











由梁華、魏望、吳志凡及其在同一實驗室的合作者開發的 In-Context LoRA (IC-LoRA) 項目,代表了一種突破性的使用擴散變壓器(DiTs)進行任務無關圖像生成的方法。他們的創新框架通過引入最小調整和簡化的流程,利用 DiTs 的上下文生成能力,允許使用小數據集進行高效的任務特定調整。要了解更多關於他們的工作並訪問他們的資源,請訪問官方 GitHub 存儲庫:GitHub。
1. 關於 In-Context LoRA (IC-LoRA)#
In-Context LoRA (IC-LoRA) 是一個強大且靈活的框架,可以讓現有的文本到圖像擴散變壓器模型以最小的額外訓練執行各種圖像生成任務。In-Context LoRA 背後的關鍵理念是通過提供精心策劃的訓練數據並使用簡單而有效的微調方法,利用這些模型的固有上下文學習能力。
以下是 In-Context LoRA 的工作原理概述:
- 圖像拼接:IC-LoRA 不單獨生成圖像,而是將一組相關項目拼接成一個大的合成圖像。這使模型能夠學習跨組的一致性和關係。
- 提示工程:該組的文本提示也被拼接成一個提示。這個提示首先描述整個組,然後提供每個單獨項目的具體細節。通過這種方式設計提示,模型能夠理解高層次任務以及低層次需求。
- 低秩適應 (LoRA):IC-LoRA 不對整個擴散模型進行微調,這樣做會非常昂貴,而是使用 LoRA 來調整模型以適應每個特定任務。LoRA 只訓練一小組輔助參數,保持原始模型權重不變。這使微調過程更加高效。
- 小訓練數據集:IC-LoRA 的另一個關鍵見解是您不需要大數據集來觸發上下文學習能力。每個任務只需 20-100 組高質量圖像集即可達到令人印象深刻的效果。這大大減少了數據收集和計算負擔。
In-Context LoRA 的美妙之處在於它是一個任務無關的框架。相同的方法可以應用於廣泛的任務,例如故事板生成、字體設計、產品設計、視覺效果等。通過提供任務特定的訓練數據,IC-LoRA 可以適應每個任務,而無需對模型架構進行任何更改。
2. 10 個 In-Context LoRA 模型及其推薦設置#
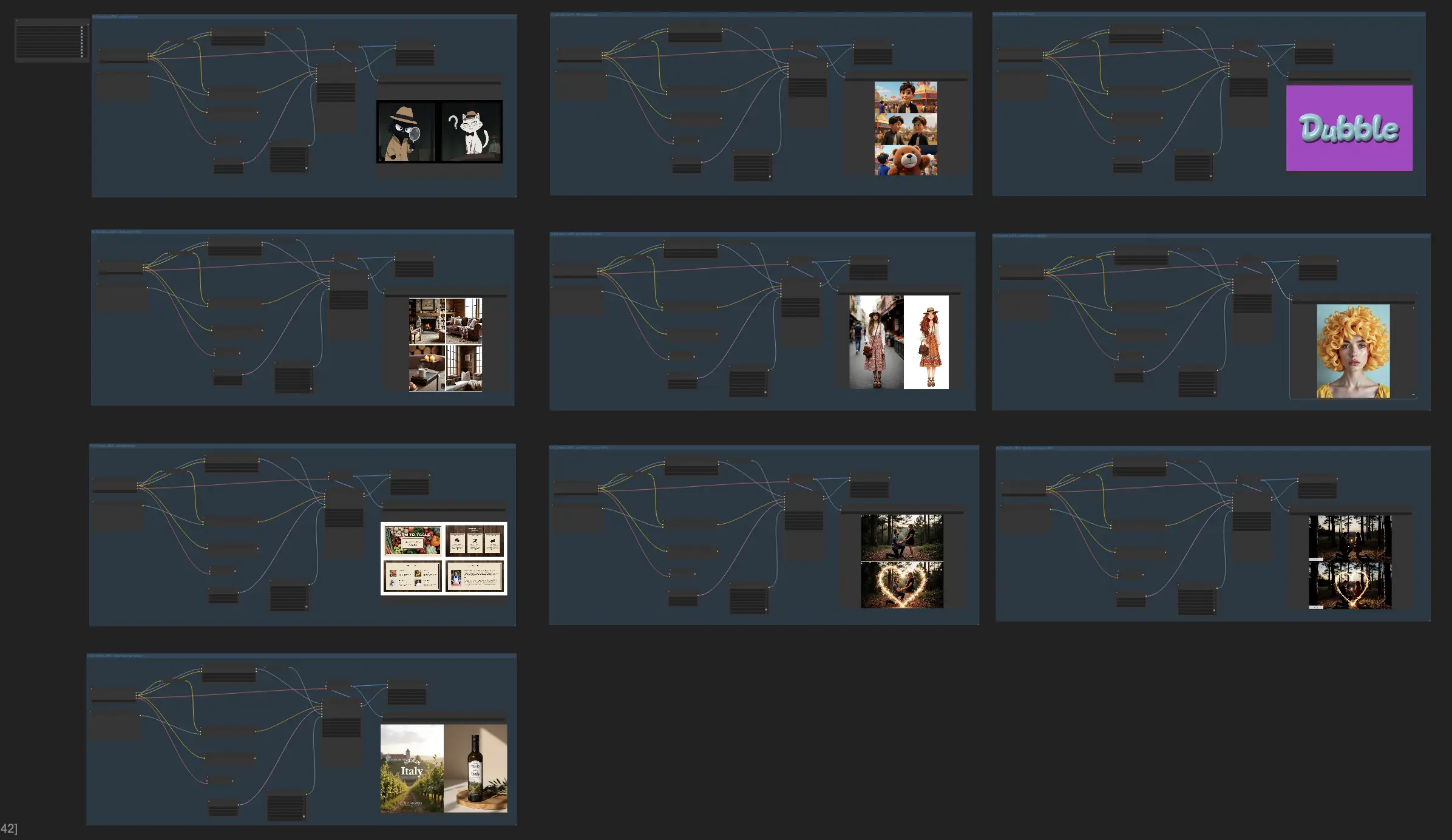
<table style={{ width: '100%', border: '1px solid grey', borderCollapse: 'collapse' }}> <thead> <tr> <th style={{ border: '1px solid grey', textAlign: 'center' }}><strong>任務</strong></th> <th style={{ border: '1px solid grey', textAlign: 'center' }}><strong>模型</strong></th> <th style={{ border: '1px solid grey', textAlign: 'center' }}><strong>推薦設置</strong></th> <th style={{ border: '1px solid grey', textAlign: 'center' }}><strong>示例提示</strong></th> </tr> </thead> <tbody> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>1. 情侶形象設計</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/couple-profile.safetensors" target="_blank" rel="noopener noreferrer">couple-profile.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:2048,高度:1024</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>這幅兩部分的圖像描繪了一對穿著偵探服裝的卡通貓;[左] 一隻穿著風衣和軟呢帽的黑貓手持放大鏡向右凝視,而 [右] 一隻戴著蝴蝶結和相配帽子的白貓則揚起一眉,形成一幅充滿樂趣的黑色場景,背景昏暗。</td> </tr> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>2. 電影分鏡</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/film-storyboard.safetensors" target="_blank" rel="noopener noreferrer">film-storyboard.