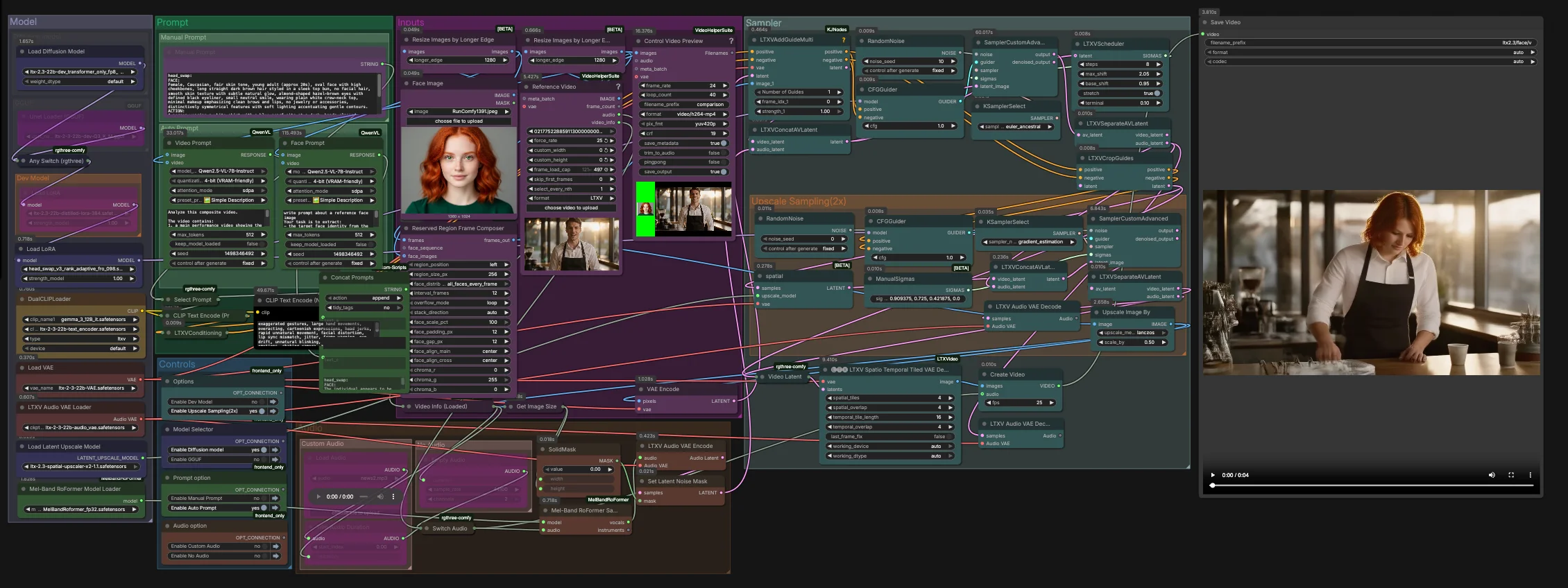
LTX-2.3-Video-Face-Swap for ComfyUI#
此工作流程使用 LTX 2.3 系列提供高保真、時間穩定的影片面部替換。專為 RunComfy 和 ComfyUI 構建,它將身份引導圖像與目標影片和可選音頻指導融合在一起,以在幀間保留表情、光照和動作。結果是逼真的、抗閃爍的替換,在特寫和中景鏡頭中都能保持。
創作者、VFX 藝術家和 AI 電影製作者可以使用 LTX-2.3-Video-Face-Swap 保持完整的創作控制:手動提示或從輸入生成結構化提示,選擇 dev、distilled、FP8 或 GGUF 變體,並以空間-時間解碼和可選的 2x 潛在升級來完成,以獲得清晰的細節。
Comfyui LTX-2.3-Video-Face-Swap 工作流程中的關鍵模型#
- LTX 2.3 22B Video Diffusion Transformer。核心影片生成和編輯模型,驅動身份保護和時間連貫性。請參閱官方模型系列 Lightricks/LTX-2.3。
- LTX 2.3 Text Encoders。圖形將 LTX 2.3 文本編碼器與 Gemma 3 12B 指令編碼器配對,以改善影片編輯的提示對齊。示例工件:ltx-2-3-22b-text_encoder.safetensors 和 gemma_3_12B_it.safetensors。
- LTX 2.3 VAE 和 Audio VAE。編碼器/解碼器用於壓縮和重建視覺幀和音頻軌道,同時保留細節和同步。請參閱 Lightricks/LTX-2.3 VAE files 和分割存儲庫中的音頻 VAE 變體 vantagewithai/LTX-2.3-Split。
- LTX 2.3 Spatial Upscaler x2。在最終解碼之前提升空間保真度的潛在空間 2x 升級器,適合面部細節。ltx-2.3-spatial-upscaler-x2-1.1.safetensors。
- Head‑swap LoRA。專為身份轉移而設計的秩自適應 LoRA,改善在編輯時的相似性和穩定性。示例:head_swap_v3_rank_adaptive_fro_098.safetensors。
- MelBandRoFormer。這裡使用的可選音樂來源分離模型,用於隔離人聲以提供更強的嘴部動作指導。Kijai/MelBandRoFormer_comfy。
- 可選部署變體。FP8 僅限變壓器的權重,用於在支持的 GPU 上提升速度 Kijai/LTX2.3_comfy 和輕量級 UNet GGUF 構建,用於 CPU 或低 VRAM 場景 vantagewithai/LTX-2.3-GGUF。
如何使用 Comfyui LTX-2.3-Video-Face-Swap 工作流程#
此圖形分兩個階段運行。第一階段在原生潛在分辨率下執行核心替換,並具有音頻感知指導。第二階段在潛在空間中進行升級並在空間-時間解碼和最終多路復用到影片之前精細化面部區域。
輸入#
- 在
Face Image(LoadImage(#255)) 中加載您的身份圖像。使用光線充足的正面或四分之三拍攝,以獲得最可靠的身份提取。 - 在
