
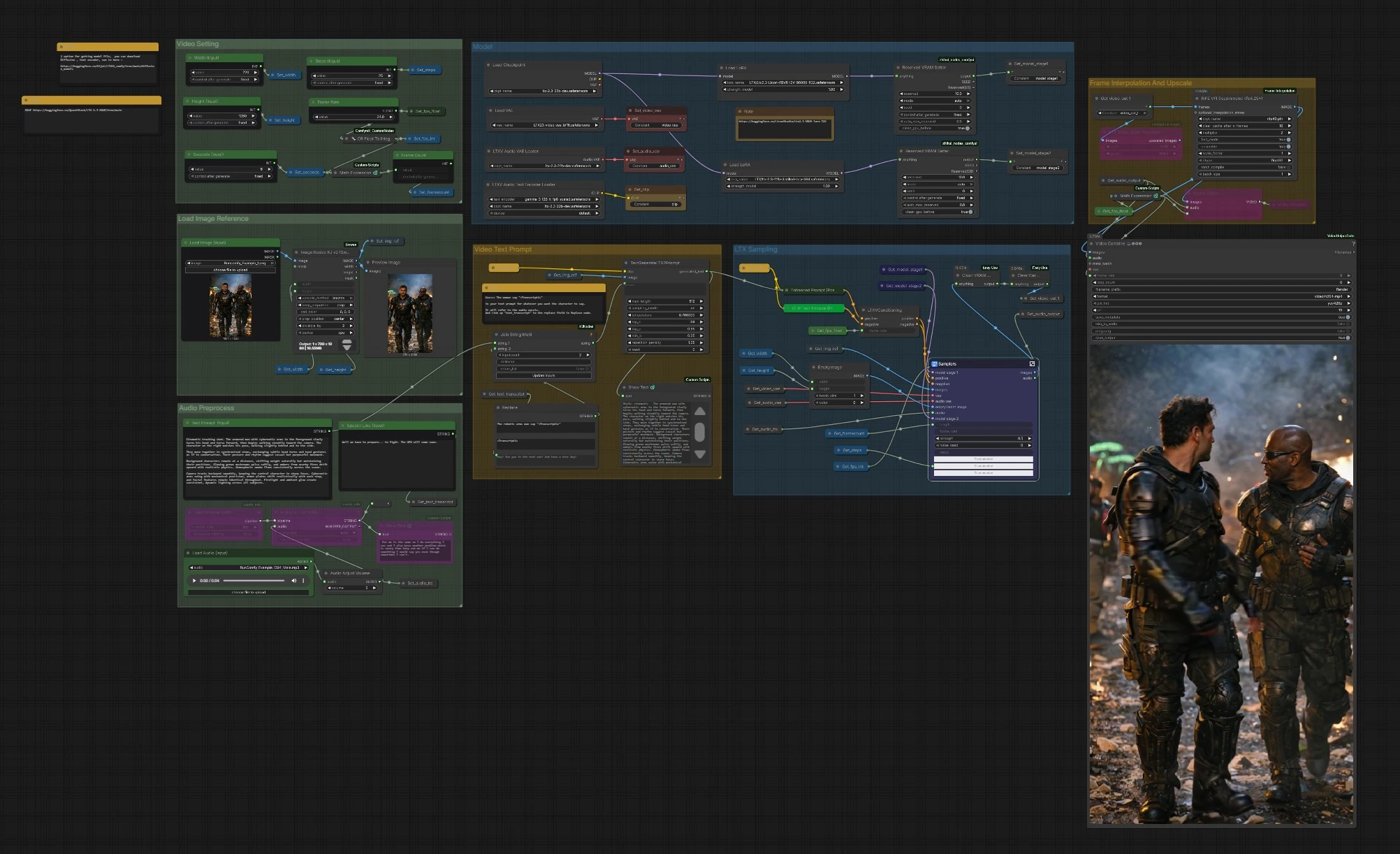
LTX 2.3 VBVR ComfyUI 工作流:具备推理的图像到视频转换与对话#
此工作流将单个参考图像转换为由文本和可选语音指导的连贯视频序列,由 LTX-2.3 和 LTX 2.3 VBVR LoRA 提供支持。VBVR 代表基于视频的视觉推理:它帮助模型在帧间保持身份、空间关系和因果关系的一致性,因此您的场景感觉是故意而非随机的。图表包括语音感知提示、两阶段 LTX 采样、运动平滑和最终的 MP4 放大/导出。
需要叙述连续性、可信运动或对话时序的创作者将发现 LTX 2.3 VBVR 工作流特别有用。提供强大的参考帧,描述动作和交互,并可选地插入自动转录和编织到提示中的语音,以获得更好的唇部和时间对齐。
Comfyui LTX 2.3 VBVR 工作流中的关键模型#
- Lightricks 的 LTX-2.3 22B 视频生成模型,是图像到视频和音频条件解码的主要扩散骨干。 Hugging Face: Lightricks/LTX-2.3
- LTX-2.3 视频 VAE 用于编码/解码视频潜在空间,与基础检查点配对以进行高效的平铺解码。 Hugging Face: Lightricks/LTX-2.3
- LTX-2.3 空间放大器 x2 潜在模型,用于在第一次通过后增强空间细节。 Hugging Face: Lightricks/LTX-2.3
- Gemma 3 12B 文本编码器,打包用于 LTX-2,用于解析复杂指令和对话标记。 Hugging Face: Comfy-Org/ltx-2
- LTX 2.3 VBVR LoRA 用于以推理为中心的场景结构、对象交互和时间上的连续性。 Hugging Face: LiconStudio/Ltx2.3-VBVR-lora-I2V
- RIFE 帧插值模型,用于平滑生成帧之间的运动。 GitHub: hzwer/Practical-RIFE
- Whisper 语音识别模型,用于可选的音频到文本提示注入。 GitHub: openai/whisper
如何使用 Comfyui LTX 2.3 VBVR 工作流#
图表分为清晰的组。您配置输入、模型堆栈和视频设置,然后 LTX 采样器生成帧,这些帧可以选择性地插值和放大,然后导出。
加载图像参考#
使用 Load Image (Input) (#5525) 选择一个强大、风格一致的参考帧。图像通过 ImageResizeKJv2 (#5280) 调整为您选择的宽度和高度,同时保留构图。预览节点确认模型实际看到的内容。具有清晰主题和照明的良好参考图像为 LTX 2.3 VBVR 堆栈提供了可靠的身份和风格锚点。
视频设置#
设置 Width (Input) (#5284)、Height (Input) (#5286)、Seconds (Input) (#5573) 和基础 Frame Rate (#5289)。图表自动计算帧数,因此当您更改持续时间或 fps 时,时序保持一致。如果您计划稍后启用插值,可以选择适度的基础 fps 来节省时间,并让 RIFE 增加平滑度。这些设置还为条件节点提供信息,以便运动和节奏保持一致。
模型#
