






Nunchaku Qwen 图像多图像编辑和合成用于 ComfyUI#
Nunchaku Qwen 图像是一个基于提示的多图像编辑和合成工作流程,适用于 ComfyUI。它接受多达三张参考图像,让您指定它们如何混合或转换,并通过自然语言指导生成一致的结果。典型的用例包括合并主体、更换背景或从一张图像到另一张图像的风格和细节转移。
围绕 Qwen 图像系列构建,此工作流程为艺术家、设计师和创作者提供精确控制,同时保持快速和可预测。它还包括单图像编辑路径和纯文本到图像路径,因此您可以在一个 Nunchaku Qwen 图像管道中生成、完善和合成。
注意:请选择 Medium 到 2XLarge 范围内的机器类型。使用 2XLarge Plus 或 3XLarge 机器类型不受支持,将导致运行失败。
Comfyui Nunchaku Qwen 图像工作流程中的关键模型#
- Nunchaku Qwen 图像编辑 2509。编辑调整的扩散/DiT 权重,优化用于提示引导的图像编辑和属性转移。擅长局部编辑、对象替换和背景更改。 Model card
- Nunchaku Qwen 图像(基础)。基于文本到图像分支的基础生成器,用于无源照片的创意合成。 Model card
- Qwen2.5-VL 7B 文本编码器。多模态语言模型,解释提示并将其与视觉特征对齐以进行编辑和生成。 Model page
- Qwen 图像 VAE。变分自动编码器,用于将源图像编码为潜在变量,并使用真实的颜色和细节解码最终结果。 Assets
如何使用 Comfyui Nunchaku Qwen 图像工作流程#
此图包含三个独立的路线,分享相同的视觉语言和采样逻辑。根据您是编辑多张图像、精炼单张图像还是从文本生成,使用一个分支。
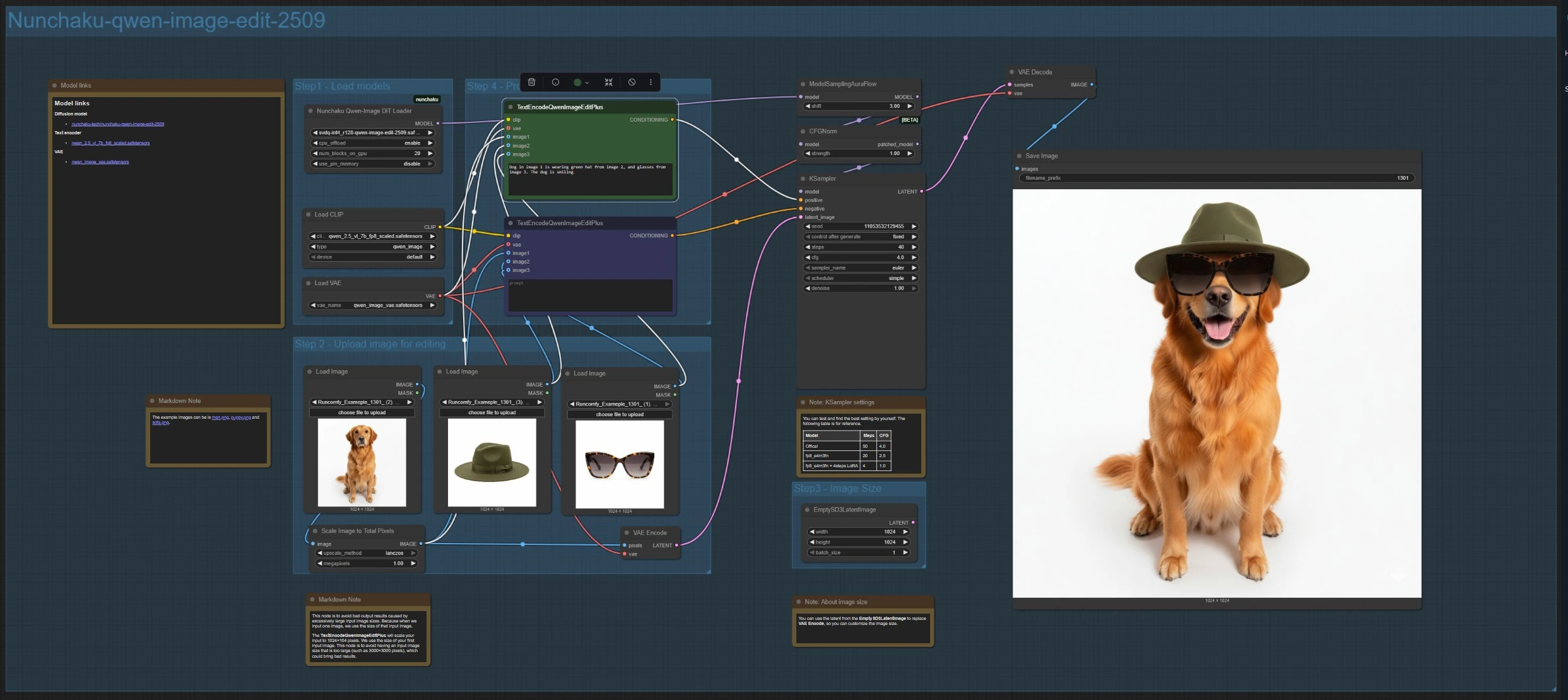
Nunchaku-qwen-image-edit-2509(多图像编辑和合成)#
此分支加载编辑模型 NunchakuQwenImageDiTLoader (#115),通过 ModelSamplingAuraFlow (#66) 和 CFGNorm (#75) 路由,然后使用 KSampler (#3) 合成。使用 LoadImage (#78, #106, #108) 上传多达三张图像。主要参考由 VAEEncode (#88) 编码以设置画布,ImageScaleToTotalPixels (#93) 保持输入在稳定的尺寸范围内。
在 TextEncodeQwenImageEditPlus (#111) 中编写您的指令,如有必要,将移除或约束放在配对的 TextEncodeQwenImageEditPlus (#110) 中。明确引用来源,例如:“图像 1 中的狗戴着图像 2 中的绿帽子和图像 3 中的眼镜。” 如需自定义输出尺寸,您可以用 EmptySD3LatentImage (#112) 替换编码的潜在变量。结果由 VAEDecode (#8) 解码并使用 SaveImage (#60) 保存。
Nunchaku-qwen-image-edit(单图像精炼)#
当您想对单张图像进行有针对性的清理、背景更改或风格调整时选择此项。模型由 NunchakuQwenImageDiTLoader (#120) 加载,由 ModelSamplingAuraFlow (#125) 和 CFGNorm (#123) 调整,并由 KSampler (#127) 采样。用 LoadImage (#129) 导入您的照片;它由 ImageScaleToTotalPixels (#130) 归一化,并由 VAEEncode (#131) 编码。
在 TextEncodeQwenImageEdit (#121) 中提供您的指令,并在 TextEncodeQwenImageEdit (#122) 中提供可选的反向指导,以保留或移除元素。该分支通过 VAEDecode (#124) 解码,并通过 SaveImage (#128) 写入文件。
Nunchaku-qwen-image(文本到图像)#