Reference Video(VHS_LoadVideo(#393)) 中加載目標影像。幀通過ResizeImagesByLongerEdge和Control Video Preview(VHS_VideoCombine(#396)) 進行標準化和預覽,以便在取樣前快速檢查。 ReservedRegionFrameComposer(#395) 準備引導幀,將面部圖像對齊到場景佈局,幫助模型在調節期間專注於替換區域。
提示#
- 您可以在
Manual Prompt中手動描述所需的外觀和動作,或讓圖形自動構成結構化提示。Video Prompt(AILab_QwenVL(#400)) 從影片中提取身體運動和場景,而Face Prompt(AILab_QwenVL(#401)) 從面部圖像中提取身份細節。 Concat Prompts將身份和動作合併為一個簡潔的指令,然後Select Prompt將您的手動文本或自動提示路由到CLIP Text Encode。負面提示文本單獨編碼,以抑制常見的影片工件。
模型#
Model組加載 LTX 2.3 UNet 或其 GGUF 變體,應用 distilled LoRA 和 head‑swap LoRA,並調用 LTX VAE 和雙文本編碼器。雙編碼器設置改善了口語內容和相機阻擋的對齊,而不會過度限制身份。- 如果您正在優化速度或內存,請在提供的模型選擇器中切換 dev、distilled、FP8 transformer‑only 或 GGUF。RunComfy 中不需要額外設置。
取樣器#
- 第一階段在
LTXVConcatAVLatent(#321) 中結合影片和音頻潛在變量,然後使用CFGGuider(#326)、LTXVScheduler(#324) 和SamplerCustomAdvanced(#257) 去噪。LTXVAddGuideMulti(#392) 注入您的身份引導,使面部在早期建立並隨時間保持穩定。 - 初次通過後,
LTXVSeparateAVLatent(#323) 分離流,以便LTXVCropGuides(#282) 可以專注於面部周圍的編輯。這集中計算在重要的地方,提高時間一致性。
升級取樣 (2x)#
LTXVLatentUpsampler(#279) 在潛在空間中應用 LTX 2.3 x2 空間升級器。升級後的影片潛在變量然後與音頻潛在變量在LTXVConcatAVLatent(#287) 中重新連接,並由第二次SamplerCustomAdvanced(#288) 通過CFGGuider(#284) 指導進行精細化。- 這種兩階段策略產生更清晰的皮膚、眼睛和頭髮,同時保持替換鎖定在預期身份上。
音頻#
Audio組讓您通過Switch Audio路由原始音頻、靜音或修剪段。為了更強的嘴部動作提示,選擇的軌道通過MelBandRoFormerSampler(#355) 隔離人聲,然後使用LTXVAudioVAEEncode(#364) 編碼。- 堅固的噪音掩模 (
SetLatentNoiseMask(#365)) 防止嘴部區域外的意外音頻驅動變化,同時仍然利用語音時間來指導表情。
