
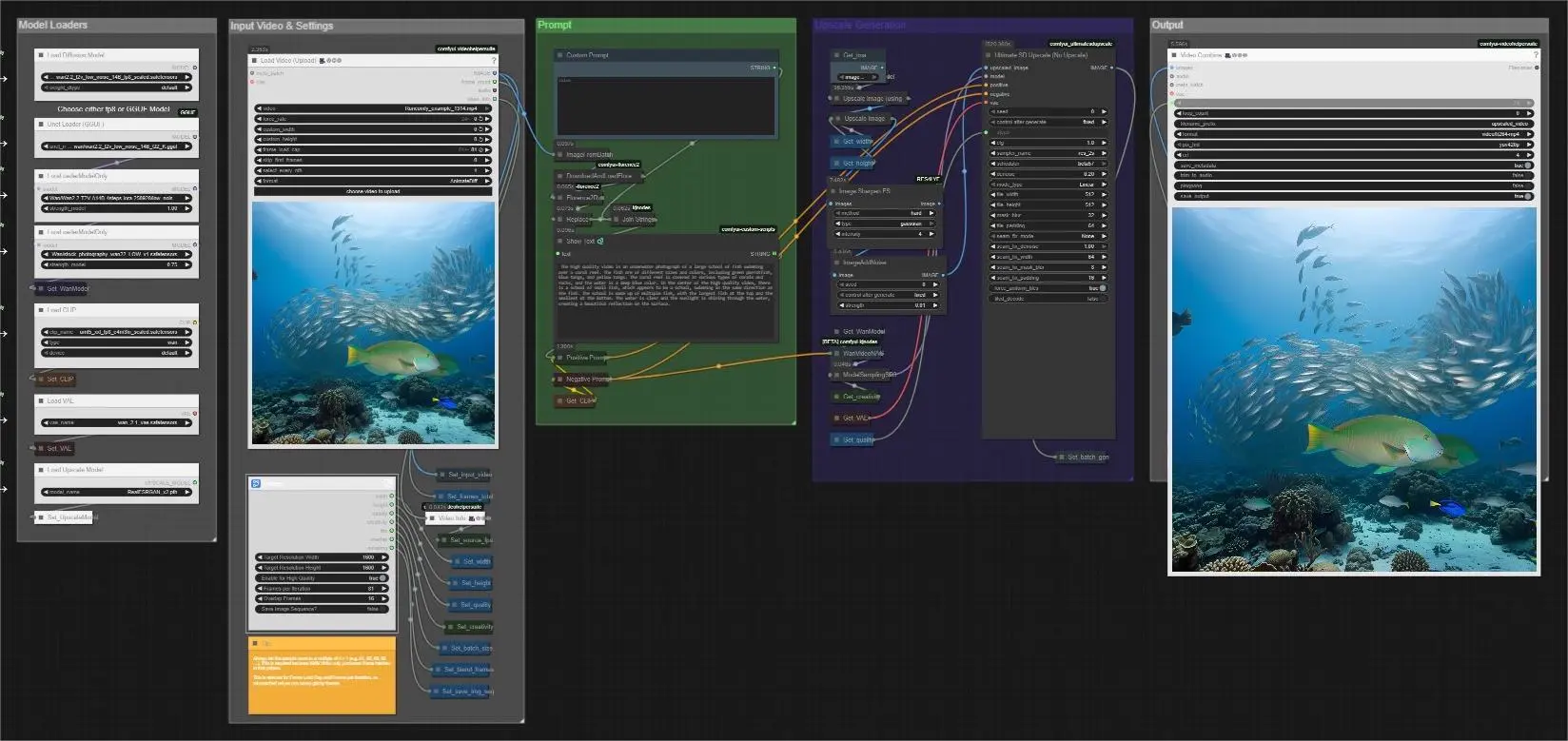
Easy Video Upscaler for Footage#
Easy Video Upscaler for Footage is a streamlined ComfyUI pipeline by Mickmumpitz that upgrades the clarity, texture and perceived resolution of existing videos with minimal setup. It combines fast super-resolution, detail-friendly sharpening, and Wan 2.x diffusion refinement to restore fine structure while keeping motion natural. Whether you are modernizing archival recordings, improving AI-generated clips or preparing delivery masters, the Easy Video Upscaler for Footage workflow emphasizes consistency across frames, smooth transitions between batches and dependable output.
