
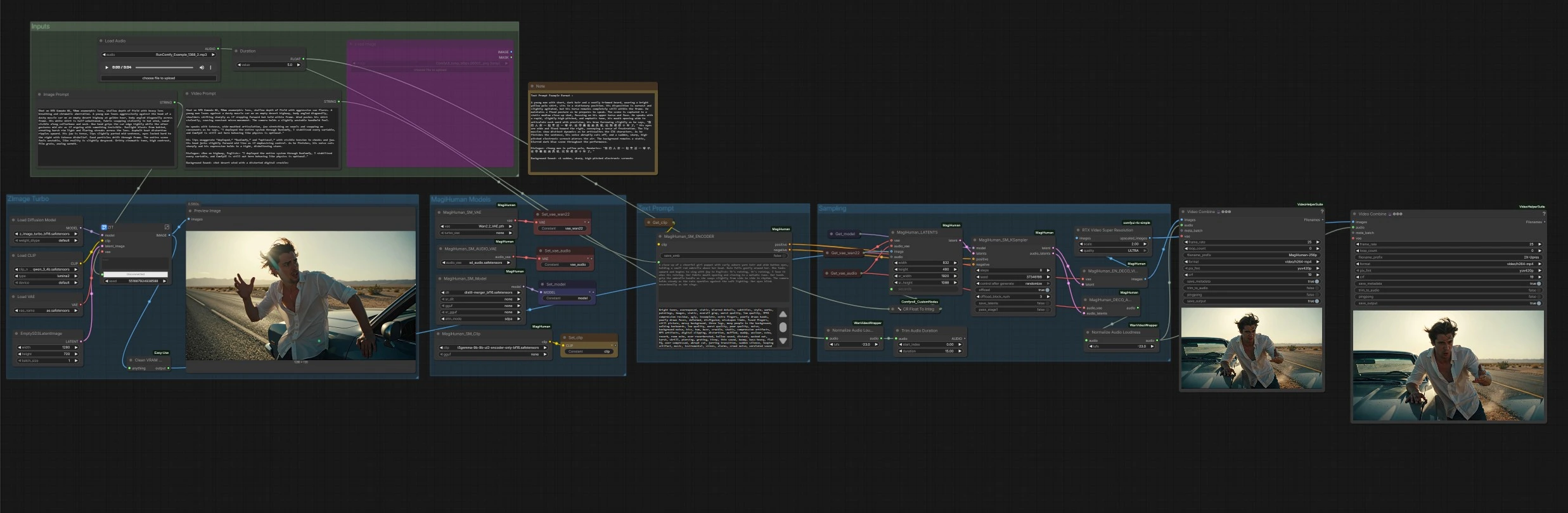
daVinci-MagiHuman 談話數位人類工作流程適用於 ComfyUI#
此 ComfyUI 工作流程圍繞 daVinci-MagiHuman 構建了一個完整的文本到視頻管道,以生成具有同步語音、唇形運動、表情和身體微運動的逼真數位人類。它專為希望從描述性提示到帶有清晰音頻的 MP4 的快速單擊路徑的創作者而設計。該圖可以為新生成的肖像或任何提供的參考圖像製作動畫,然後將視頻和語音一起渲染,最後完成可選的升頻和自動音頻響度標準化。
daVinci-MagiHuman 核心使用單流 Transformer 從一個提示共同生成視頻和音頻,這有助於即使在短片中也能保持時序和唇形同步的保真度。此 ComfyUI 實現保持控制簡單:書寫圖像提示以定義外觀,書寫視頻提示以定義表演和對話,設置片段持續時間並運行。
ComfyUI daVinci-MagiHuman 工作流程中的關鍵模型#
- daVinci-MagiHuman (15B 單流音視頻生成器)。角色:從文本共同生成視頻幀和語音,同時保持時間一致性和唇形同步。參考:GitHub,arXiv,Hugging Face。
- T5Gemma 9B 編碼器 (UL2 自適應)。角色:將視頻提示編碼為豐富的條件,以引導 daVinci-MagiHuman 的運動、傳遞和風格。參考:Hugging Face。
- Z-Image Turbo 擴散模型。角色:快速從圖像提示生成高質量的靜態肖像,作為動畫的身份/參考。參考:Hugging Face (z_image_turbo),Hugging Face (z_image)。
- Qwen 3 4B 文本編碼器用於 Z-Image Turbo。角色:解析圖像提示以指導肖像生成。參考:Hugging Face 檔案。
- Wan 2.2 VAE。角色:將 MagiHuman 視頻潛變量解碼為具有強時間一致性的 RGB 幀。參考:GitHub,Hugging Face 示例模型。
- Audio VAE (sd_audio)。角色:將 MagiHuman 音頻潛變量解碼為語音波形,與最終視頻合成。參考:MagiHuman 的自定義節點包 GitHub。
- RTX Video Super Resolution (可選)。角色:在最終編碼前後升頻解碼幀,增加感知清晰度並減少壓縮伪影。參考:ComfyUI 包裝器 GitHub。
如何使用 ComfyUI daVinci-MagiHuman 工作流程#
總體流程:Z-Image Turbo 組從您的圖像提示創建身份肖像。MagiHuman 模型組加載 daVinci-MagiHuman 檢查點、視頻 VAE 和音頻 VAE,並準備文本編碼器。文本提示組將您的視頻提示轉換為條件。採樣組將參考圖像和提示融合為聯合視頻和音頻潛變量,然後解碼兩者。最後,輸出階段將幀與音頻合併為 MP4,並提供可選的升頻版本。
輸入#
使用圖像提示和視頻提示文本框描述外觀和表演。持續時間控制設置片段長度(以秒為單位)。如果您計劃實驗音頻驅動的變體,音頻加載器會提供方便,但此模板默認以文本驅動模式運行。
ZImage Turbo#
此階段使用 Z-Image Turbo UNet 和其捆綁的 VAE 從圖像提示渲染單個參考肖像。它針對快捷、乾淨的身份生成和電影外觀進行優化。結果預覽後,作為動畫的參考圖像轉發。如果您已經有頭像,可以通過直接將圖像連接到動畫階段來繞過這一步。
MagiHuman 模型#
此處圖形加載 daVinci-MagiHuman 基礎或精鍊檢查點以及 Wan 2.2 視頻 VAE、音頻 VAE 和 T5Gemma 編碼器。這保持文本編碼、視頻潛變量和音頻潛變量對齊以進行單流採樣。如果您在環境中有可用的替代權重,可以替換。
