
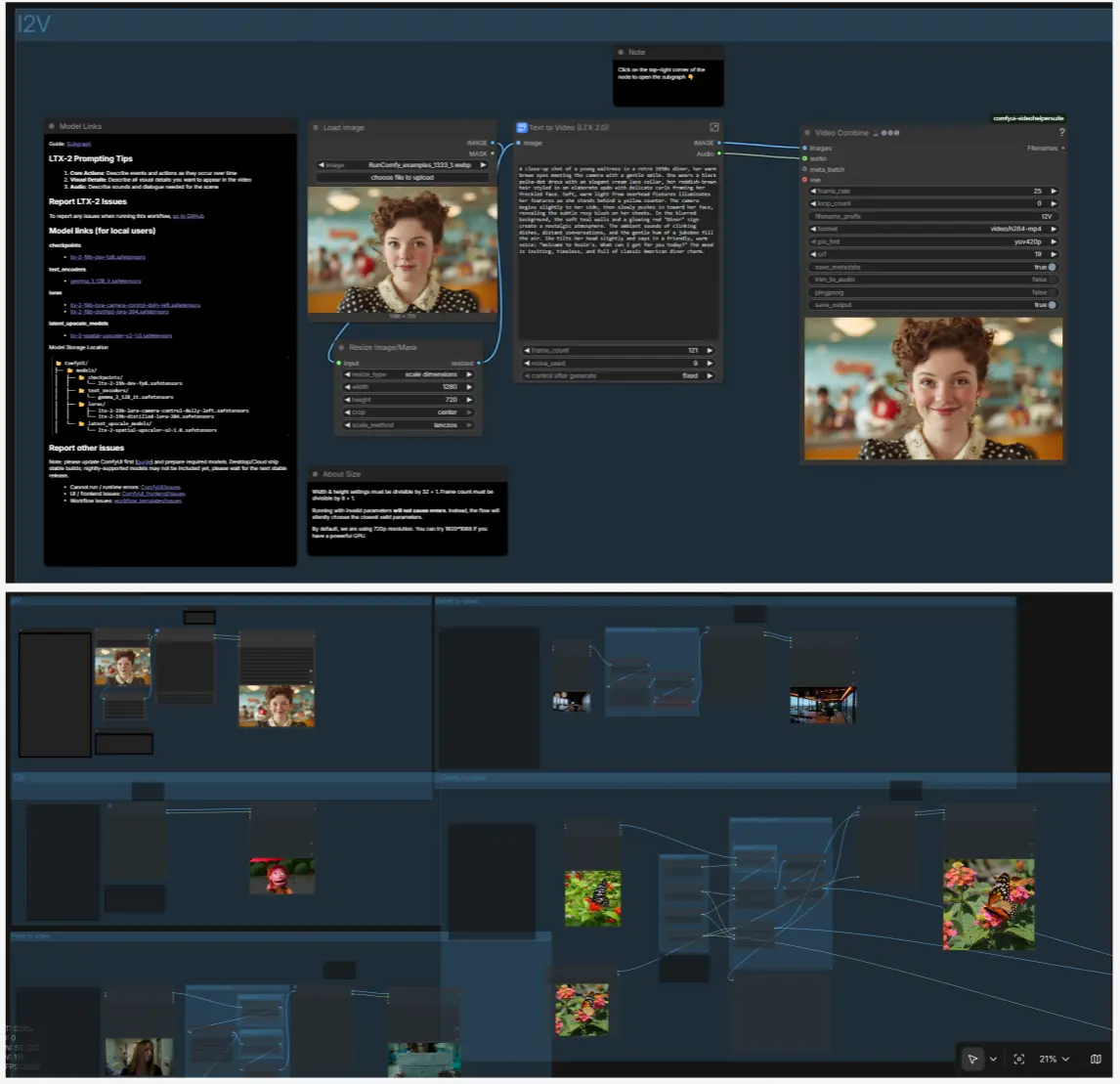
LTX-2 ComfyUI:实时文本、图像、深度和姿态到视频,带同步音频#
这个一体化的 LTX-2 ComfyUI 工作流让您可以在几秒钟内生成并迭代带有音频的短视频。它配备了文本到视频 (T2V)、图像到视频 (I2V)、深度到视频、姿态到视频和 canny 到视频的路径,因此您可以从提示、静止图像或结构化指导开始,并保持相同的创作循环。
基于 LTX-2 的低延迟 AV 管道和多 GPU 序列并行性,图形强调快速反馈。描述运动、相机、外观和声音一次,然后调整宽度、高度、帧数或控制 LoRAs 以优化结果,无需重新连接任何东西。
注意:关于 LTX-2 工作流兼容性的说明 — LTX-2 包含 5 个工作流:文本到视频 和 图像到视频 可在所有机器类型上运行,而 深度到视频、Canny 到视频 和 姿态到视频 需要 2X-Large 机器或更大;在较小的机器上运行这些 ControlNet 工作流可能会导致错误。
LTX-2 ComfyUI 工作流中的关键模型#
- LTX-2 19B (dev FP8) 检查点。核心视听生成模型,从多模态条件生成视频帧和同步音频。 Lightricks/LTX-2
- LTX-2 19B Distilled 检查点。更轻、更快的变体,适用于快速草稿或 canny 控制的运行。 Lightricks/LTX-2
- Gemma 3 12B IT 文本编码器。工作流的提示编码器使用的主要文本理解骨干。 Comfy-Org/ltx-2 split files
- LTX-2 空间放大器 x2。潜在的放大器,在图形中间加倍空间细节,以获得更清晰的输出。 Lightricks/LTX-2
- LTX-2 音频 VAE。对音频潜变量进行编码和解码,以便可以生成和与视频一起混合声音。包含在上面的 LTX-2 版本中。
- Lotus Depth D v1‑1。用于在深度引导的视频生成之前从图像推导出稳健深度图的深度 UNet。 Comfy‑Org/lotus
- SD VAE (MSE, EMA pruned)。用于深度预处理分支的 VAE。 stabilityai/sd-vae-ft-mse-original
- LTX‑2 的控制 LoRAs。可选的即插即用 LoRAs 以引导运动和结构:
如何使用 LTX-2 ComfyUI 工作流#
图形包含五个可以独立运行的路径。所有路径共享相同的导出路径并使用相同的提示到条件逻辑,因此一旦您学习了一个,其他的就会感觉熟悉。
T2V:从提示生成视频和音频#
T2V 路径从 CLIP Text Encode (Prompt) (#3) 开始,并在 CLIP Text Encode (Prompt) (#4) 中有一个可选的负向。LTXVConditioning (#22) 将您的文本和选定的帧率绑定到模型。EmptyLTXVLatentVideo (#43) 和 LTX LTXV Empty Latent Audio (#26) 创建视频和音频潜变量,通过 LTX LTXV Concat AV Latent (#28) 融合在一起。去噪循环通过 LTXVScheduler (#9) 和 SamplerCustomAdvanced (#41) 运行,然后 VAE Decode (#12) 和 LTX LTXV Audio VAE Decode (#14) 产生帧和音频。Video Combine 🎥🅥🅗🅢 (#15) 保存一个带同步声音的 H.264 MP4。
