
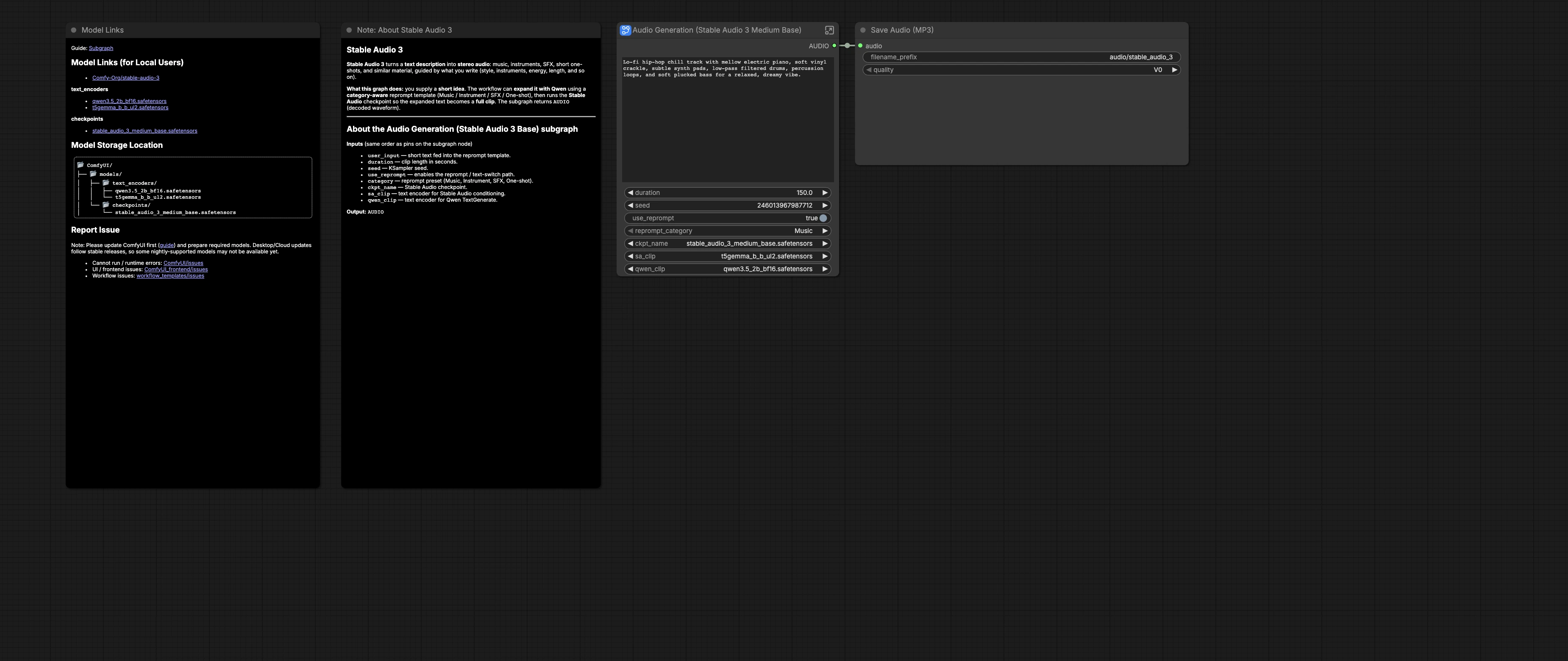
Stable Audio 3.0 Medium Base 在 ComfyUI 中的长文本到音频工作流程#
此 Stable Audio 3.0 Medium Base 工作流程将短文本想法转化为更长、更具音乐感的立体声音频。它围绕 stable_audio_3_medium_base 检查点构建,使用 T5-Gemma 和 Qwen3.5 文本编码器来提供以提示为驱动的音乐草图、环境床、音效和单次声音,并在 ComfyUI 中具有可重复的设置。
图中包括一个可选的类别感知重提示系统,可以在合成之前将您的简短想法扩展为密集、生产就绪的提示。您选择类别、时长和种子,然后管道条件稳定音频3并生成音频,保存为 MP3。工作流程遵循 Comfy-Org 为 Stable Audio 3.0 Medium Base 提供的官方模板和资产。请参阅 Comfy-Org/workflow_templates 和 Comfy-Org/stable-audio-3 上的参考模板和模型。
Comfyui Stable Audio 3.0 Medium Base 工作流程中的关键模型#
- Stable Audio 3 Medium Base 检查点。核心生成模型,从文本条件和潜在变量合成立体声音频。来源:Comfy-Org/stable-audio-3。
- T5-Gemma Base UL2 文本编码器。生成用于条件 Stable Audio 3 的正负提示的文本嵌入。打包的文本编码器文件包含在 Stable Audio 3 存储库的 text_encoders 文件夹下:Comfy-Org/stable-audio-3。
- Qwen3.5 2B 文本模型。驱动可选的类别感知重提示,将简短想法扩展为详细的音乐、乐器、音效或单次描述。来源:Comfy-Org/Qwen3.5。
如何使用 Comfyui Stable Audio 3.0 Medium Base 工作流程#
在高层次上,您提供一个简短的想法和目标持续时间。图可以保持您的文字不变,或使用 Qwen3.5 通过类别模板重写它们。结果被编码为条件,由 Stable Audio 3 采样,解码为音频并保存。
用户输入:提示和持续时间#
子图 Audio Generation (Stable Audio 3 Medium Base) (#52) 暴露 user_input、duration、seed、use_reprompt 和 category。用简单的语言写一个简短的想法,例如风格、乐器列表、情绪和可选的 BPM。选择以秒为单位的剪辑长度并设置 seed 以实现可重复性或变化。当您希望进行模板驱动的重写时,打开 use_reprompt,然后选择一个 category,例如音乐、乐器、音效或单次声音。
加载器:检查点和文本编码器#
CheckpointLoaderSimple (#25) 加载 stable_audio_3_medium_base.safetensors,提供稍后用于采样和解码的 MODEL 和 VAE。CLIPLoader (#26) 加载用于条件的 T5-Gemma 编码器。第二个 CLIPLoader (#29) 加载驱动重提示阶段的 Qwen3.5 模型。
重提示:JSON 模板和类别#
类别选择器 CustomCombo (#43) 将大量系统提示的 JSON 提供给 JsonExtractString (#49)。选择的模板由 Text Replace (PROMPT TEMPLATE) (#38) 插入到元提示中。您的 user_input 由 Text Replace (USER INPUT) (#39) 注入,目标长度使用 Text Replace (AUDIO LENGTH) (#40) 插入,保持重写与您选择的持续时间一致。
重提示:Qwen TextGenerate#
TextGenerate (#28) 使用 Qwen3.5 将组装的模板加上您的想法转化为简洁、详细的提示,遵循类别特定规则。此阶段特别有助于较长的音乐结构和音效,其中具体的技术语言很重要。提示重写是可预览的,因此您可以快速迭代类别选择和措辞。