CheckpointLoaderSimple (#5493) 加载 LTX-2.3。图表通过 LoraLoaderModelOnly (#5616) 附加 LTX 2.3 VBVR LoRA,并可以选择性地应用蒸馏 LoRA 和细节 LoRA 以获得额外的保真度。LTXAVTextEncoderLoader (#5494) 引入基于 Gemma 的文本编码器,而 VAELoader (#5629) 和 LTXVAudioVAELoader (#5492) 提供视频和音频 VAE。两个 ReservedVRAMSetter 节点平衡内存使用,以便长时间运行保持稳定。
视频文本提示#
在 Text Prompt (Input) (#5620) 中编写您的场景。要注入与音频对齐的对话,包含一个占位符,如:The woman says "<Transcript1>"。将实际台词输入 Speech Line (Input) (#5524) 或让 Whisper 从音频中生成;StringReplace (#5226) 和 JoinStringMulti (#5602) 将 <Transcript1> 替换为转录。然后 TextGenerateLTX2Prompt (#5488) 组成精炼的指令,Enhanced Prompt (Positive) (#5174) 在 LTXVConditioning (#5173) 准备最终指导之前对其进行编码。清晰的动词、主题参考和空间提示为 LTX 2.3 VBVR LoRA 提供了它随时间推理所需的上下文。
音频预处理#
使用 Load Audio (Input) (#5590) 带入语音轨或连接 TTS。AudioAdjustVolume (#5601) 规范化音量水平。如果您想要提示感知对话,请通过 Load Whisper (mtb) (#5606) 和 Audio To Text (mtb) (#5607) 使用 Whisper 生成提示中使用的转录。相同的音频也被编码为潜在的,然后再次合并到最终视频中,以便唇部和时间提示可以影响生成。
LTX 采样#
LTXVPreprocess (#5240) 和 LTXVImgToVideoInplace (#5245) 将您的参考帧转换为初始潜在序列,保留核心身份同时允许运动。Samplers 子图 (#5278) 运行一个两阶段过程,带有 CFG 指导器和调度器,生成尊重您的提示和 LTX 2.3 VBVR 推理 LoRA 的时空潜在空间。音频潜在空间与视频潜在空间连接,以便语音时序可以为运动提供信息。LTXVSpatioTemporalTiledVAEDecode (#5237) 解码帧,LTXVAudioVAEDecode (#5103) 恢复音轨。
帧插值和放大#
RIFE VFI (#5554) 插值帧以创建更平滑的运动,并结合基础 fps 达到目标播放速率。RTXVideoSuperResolution (#5631) 增强细节并减少压缩伪影,提高人脸、边缘和小道具的可读性。使用此阶段在速度和质量之间取得平衡:插值以获得平滑度,然后放大以获得清晰度。
导出#