I2V:动画化静止图像#
使用 LoadImage (#98) 加载静止图像,并使用 ResizeImageMaskNode (#99) 调整大小。在 T2V 子图中,LTX LTXV Img To Video Inplace 将第一帧注入潜在序列中,因此运动从您的静止图像而不是纯噪声中构建。保持您的文本提示专注于运动、相机和环境;内容来自图像。
深度到视频:从深度图生成的结构感知运动#
使用“图像到深度图 (Lotus)”预处理器将输入转换为深度图像,由 VAEDecode 解码,并可选地反转以获得正确的极性。“深度到视频 (LTX 2.0)”路径然后通过 LTX LTXV Add Guide 提供深度指导,以便模型在动画化时遵循全局场景结构。该路径重用相同的调度器、采样器和放大器阶段,并以平铺解码为图像和混合音频导出结束。
姿态到视频:从人体姿态驱动运动#
使用 VHS_LoadVideo (#198) 导入片段;DWPreprocessor (#158) 在帧之间可靠地估计人体姿态。“姿态到视频 (LTX 2.0)”子图将您的提示、姿态条件和可选的姿态控制 LoRA 结合在一起,以保持四肢、方向和节拍的一致性,同时允许风格和背景从文本中流出。将此用于舞蹈、简单特技或对镜头谈话的镜头,其中身体时间很重要。
Canny 到视频:边缘忠实动画和蒸馏速度模式#
将帧输入到 Canny (#169) 以获得稳定的边缘图。“Canny 到视频 (LTX 2.0)”分支接受边缘和可选的 Canny 控制 LoRA,以高保真度保持轮廓,而“Canny 到视频 (LTX 2.0 Distilled)”提供更快的蒸馏检查点以快速迭代。两个变体都允许您可选地注入第一帧并选择图像强度,然后通过 CreateVideo 或 VHS_VideoCombine 导出。
视频设置和导出#
通过 Width (#175) 和 height (#173) 设置宽度和高度,通过 Frame Count (#176) 设置总帧数,如果您想锁定初始参考,请切换 Enable First Frame (#177)。在每个路径的末尾使用 VHS_VideoCombine 节点来控制 crf、frame_rate、pix_fmt 和元数据保存。对于蒸馏 canny 路径,提供了一个专用的 SaveVideo (#180),当您更喜欢直接视频输出时。
性能和多 GPU#
图形应用了 LTXVSequenceParallelMultiGPUPatcher (#44),启用 torch_compile 以跨 GPU 分割序列以降低延迟。KSamplerSelect (#8) 让您可以在包括 Euler 和梯度估计样式的采样器之间进行选择;较小的帧数和较低的步骤减少了周转时间,因此您可以快速迭代,并在满意时进行扩展。
LTX-2 ComfyUI 工作流中的关键节点#