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:1024,高度:1536</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>[電影鏡頭] 在一個充滿活力的節日中,[場景-1] 我們看到 <Leo>,一個害羞的男孩,站在熱鬧的嘉年華邊緣,對色彩繽紛的遊樂設施和歡笑充滿驚訝,[場景-2] 轉向他勉強嘗試一個大膽的遊戲,朋友們為他加油,[場景-3] 最後,他贏得了一個巨大的毛絨熊,他的臉上充滿自豪地將其舉起讓所有人看到。</td> </tr> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>3. 字體設計</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/font-design.safetensors" target="_blank" rel="noopener noreferrer">font-design.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:1792,高度:1216</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>這幅四格圖像展示了一種玩具泡泡字體,以生動的流行藝術風格呈現。[左上] 顯示 "Pop Candy",用亮粉色搭配波點背景;[右上] 顯示 "Sweet Treat",周圍環繞著糖果插圖;[左下] 顯示 "Yum!",混合了亮麗的顏色;[右下] 顯示 "Delicious",背景為條紋,非常適合有趣的兒童友好產品。</td> </tr> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>4. 家居裝飾</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/home-decoration.safetensors" target="_blank" rel="noopener noreferrer">home-decoration.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:1344,高度:1728</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>這幅四格圖像展示了一個鄉村風格的客廳,具有溫暖的木材色調和舒適的裝飾元素;[左上] 展示了一個大石壁爐,木架上放滿了書籍和蠟燭;[右上] 展示了一個復古皮沙發,上面鋪著格子毯,配上各種紋理的靠墊;[左下] 展示了一個角落,有一個木製扶手椅,旁邊的邊桌上放著一杯熱氣騰騰的飲料和一本經典書籍;[右下] 捕捉了一個舒適的閱讀角,有一個窗台座位、柔軟的毛皮毯和整齊堆疊的裝飾原木。</td> </tr> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>5. 肖像插畫</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/portrait-illustration.safetensors" target="_blank" rel="noopener noreferrer">portrait-illustration.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:1152,高度:1088</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>這幅兩格圖像展示了一個從現實主義肖像到玩樂插畫的轉變,捕捉了細節和藝術風格;[左] 照片中顯示了一位女士站在繁忙的市場中,戴著寬邊帽,穿著流暢的波希米亞風格連衣裙,背著皮革斜挎包;[右] 插畫面板誇大了她的配飾和特徵,波希米亞風格連衣裙以鮮豔的圖案和大膽的顏色描繪,而背景簡化為抽象的市場攤位,賦予場景動畫和活力感。</td> </tr> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>6. 