选择 CreateVideo (#5599) 进行简单的多路复用或 VHS_VideoCombine (#5618) 以更好地控制格式、元数据和修剪。通过 SaveVideo (#5597) 管道写入 H.264 MP4。帧速率源自您的设置和插值阶段,因此播放与您最初设计的运动意图相匹配。
Comfyui LTX 2.3 VBVR 工作流中的关键节点#
LoraLoaderModelOnly (#5616)#
加载 LTX 2.3 VBVR LoRA,改善逻辑连续性、对象交互和相机感知运动。调整 LoRA 权重以在推理影响与基础模型和其他 LoRA 的风格之间取得平衡。此节点是定义 LTX 2.3 VBVR 工作流的独特外观和连贯性的核心。有关 LTX 节点和 LoRA 使用,请参阅 Lightricks/ComfyUI-LTXVideo 和上面的 VBVR LoRA 卡。
TextGenerateLTX2Prompt (#5488)#
通过合并您的基础描述、图像参考和从 <Transcript1> 替换的对话标记,组装最终的正向提示。保持指令简洁、明确,并在关于主题和动作上保持一致,以便模型可以跨时间推理。这是您在采样期间 LTX 2.3 VBVR LoRA 将加强意图的地方。
LTXVConditioning (#5173)#
打包正负条件并转发时间信息,以便运动和节奏与您的 fps 选择对齐。如果您在设置中更改帧速率,请在此更新以保持运动动态一致。强烈的负面条件有助于防止静止帧、水印或不需要的叠加出现在序列中。
Samplers (#5278)#
两阶段采样器块协调噪声、指导和调度,将图像和音频潜在空间转换为连贯的视频。最具影响力的调整是总 steps、初始 I2V 阶段的 image strength 和用于可重现性的 noise_seed。仔细调整这些,以在对参考帧的保真度与愿意遵循新的运动和动作之间进行权衡。
RIFE VFI (#5554)#
插值帧以实现更平滑的运动或在不重新生成序列的情况下达到更高的有效 fps。当基础 fps 低或运动感觉卡顿时增加插值;减少它以保留原始生成节奏。该模型广泛用于高质量的 VFI;请参阅 RIFE 项目在 GitHub 上的介绍。
可选附加项#
- 使用 LTX 2.3 VBVR 的对话技巧:编写一自然句子,带占位符,例如 The woman says "<Transcript1>",然后在 Speech Line 中提供台词或让 Whisper 转录音频,以便提示和唇部对齐。
- 推理提示:指出谁在做什么、在哪里和为什么。使用一致的主题名称和时间提示,例如 then、while 和 as the camera moves,以利用 VBVR 的优势。
- 更快的迭代:以较短的持续时间或较低的基础 fps 开始,确认运动节拍,然后增加插值或秒数以完成。
- 稳定性提示:如果您看到身份漂移,稍微降低图像到视频强度或提高 VBVR LoRA 权重;如果看到过度约束,则反其道而行之。
致谢#
此工作流实现并构建于以下作品和资源之上。我们诚挚感谢 @Benji’s AI Playground 的 2.3 VBVR 工作流源的贡献和维护。有关权威详细信息,请参阅下方链接的原始文档和存储库。
资源#
- LTX/2.3 VBVR 工作流源
注意:使用参考的模型、数据集和代码需遵循其作者和维护者提供的相关许可证和条款。