
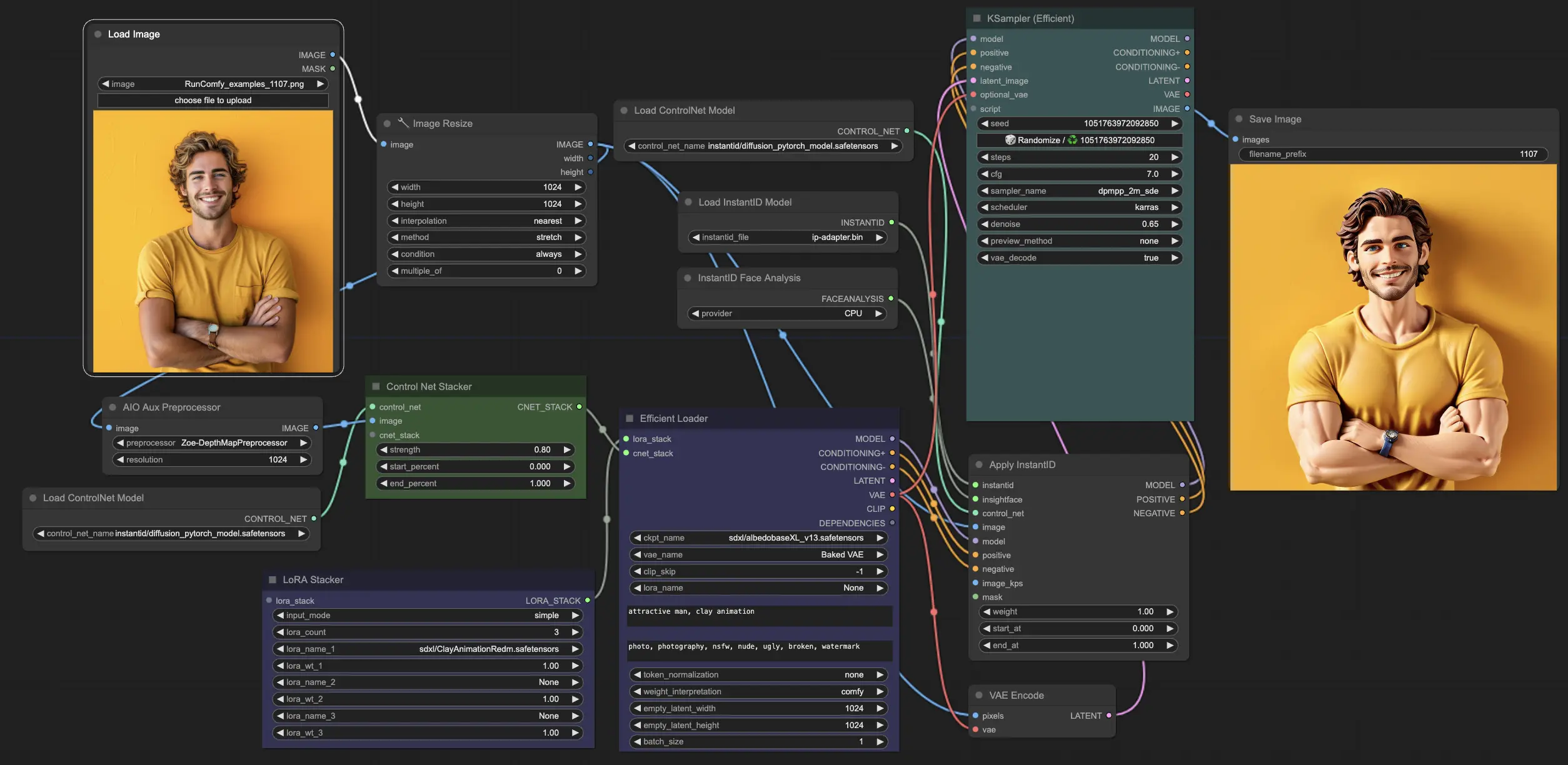
什麼是 Face-to-Many?#
Face-to-many 是 ComfyUI 中一個強大的工作流程,允許您輕鬆將單一面部圖像轉換為多種藝術風格。通過在 ControNet 模型中利用 InstantID 技術,您可以在保持原始圖像的關鍵面部特徵和身份的同時,生成多種風格的個性化圖像,如 3D、表情符號、像素藝術、電子遊戲、黏土或玩具美學。
Face-to-Many 如何運作?#
ComfyUI 中的 Face-to-many 工作流程利用了幾個關鍵組件來實現其令人印象深刻的效果:
1. InstantID#
Face-to-many 工作流程的核心是 InstantID 模型,其專門用於保持身份的個性化圖像合成。它在不同的藝術轉換中映射並保留關鍵面部點和屬性,確保對原始面部的高度保真度。
2. ControlNet#
ControlNet 模型用於通過提供額外的控制和一致性來引導圖像生成過程。它有助於在不同藝術風格的轉換中保持原始面部圖像的結構和關鍵特徵。
3. Lora models#
不同的 Lora 模型用於定義可以應用於面部圖像的特定藝術風格。通過選擇適當的 Lora 模型,您可以將面部轉換為 3D、表情符號、像素藝術、電子遊戲、黏土或玩具風格。
步驟教學:在 ComfyUI 中使用 Face-to-Many#
要使用 Face-to-Many 工作流程生成多種風格的個性化圖像,請按照以下步驟:
1. 上傳面部圖像:#
使用 "LoadImage" 節點上傳您想要轉換的單一面部圖像。確保圖像質量和分辨率足以達到最佳效果。
2. 選擇 Face-to-Many 的所需風格#
在 "LoRA Stacker" 節點中,選擇對應於您想要應用的風格的 Lora 模型。風格與 Lora 模型的對應如下:
- 3D: sdxl/3DRedmond-3DRenderStyle-3DRenderAF.safetensors
- Emoji: sdxl/fofr/emoji.safetensors
- Video game: sdxl/PS1Redmond-PS1Game-Playstation1Graphics.safetensors
- Pixels: sdxl/PixelArtRedmond-Lite64.safetensors
- Clay: sdxl/ClayAnimationRedm.safetensors
- Toy: sdxl/ToyRedmond-FnkRedmAF.safetensors
3. 調整設置和提示以獲得更好的 Face-to-Many 結果#
在 "EfficientLoader" 節點中提供風格特定的提示以引導圖像生成過程。
- 3D: 3D Style
- Emoji: Emiji Style
- Video game: PS1 Style
- Pixels: Pixels Arty
- Clay: Clay Animation
- Toy: Toy Style
4. 生成 Face-to-Many 圖像:#
一旦所有設置配置完成,運行 Face-to-Many 工作流程以生成選定風格的個性化圖像。 可以隨意嘗試不同風格、提示和設置的組合以達到理想的結果。
通過利用 ComfyUI 中的 Face-to-Many 工作流程,您可以輕鬆地將單一面部圖像轉換為多種引人入勝的藝術風格。無論您想創建 3D 渲染、表情符號版本或電子遊戲角色,Face-to-Many 提供了一種無縫且高效的方式來生成個性化圖像,同時保持原始面部的身份。
欲了解更多信息並查看原始作品,請訪問作者 fofr 的 GitHub 頁面:fofr。許多 loras 是由 artificialguybr 製作的。您可以通過 Patreon 或 Ko-fi 支持 artificialguybr 的工作,或在 Twitter 上關注 artificialguybr:artificialguybr。