The workflow accepts a single input video, auto-reads its frame rate, generates or accepts a guiding prompt, and processes frames in blendable batches so long sequences remain seamless. You can choose a lightweight GGUF model for low-VRAM systems or an FP8 UNet for maximum fidelity, then steer the refinement with a simple creativity control. Final results are saved as an upscaled video, with an optional image-sequence path for large projects.
Key models in ComfyUI Easy Video Upscaler for Footage workflow#
- Wan 2.2 T2V Low Noise 14B UNet (FP8 or GGUF). Core generative backbone used for diffusion-based refinement that enhances detail while respecting the source frames. Hugging Face: Comfy-Org/Wan_2.2_ComfyUI_Repackaged and Hugging Face: bullerwins/Wan2.2-T2V-A14B-GGUF
- Wan 2.1 VAE. Decoder that preserves texture and tone when moving between latent and pixel space during refinement. Hugging Face: Comfy-Org/Wan_2.1_ComfyUI_repackaged
- UMT5-XXL text encoder (FP8). Text backbone used for prompt conditioning that aligns instructions with the WAN model. Included in the Wan 2.1 repackaged assets. Hugging Face: Comfy-Org/Wan_2.1_ComfyUI_repackaged
- RealESRGAN x2. Classical super-resolution model that cleanly boosts frame size before diffusion-based detail recovery. GitHub: xinntao/Real-ESRGAN
- Microsoft Florence-2 Large. Vision-language model used here to auto-caption a representative frame, providing a high-quality prompt when you do not want to write one. Hugging Face: microsoft/Florence-2-large
- Optional LoRA add-ons for WAN 2.2. Lightweight adapters that can nudge the refinement toward specific looks without overpowering the footage. For example, the “Lightning” low-noise 4-step LoRA. Hugging Face: lightx2v/Wan2.2-Lightning
How to use ComfyUI Easy Video Upscaler for Footage workflow#
The pipeline follows a clear path from input to output and organizes controls into groups so you always know where to adjust quality, speed and memory behavior.
Model Loaders#
This group initializes the core model stack and lets you pick either the FP8 safetensors UNet or a GGUF-quantized UNet for Wan 2.2. Use the GGUF path when VRAM is tight, or the FP8 UNet when you want the highest fidelity. The Wan 2.1 VAE and UMT5-XXL text encoder are loaded here so prompts can guide the later diffusion step. If you plan to use a LoRA, load it in this group before running.
Input Video & Settings#
Drop in your source clip with VHS_LoadVideo (#130). The workflow reads the source frame rate via VHS_VideoInfo (#298) so the final render matches motion cadence. Set your target width and height, choose whether to enable the high-quality mode, and adjust the creativity control to decide how strictly the refinement should adhere to your input. For long clips, set frames per iteration and an overlap value to blend batches cleanly, and enable the image-sequence save option when you want maximum stability or are working at very high resolution.
Prompt#
You can type a custom prompt or let the workflow build one for you. A single frame is sampled and captioned by Florence2Run (#147), then lightly rewritten by StringReplace (#408) and merged with any custom text via JoinStrings (#339). The combined prompt is shown by ShowText|pysssss (#135) and passed to Positive Prompt (#3), while Negative Prompt (#4) contains artifact-reduction terms. This keeps prompts consistent and fast to manage, especially for batch jobs.
Upscale Generation#
Frames are pre-upscaled with ImageUpscaleWithModel (#303) using RealESRGAN, then resized precisely with ImageScale (#454) to your target resolution. Image Sharpen FS (#452) restores edge snap when needed and ImageAddNoise (#421) adds a small controlled noise that helps the diffusion pass rebuild realistic micro-texture. The WAN model is prepared with WanVideoNAG (#115) and ModelSamplingSD3 (#419), then UltimateSDUpscaleNoUpscale (#126) performs tiled, prompt-guided refinement that respects global structure and motion continuity.
