
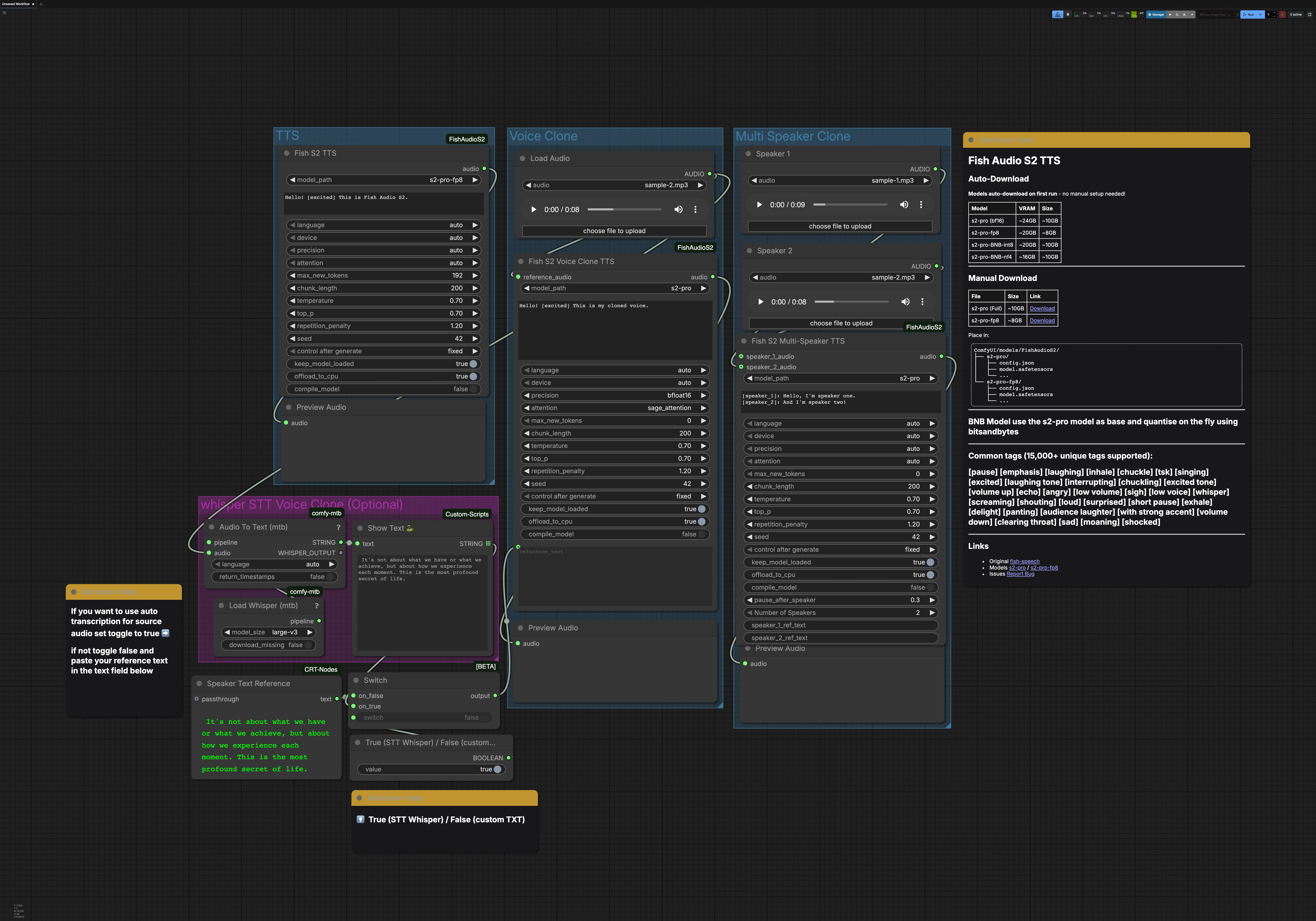
Fish Audio S2 TTS for ComfyUI:高質量 TTS、語音複製和多講者對話#
Fish Audio S2 TTS 是一個即用型 ComfyUI 工作流程,可以將文本轉換為自然語音,從短參考片段中複製聲音,並生成多講者對話。它由 Fish Audio S2‑Pro 系列驅動,並通過情感和韻律標籤(如 [excited]、[whisper] 和 [laughing])支持豐富的風格控制。
此工作流程非常適合希望在 ComfyUI 中進行靈活、富有表情的語音合成的創作者、產品團隊和開發者。它包括可選的語音轉文本功能,用於快速轉錄捕獲、自動語言檢測和多種精度選擇,包括 fp8 和 sage_attention,用於高效推理。
注意: 在 2X Large 或更大的機器上運行此工作流程。較小的實例可能會出現內存不足(OOM)。
Comfyui Fish Audio S2 TTS 工作流程中的關鍵模型#
- Fish Audio S2‑Pro — 用於單講者 TTS、語音複製和多講者對話的核心生成文本轉語音模型。支持廣泛的風格標籤和多語言合成 model card,並且是 Fish‑Speech 項目的一部分 repo。
- Fish Audio S2‑Pro FP8 — S2‑Pro 的一個內存高效變體,能夠在最小質量損失的情況下減少 VRAM 需求,推薦用於受限的 GPU model card。
- OpenAI Whisper large‑v3 — 可選的語音轉文本模型,用於在準備語音複製提示時自動轉錄您的參考音頻 repo。
如何使用 Comfyui Fish Audio S2 TTS 工作流程#
此工作流程包含三個可以獨立運行的主要路徑:TTS、Voice Clone 和 Multi Speaker Clone。一個可選的 Whisper STT 組可以生成語音複製的轉錄。每個路徑最後都有音頻預覽,因此您可以快速監控結果。
TTS 組#
FishS2TTS (#42) 節點執行直接的文本轉語音,使用 Fish Audio S2 TTS。在節點的文本框中輸入您的腳本,並添加風格標籤,如 [excited]、[pause] 或 [whisper],以塑造情感和節奏。語言檢測是自動的,因此您可以用目標語言書寫,模型會自適應。選擇適合您 GPU 記憶體的 S2‑Pro 變體,例如 fp8 用於較輕的負載。輸出路由到 PreviewAudio 以便立即收聽。
Voice Clone 組#
使用 LoadAudio 提供目標聲音的短而乾淨的參考剪輯,然後將其路由到 FishS2VoiceCloneTTS (#14)。提供匹配您想要的說話風格的轉錄;準確的文本有助於模型保留節奏和口音。您可以從 STT 組驅動參考文本或自行輸入,並可以添加風格標籤以完善情感和表達。精度和注意力後端選擇在長線條中平衡速度、記憶體和穩定性。合成的克隆被發送到 PreviewAudio,以便您快速迭代。
Multi Speaker Clone 組#
使用 LoadAudio 節點為每個講者加載一個參考剪輯,然後將它們連接到 FishS2MultiSpeakerTTS (#41)。提供一個對話腳本,標記每個回合的 [speaker_1]、[speaker_2] 等。此模板默認包含兩個講者,並且節點支持擴展到多達八個不同的聲音。您可以混合敘述性散文、標籤和對話,以控制每個角色的流動和情感。最終的混音將被預覽,以便驗證時間和清晰度。