使用此分支从基础模型创建新图像。NunchakuQwenImageDiTLoader (#146) 提供 ModelSamplingAuraFlow (#138)。在 CLIPTextEncode (#143) 和 CLIPTextEncode (#137) 中输入您的正面和负面提示。使用 EmptySD3LatentImage (#136) 设置您的画布,然后使用 KSampler (#141) 生成,使用 VAEDecode (#142) 解码,并使用 SaveImage (#147) 保存。
Comfyui Nunchaku Qwen 图像工作流程中的关键节点#
NunchakuQwenImageDiTLoader (#115) 加载分支使用的 Qwen 图像权重和变体。选择用于照片引导编辑的编辑模型或用于文本到图像的基础模型。当 VRAM 允许时,更高精度或更高分辨率的变体可以提供更多细节;较轻的变体优先考虑速度。
TextEncodeQwenImageEditPlus (#111) 通过解析您的指令并将其绑定到多达三个参考,驱动多图像编辑。明确指示哪个图像贡献了哪个属性。使用简明的措辞,避免冲突的目标以保持编辑的集中。
TextEncodeQwenImageEditPlus (#110) 作为多图像分支的配对负面或约束编码器。使用它排除您不希望出现的对象、风格或伪影。这通常有助于在移除 UI 覆盖或不需要的道具时保留构图。
TextEncodeQwenImageEdit (#121) 单图像编辑分支的正面指令。用清晰的语言描述所需的结果、表面质量和构图。目标是用一到三句话指定场景和变化。
TextEncodeQwenImageEdit (#122) 单图像编辑分支的负面或约束提示。列出要避免的项目或特征,或描述要从源图像中移除的元素。这对于清除杂乱的文本、徽标或界面元素很有用。
ImageScaleToTotalPixels (#93) 通过缩放到目标总像素数来防止过大的输入导致结果不稳定。使用它在合成前调和不同来源的分辨率。如果您注意到来源之间清晰度不一致,请在此处将它们的有效尺寸调近。
ModelSamplingAuraFlow (#66) 应用为 Qwen 图像模型调整的 DiT/流匹配采样计划。如果输出看起来暗淡、模糊或缺乏结构,请增加计划的偏移以稳定全局色调;如果它们看起来平淡,请减少偏移以追求额外的细节。
KSampler (#3) 主采样器,您可以在其中平衡速度、保真度和随机多样性。调整步骤和指导尺度以在一致性与创意之间取得平衡,选择采样方法,并在您希望跨运行精确重现时锁定种子。
CFGNorm (#75) 标准化无分类器引导,以减少在较高引导尺度下的过饱和或对比度爆炸。按提供的路径保留它;它有助于在您迭代提示时保持稳定的颜色和曝光。
可选附加功能#
- 为获得最佳多图像效果,选择具有相似透视和照明的来源;Nunchaku Qwen 图像编辑模型然后专注于内容而不是修复几何。
- 按顺序引用来源(“图像 1”、“图像 2”、“图像 3”),并明确指出哪些属性转移到哪里。
- 当输出偏暗或模糊时,上调
ModelSamplingAuraFlow的偏移;当您需要额外纹理时,尝试稍低的偏移。 - 要设置特定分辨率,请在您使用的分支中用
EmptySD3LatentImage替换编码的潜在变量。 - 在您投入详细风格化之前,使用负面提示移除 UI 文本、水印或不需要的对象;这使得 Nunchaku Qwen 图像编辑从一开始就保持清洁。
致谢#
此工作流程实施并基于以下作品和资源构建。我们衷心感谢 Nunchaku 为 Qwen-Image 工作流程(ComfyUI-nunchaku)所做的贡献和维护。有关权威详情,请参阅以下链接的原始文档和库。
资源#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- Docs / Release Notes: Nunchaku Qwen Image Source
注意:所引用的模型、数据集和代码的使用受其作者和维护者提供的各自许可证和条款的约束。