LTX Multimodal Guider(#17)。协调文本条件如何引导视频和音频分支。调整cfg和modality在链接的LTX Guider Parameters(#18 对于视频,#19 对于音频) 中,以平衡忠实与创造力;提高cfg以更紧密地遵循提示,增加modality_scale以强调特定分支。LTXVScheduler(#9)。构建一个适合 LTX-2 潜在空间的 sigma 调度。使用steps在速度和质量之间进行权衡;在原型设计时,较少的步骤可以减少延迟,然后在最终渲染时增加步骤。SamplerCustomAdvanced(#41)。将RandomNoise、从KSamplerSelect(#8) 选择的采样器、调度器的 sigmas 和 AV 潜变量绑在一起的去噪器。切换采样器以获得不同的运动纹理和收敛行为。LTX LTXV Img To Video Inplace(见 I2V 分支,例如 #107)。将图像注入视频潜变量中,因此第一帧锚定内容,而模型合成运动。调整strength以决定第一帧的保留程度。LTX LTXV Add Guide(在引导路径中,例如深度/姿态/canny)。直接在潜在空间中添加结构指南(图像、姿态或边缘)。使用strength平衡指南的保真度与生成的自由度,并仅在您需要时间锚定时启用第一帧。Video Combine 🎥🅥🅗🅢(#15 及其同类)。将解码的帧和生成的音频打包成 MP4。对于预览,提高crf(更多压缩);对于最终版本,降低crf并确认frame_rate与您在条件中设置的匹配。LTXVSequenceParallelMultiGPUPatcher(#44)。启用带有编译优化的序列并行推理。保持开启以获得最佳吞吐量;仅在调试设备放置时禁用。
可选额外功能#
- LTX-2 ComfyUI 的提示技巧
- 描述随时间变化的核心动作,而不仅仅是静态外观。
- 指定您必须在视频中看到的重要视觉细节。
- 撰写音轨:环境声、音效、音乐和任何对话。
- 尺寸规则和帧率
- 使用宽度和高度为 32 的倍数(例如 1280×720)。
- 使用帧数为 8 的倍数(此模板中的 121 是一个不错的长度)。
- 保持帧率一致;图形包含浮点和整型框,它们应匹配。
- LoRA 指导
- 相机、深度、姿态和 canny LoRAs 已集成;开始时相机移动的强度为 1,然后仅在需要时添加第二个 LoRA。在 Lightricks/LTX‑2 浏览官方收藏。
- 更快的迭代
- 降低帧数,减少
LTXVScheduler中的步骤,并尝试 canny 路径的蒸馏检查点。当运动有效时,增加分辨率和步骤以获得最终结果。
- 降低帧数,减少
- 可重复性
- 锁定
noise_seed在随机噪声节点中,以便在调整提示、尺寸和 LoRAs 时获得可重复的结果。
- 锁定
致谢#
此工作流实现并建立在以下工作和资源之上。我们对 Lightricks 的 LTX-2 多模态视频生成模型和 LTX-Video 研究代码库,以及 Comfy Org 的 ComfyUI LTX-2 合作节点/集成的贡献和维护表示感谢。有关权威细节,请参阅下面链接的原始文档和存储库。
资源#
- Comfy Org/LTX-2 现在在 ComfyUI 中可用!
- GitHub: Lightricks/LTX-Video
- Hugging Face: Lightricks/LTX-Video-ICLoRA-detailer-13b-0.9.8
- arXiv: 2501.00103
- 文档/发布说明: LTX-2 现在在 ComfyUI 中可用!
注意:使用参考的模型、数据集和代码须遵循其作者和维护者提供的相关许可证和条款。