Whisper STT 用於語音複製(可選)#
Load Whisper (mtb) (#6) 與 large‑v3 為 Audio To Text (mtb) (#7) 提供動力,以自動轉錄參考剪輯。識別的文本由 ShowText|pysssss (#8) 顯示。一個小的切換開關由 ComfySwitchNode (#34) 和一個布爾控制構建,讓您在 STT 輸出(true)和您自己輸入的文本 Text Box line spot (#31)(false)之間選擇。這在您需要快速的基線轉錄或創建精確的複製提示時非常有用。
Comfyui Fish Audio S2 TTS 工作流程中的關鍵節點#
FishS2TTS (#42)#
通過可選的風格標籤和自動語言檢測從文本生成單講者語音。調整模型變體以匹配您的硬件,例如在 VRAM 緊張時選擇 fp8。使用種子控制以進行可重複的採集,並在探索替代交付時引入小變化。對於長腳本,選擇一個針對穩定性優化的注意力後端。
FishS2VoiceCloneTTS (#14)#
通過 reference_audio 和 reference_text 進行條件設定來創建複製的聲音。來自乾淨語音的結果更好,具有一致的語調和反映預期節奏的轉錄。風格標籤可以混合到最終文本中,以引導情緒,而不會損害身份。精度和注意力設置有助於在長線條中平衡質量和記憶體。
FishS2MultiSpeakerTTS (#41)#
通過將每個講者的參考音頻與帶有 [speaker_n] 標籤的對話配對來合成多講者對話。根據需要增加講者數量,並分配不同的剪輯以加強分離。保持每個講者的參考語調一致,以避免混合。在渲染多次拍攝場景時,使用種子進行確定性混音。
可選擇的額外功能#
- 謹慎使用風格標籤。從少量開始,如 [excited]、[whisper]、[emphasis]、[pause],僅在需要時增加以達到清晰度。
- 對於語音複製,從參考的開始和結尾修剪靜音,並避免背景噪音以保持音色。
- 如果 GPU 記憶體有限,首選 S2‑Pro fp8 或運行時量化選項。為獲得最大保真度,使用更高的精度。
- 標點符號很重要。逗號和句號改善措辭,並且在子句邊界放置的標籤通常聽起來更自然。
- 對於多講者腳本,保持每行一個話語,並始終以正確的 [speaker_n] 標籤前綴以保持分離。
資源:
- Fish Audio S2‑Pro 模型卡:Hugging Face
- S2‑Pro fp8 變體:Hugging Face
- Fish‑Speech 項目:GitHub
- ComfyUI Fish Audio S2 節點:GitHub
- Whisper large‑v3:GitHub
致謝#
此工作流程實施並基於以下作品和資源。我們感謝 Saganaki22 對 ComfyUI-FishAudioS2 自定義節點的貢獻,以及 Fish Audio 對 S2-Pro 模型的貢獻和維護。有關權威詳細信息,請參考下面鏈接的原始文檔和存儲庫。
資源#
- Saganaki22/ComfyUI-FishAudioS2 自定義節點
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro 模型
- Hugging Face: fishaudio/s2-pro
注意:使用所引用的模型、數據集和代碼受其作者和維護者提供的相應許可和條款約束。