解碼和導出#
- 最終幀使用
LTXVSpatioTemporalTiledVAEDecode(#377) 重建,該解碼器使用時間感知的平鋪避免接縫並保持運動連續性。CreateVideo(#292) 將圖像與您選擇的音頻多路復用,並使用SaveVideo寫入完成的影片。
Comfyui LTX-2.3-Video-Face-Swap 工作流程中的關鍵節點#
LTXVAddGuideMulti(#392)。將對齊的面部引導輸入到調節流中,使模型從第一步開始就鎖定目標身份。如果相似性在快速運動中漂移,增加引導幀的數量或頻率,而不是全局提高指導。LTXVCropGuides(#282)。自動將第二次通過集中在第一階段潛在變量和提示衍生的面部區域上。當背景或手競爭注意力時,使用它來緊縮編輯區域。SamplerCustomAdvanced(#257)。主要去噪通過,確立身份、光照和粗略運動。與LTXVScheduler配對進行步驟整形,並在實驗中保持取樣器選擇穩定,以便比較有意義。LTXVLatentUpsampler(#279)。在精細化之前使用 LTX 空間升級器進行 2x 潛在升級。當您需要更清晰的毛孔、睫毛和帽縫而不引入後解碼像素升級器的閃爍時使用此功能。SamplerCustomAdvanced(#288)。升級後的精細化通過。這裡適度調整指導以銳化特徵,同時保留第一階段設置的身份。LTXVSpatioTemporalTiledVAEDecode(#377)。時間感知解碼器,減少幀間的平鋪接縫。如果您在長片段上遇到 VRAM 限制,請優先調整其平鋪佈局,而不是降低分辨率。MelBandRoFormerSampler(#355)。僅用於指導的人聲分離。如果源音頻嘈雜,切換到原始或靜音音頻,以避免將工件傳播到嘴部運動中。
可選額外功能#
- 面部圖像質量很重要。使用中性、光線充足的正面或輕微的三分之一照片,表情與表演相似。
- 保持參考影片穩定。靜態或三腳架拍攝產生最穩定的 LTX-2.3-Video-Face-Swap 結果,尤其是在中景和特寫鏡頭中。
- 提示應簡潔。以單段描述場景和動作,將身份形容詞保留給面部提示,而不是動作提示。
- 音頻指導是可選的。清晰的語音改善嘴部形狀;僅音樂曲目提供的好處有限,因此選擇靜音以將計算集中在視覺上。
- 對於低 VRAM 或僅 CPU 運行,優先選擇 GGUF UNet 構建;對於現代 GPU 上的高吞吐量,FP8 僅限變壓器的權重是一個不錯的默認選擇。
- 負責任地使用。獲得您替換的任何相似性的同意,並遵守適用的法律和平台政策。
鳴謝#
此工作流程實現並構建於以下作品和資源之上。我們衷心感謝 LTX-2.3 提供 LTX-2.3 模型,以及 EyeForAILabs 提供的 YouTube 教程,感謝他們的貢獻和維護。欲了解權威詳細信息,請參閱以下鏈接的原始文檔和存儲庫。
資源#
- LTX-2.3/LTX-2.3 Model
- Hugging Face: Hugging Face Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
注意:使用所引用的模型、數據集和代碼需遵循其作者和維護者提供的各自許可和條款。