Batch Creator + Blend Generated Batches#
Long videos are split into blendable batches automatically. This subgraph computes the number of iterations, shows it in “Number of Iterations,” and assembles each image batch while accounting for your overlap setting. At the boundaries between batches, ImageBatchJoinWithTransition (#244) mixes frames so the seam is unobtrusive. Use more overlap when cuts are obvious, and reduce it to speed things up when scenes are stable.
Output Blend Saved Image Sequence#
When “Save Image Sequence” is enabled, each iteration writes its frames to disk, which is helpful for very high resolutions or limited memory. The workflow later reloads those frames with VHS_LoadImagesPath (#396), optionally blends the batch ends again and assembles them into a continuous sequence. This path provides a robust recovery route if you stop and resume processing.
Output#
The final frames are compiled to a video by VHS_VideoCombine (#128) using the source frame rate captured earlier, so motion remains smooth and true to the original. You can also emit an intermediate preview or write a second final from the saved sequence path using VHS_VideoCombine (#393). Filenames and subfolders are auto-incremented to keep each run tidy.
Key nodes in ComfyUI Easy Video Upscaler for Footage workflow#
VHS_LoadVideo (#130)#
Loads the input clip and exposes images, frame count and a video_info blob. If you intend to process just a portion, limit the frame load in the node and align “Frames per Iteration” accordingly. Keeping loader and batch settings in sync prevents stutter or gaps when batches are stitched.
ImageUpscaleWithModel (#303)#
Applies RealESRGAN for a quick, artifact-resistant size boost prior to diffusion. Use it to reach or approach your target resolution before refinement so the WAN pass can focus on texture and fine detail instead of large-scale resizing. If your source already matches target size, you can still keep this stage for denoising and structure reinforcement.
UltimateSDUpscaleNoUpscale (#126)#
Runs the WAN diffusion refinement in tiles with seam fixing and optional tiled decode to preserve global structure. The few controls that matter here are the sampler steps, denoise strength and seam-related options; higher steps and denoise produce a more assertive look, while lower settings hew closer to your original frames. When you enable high quality in the Settings group, this node automatically adjusts step depth.
WanVideoNAG (#115) and ModelSamplingSD3 (#419)#
This pair hooks the WAN model into the sampler and exposes a creativity shift. Lower creativity keeps the output close to the input with gentle enhancement, while higher values add more generative texture and can invent details. For documentary, interviews or archival work, prefer conservative values; for synthetic or AI-originated clips, you can push a bit further.
ImageBatchJoinWithTransition (#244)#
Blends the tail of one batch with the head of the next to hide stitch marks. Increase the number of transitioning frames when you notice luminance or texture jumps, and reduce it for faster runs when scenes are uniform. This is the main lever that keeps the Easy Video Upscaler for Footage pipeline seamless on long timelines.
VHS_VideoCombine (#128)#
Assembles the final video at the source fps captured upstream. If you saved image sequences, you can switch to the alternate combine node to render from disk without reprocessing. This node is also where you set container and pixel format when needed.
Optional extras#
- Pick one WAN path. Use FP8 UNet for best quality on strong GPUs, or the GGUF UNet for low-VRAM workstations and laptops.
- Keep motion natural. Start with low creativity for live action or documentary footage, then increase gradually if you need more texture recovery.
- Plan batches up front. On long clips, enable “Save Image Sequence” so you can resume or re-render the final without recomputing diffusion.
- Match frame math. Set frames per iteration so it aligns with your loader’s cap and overlap; the Easy Video Upscaler for Footage batch tools will compute iterations and blend edges for you.
- Use LoRA sparingly. Add a WAN 2.2 LoRA when you need a specific look, and lower its weight if it starts to overpower the scene’s original character.
Acknowledgements#
This workflow implements and builds upon the following works and resources. We gratefully acknowledge Mickmumpitz for the Easy Video Upscaler for Footage workflow for their contributions and maintenance. For authoritative details, please refer to the original documentation and repositories linked below.
Resources#
- YouTube/Easy Video Upscaler for Footage
- Docs / Release Notes: YouTube @ Mickmumpitz
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.