肖像攝影</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/portrait-photography.safetensors" target="_blank" rel="noopener noreferrer">portrait-photography.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:1344,高度:1728</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>這幅 [四格] 圖像展示了一位年輕藝術家的創作過程,位於一個明亮而鼓舞人心的工作室中;[左上] 她站在一幅大畫布前,手握畫筆,為未完成的畫作添加鮮豔的顏色,[右上] 她坐在一張雜亂的木桌旁,在筆記本中勾畫構思,周圍散落著各種藝術用品,[左下] 她後退一步觀察她的作品,若有所思地調整眼鏡,[右下] 她通過直接在調色板上混合顏料來嘗試不同的紋理,她專注的表情顯示出她對藝術的熱愛。</td> </tr> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>7. PPT 模板</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/ppt-templates.safetensors" target="_blank" rel="noopener noreferrer">ppt-templates.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:1984,高度:1152</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>這幅四格圖像展示了一個鄉村主題的 PowerPoint 模板,用於烹飪工作坊;[左上] 以溫暖的土色調介紹 "從農場到餐桌的烹飪";[右上] 組織工作坊部分,如 "食材"、"準備" 和 "服務";[左下] 顯示季節性農產品的食材清單;[右下] 包括廚師簡介和簡短的個人資料。</td> </tr> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>8. 沙塵暴視覺效果</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/sandstorm-visual-effect.safetensors" target="_blank" rel="noopener noreferrer">sandstorm-visual-effect.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:1408,高度:1600</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>[沙塵暴-公告] 這幅兩部分的圖像展示了騎行者通過沙塵暴視覺效果的轉變;[上] 上面板展示了一名騎行者穿著鮮豔的裝備,在晴朗的開闊道路上穩定地騎行,背景是寧靜的天空,突出了專注和決心,[下] 下面板將場景轉變為騎行者被猛烈的沙塵暴包圍,沙粒猛烈地在自行車和騎行者周圍旋轉,背景變得暴風雨般黑暗,強調了混亂和力量。</td> </tr> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>9. 煙火視覺效果</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/sparklers-visual-effect.safetensors" target="_blank" rel="noopener noreferrer">sparklers-visual-effect.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:960,高度:1088</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>[真實煙火疊加] 這幅兩部分的圖像json vividly illustrates a woodland proposal transformed by sparkler overlays; [TOP] the first panel depicts a man kneeling on one knee with an engagement ring before his partner in a forest clearing at dusk, with warm, natural lighting, [BOTTOM] while the second panel introduces glowing sparklers that form a heart shape around the couple, amplifying the romance and joy of the moment.