在原始和重写文本之间切换#
ComfySwitchNode (#34) 根据 use_reprompt 选择您的原始文本或 Qwen 生成的重写文本。打开它以获得结构化、长度匹配的重写,或关闭它以直接控制措辞。这个简单的开关使得 A/B 测试变得简单。
CLIP 编码:条件#
CLIPTextEncode (#6) 将选择的提示转换为驱动模型的正条件。默认情况下,第二个 CLIPTextEncode (#7) 提供中性负条件。这种配对为 Stable Audio 3 提供了清晰的指导,同时避免了意外的伪影。
音频生成:Stable Audio#
EmptyLatentAudio (#11) 创建一个音频潜在变量,其长度与 duration 匹配。KSampler (#3) 使用来自检查点的 Stable Audio 3 Medium Base MODEL 执行去噪过程。VAEDecodeAudio (#12) 将最终潜在变量转换为可听见的立体声波形。由于相同的 duration 也通知重提示,渲染的剪辑长度和重写文本保持同步。
保存和导出#
在子图之外,SaveAudioMP3 (#19) 将结果写入带有有用前缀的 MP3 文件以便于组织。批量生成具有不同 seed 值或类别的拍摄时使用此功能,然后试听并保留您喜欢的。
Comfyui Stable Audio 3.0 Medium Base 工作流程中的关键节点#
ComfySwitchNode(#34)。在原始user_input和 Qwen 生成的文本之间切换。打开它以获得结构化、长度匹配的重写,或关闭它以直接控制。TextGenerate(#28)。使用类别特定的系统提示运行 Qwen3.5 以扩展想法。要自定义重写样式,请编辑JsonExtractString(#49) 中的类别模板和相邻Text Replace节点中的粘合提示。EmptyLatentAudio(#11)。设置剪辑长度。保持这与插入的AUDIO_LENGTH标记对齐,以便合成时间与文本意图匹配。KSampler(#3)。管理稳定音频 3 的去噪轨迹。调整seed以获取变化,同时保持其他设置稳定,以便公平比较拍摄。SaveAudioMP3(#19)。控制输出文件名前缀和格式,以便从多次运行中快速构建库。
可选附加功能#
- 从一两句想法开始,命名类型或来源、主要乐器或纹理以及情绪。重提示可以填充 BPM 和编排等细节。
- 选择与您的目标匹配的类别:音乐用于完整曲目,乐器用于循环或干声,音效用于环境和动作,单次声音用于孤立的打击。
- 为您的目标内容保持持续时间现实。非常长的剪辑计算量较大,您在迭代时可能受益于稳定的
seed。 - 当结果感觉拥挤时,禁用重提示并尝试更简单的短语,然后在您喜欢方向时重新启用它。
- 为快速替代拍摄,保持所有设置不变,仅更改
seed。
致谢#
此工作流程实现并构建在以下作品和资源之上。我们感谢 Comfy-Org 提供的 ComfyUI Stable Audio 3 Day-0 Support 文章,Comfy-Org 提供的官方 Stable Audio 3.0 Medium Base 工作流程模板,Comfy-Org 提供的 Stable Audio 3 模型文件,以及 Comfy-Org 提供的 Qwen3.5 编码器模型文件的贡献和维护。有关权威详情,请参阅下面链接的原始文档和存储库。
资源#
- Comfy-Org/ComfyUI Stable Audio 3 Day-0 Support 文章
- 文档 / 发布说明:Stable Audio 3 Day-0 Support
- Comfy-Org/Official Stable Audio 3.0 Medium Base Workflow Template
- GitHub: Comfy-Org/workflow_templates
- Comfy-Org/Stable Audio 3 模型文件
- Hugging Face: Comfy-Org/stable-audio-3
- Comfy-Org/Qwen3.5 编码器模型文件
- Hugging Face: Comfy-Org/Qwen3.5
注意:使用参考的模型、数据集和代码需遵循其作者和维护者提供的相应许可证和条款。