文本提示#
您的視頻提示被編碼為正面和負面條件。正面文本應描述相機距離、姿勢、語言、傳遞風格和精確的對話內容。負面文本可以列出要避免的視覺或音頻缺陷。編碼器將兩組條件饋送到採樣器中,塑造運動、唇動力學和音色。
採樣#
採樣器從參考圖像和請求的持續時間構建初始潛變量序列,然後使用 daVinci-MagiHuman 進行降噪以生成同步的視頻和音頻潛變量。實用程序將持續時間轉換為整秒以進行穩定調度。當採樣完成時,視頻潛變量進入視頻解碼器,音頻潛變量進入音頻解碼器。
解碼、響度和導出#
視頻潛變量使用 Wan 2.2 VAE 解碼為圖像幀。音頻潛變量解碼為語音,然後正規化為廣播友好的響度,以便最終 MP4 在各種設備上穩定播放。生成兩個導出:一個基礎渲染和一個使用 RTX Video Super Resolution 的可選升頻渲染。兩者均合併為 MP4 並保存,帶有清晰的文件名前綴。
ComfyUI daVinci-MagiHuman 工作流程中的關鍵節點#
MagiHuman_LATENTS(#13)
構建視頻和可選音頻的聯合潛變量畫布,採用參考圖像和片長。調整 seconds 設置持續時間,確保您的參考圖像為您描述的運動良好地構圖。更高的基礎解析度有助於面部保真度,但也會增加 VRAM 和解碼時間。
MagiHuman_SM_ENCODER(#95)
將視頻提示編碼為正面和負面條件供採樣器使用。將確切的語句用引號括起來,並命名語言以改善唇形閉合和時序。使用負面字段抑制諸如“字幕”、“靜態”或“房間迴聲”之類的伪影。
MagiHuman_SM_KSampler(#9)
運行 daVinci-MagiHuman 降噪以共同生成視頻和語音潛變量。seed 控制重現性,而 steps 和內部計劃在速度與細節和運動穩定性之間進行權衡。要變化而不失去身份,請更改 seed 或輕微重述提示的表演部分。
MagiHuman_EN_DECO_VIDEO(#5)
使用 Wan 2.2 VAE 將視頻潛變量解碼為 RGB 幀以供導出或升頻。使用此路徑進行最快的端到端渲染;長片或更高的解析度將線性增加解碼時間。
MagiHuman_DECO_AUDIO(#6)
將音頻潛變量解碼為波形,然後通過響度正規化以實現均勻播放。如果您稍後切換到音頻驅動的生成,請將外部音頻路由到潛變量生成器,並保持此解碼路徑以進行最終合成。
RTXVideoSuperResolution(#93)
可選的後升頻器,銳化邊緣並減少鈴聲。使用適度的強度以提高清晰度而不會引入時間抖動。
可選附加功能#
- 可靠的唇形同步提示模式:包括說話者標籤和語言以及引號中的語句,例如對話:<Presenter, English>: "Welcome to the show." 添加關於傳遞、鏡頭大小和相機穩定性的簡要說明。
- 保留參考肖像作為中等特寫,頭部完全在框架內。緊密裁剪留給下巴和面頰動態的空間很少。
- 如果您需要更嚴格的時序,請修剪或擴展腳本以匹配選定的持續時間。非常長的句子在非常短的片段中可能會導致不自然的發音。
- 此模板運行在僅提示模式。對於音頻驅動的測試,將外部音頻文件連接到
MagiHuman_LATENTS(#13) 的音頻輸入,並調整您的視頻提示以描述表情而不是說話內容。
致謝#
此工作流程實現並建立在以下作品和資源之上。我們感謝 daVinci-MagiHuman 為 daVinci-MagiHuman 工作流程源的貢獻和維護。欲了解權威詳情,請參考下文鏈接的原始文檔和存儲庫。
資源#
- daVinci-MagiHuman/Workflow Source
- 文檔 / 發布說明:daVinci-MagiHuman Workflow Source
注意:所引用的模型、數據集和代碼的使用受其作者和維護者提供的相關許可和條款的約束。