</td> </tr> <tr> <td style={{ border: '1px solid grey', textAlign: 'center' }}><strong>10. 視覺識別設計</strong></td> <td style={{ border: '1px solid grey', textAlign: 'center' }}> <a href="https://huggingface.co/ali-vilab/In-Context-LoRA/blob/main/visual-identity-design.safetensors" target="_blank" rel="noopener noreferrer">visual-identity-design.safetensors</a> </td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>寬度:1472,高度:1024</td> <td style={{ border: '1px solid grey', textAlign: 'center' }}>這幅兩格圖像展示了一個生產品牌的愉悅形象,左側面板展示了一個微笑的鳳梨圖案和品牌名 "Fresh Tropic",字體輕鬆隨意,背景為淺藍色;[左] 而右側面板將設計轉換到可重複使用的購物袋上,鳳梨標誌為黑色,由市場中的一個人手持,強調品牌的親和力和環保理念。</td> </tr> </tbody> </table>
3. 在 ComfyUI 中使用 Flux 和 In-Context LoRA#
此 Flux 和 In-Context LoRA 工作流程利用了 Flux 模型和 In-Context LoRA 的強大組合,根據文本提示生成一組相關圖像。讓我們逐步分解它的工作原理。
3.1. 預載的 Flux 和 In-Context LoRA 模型以提高工作效率#
我們的平台已經為您準備了 Flux 模型和 10 個 In-Context LoRA 模型。這使得您的工作流程更輕鬆,並節省您的時間。只需選擇您想要的組,然後開始創作。
3.2. 根據預設提示創建完美提示#
此工作流程中最重要的部分是捕捉您想要創建的主要想法的文本描述。我們已經為前面提到的每個 In-Context LoRA 模型編寫了提示。在您編寫自己的提示時,請使用這些示例作為指導。
3.3. 自定義分辨率和尺寸#
要創建完全符合您需求的視覺效果,請更改寬度和高度設置以匹配您想要的大小。我們還提供了每個 In-Context LoRA 模型的推薦尺寸,供您作為起點使用。
3.4. Flux 取樣器#
Flux 取樣器節點管理 Flux 取樣過程並優化生成參數以獲得更好的結果。關鍵參數包括:
- 種子 (1):種子值確保在相同設置下產生一致的輸出。調整種子允許 Flux 生成產生不同的結果。
- 步驟 (50):此參數定義 Flux 取樣過程中的步驟數。更高的步數提高質量,但需要更多的處理時間。在此,50 步提供了一個平衡的選擇。
- 指導 (3):確定指導強度。更高的值(例如 3)使 Flux 生成的輸出更貼近輸入提示,確保準確地呈現您的意圖。
- 最大偏移量 (null):此參數定義最大位移或變換範圍。"null" 設置表示使用默認或無限制範圍。
- 基本偏移量 (null):類似於最大偏移量,它調整基本變換強度。將其設置為 "null" 即應用默認配置。
- 去噪 (1):調整 Flux 生成過程中的去噪強度。值為 1 時應用輕微去噪,有效去除小的不一致性,同時保持清晰度。
Flux 和 In-Context LoRA 的結合為創建有趣的視覺內容開啟了無限可能。嘗試這些新模型,讓您的創造力前所未有地釋放。
許可證#
查看許可文件:
flux/model_licenses/LICENSE-FLUX1-dev
flux/model_licenses/LICENSE-FLUX1-schnell
FLUX.1 [dev] 模型由 Black Forest Labs. Inc. 根據 FLUX.1 [dev] 非商業許可授權。版權所有 Black Forest Labs. Inc.
在任何情況下,Black Forest Labs, Inc. 均不對因使用此模型而產生的任何索賠、損害或其他責任承擔責任,無論是合同、侵權還是其他方面。

