
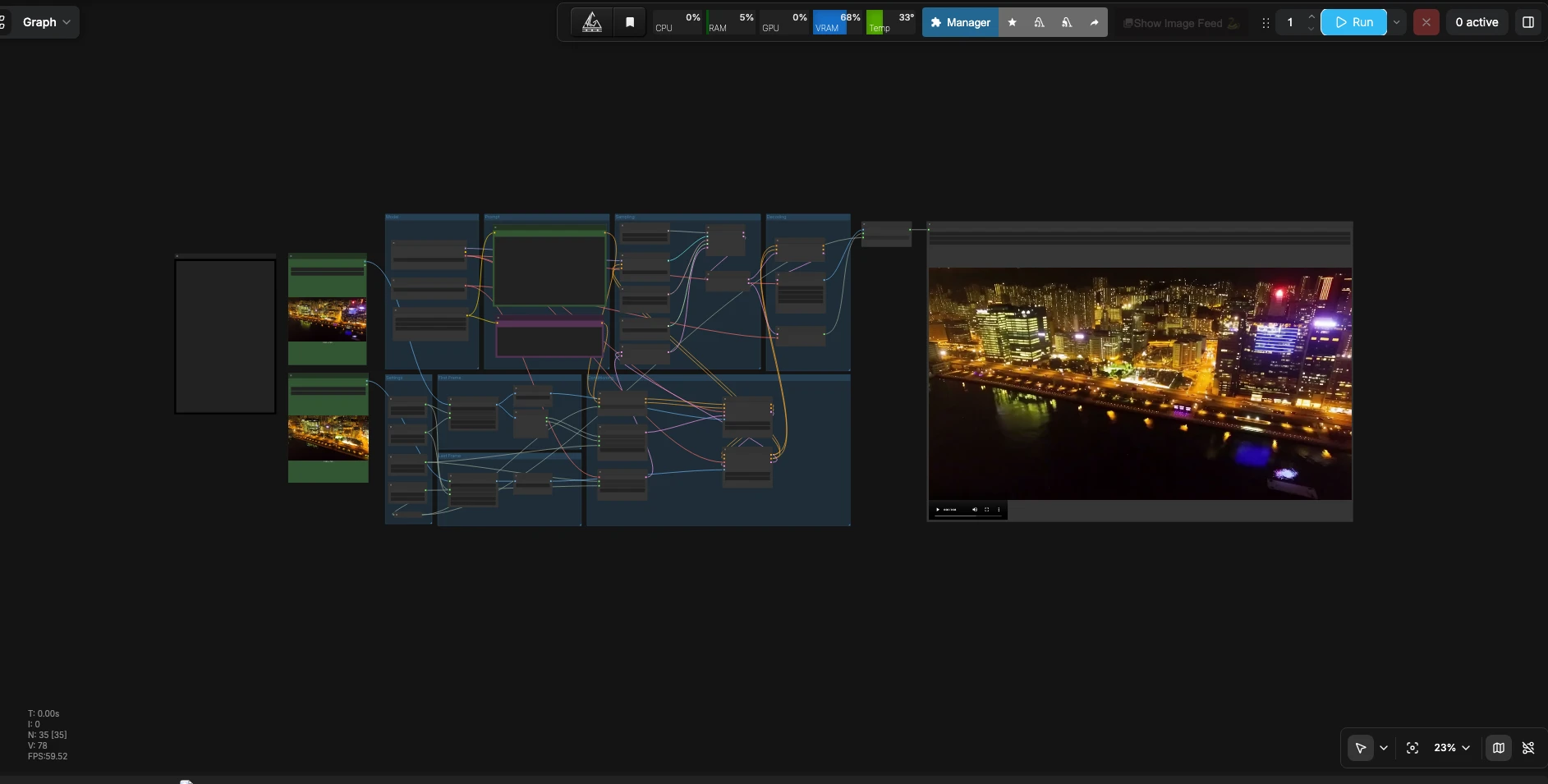
LTX 2.3 首尾帧到视频#
LTX 2.3 首尾帧到视频是一个 ComfyUI 工作流程,将两张静止图像转换为流畅、连续的视频,并同步音频。您提供第一帧、最后一帧以及描述运动、场景细节和声音的自然语言提示。由 LTX-2.3 22B distilled FP8 检查点驱动,管道在图像之间进行插值,同时保持外观和时间的一致性。非常适合需要无缝过渡或直接在 ComfyUI 中创建短循环剪辑的编辑者、运动设计师和故事板艺术家。
此 LTX 2.3 首尾帧工作流程强调高效推理和高提示保真度。FP8 权重控制 VRAM 使用,同时 Gemma 3 12B 文本编码器提高了对视觉和音频指令的语义理解。结果是一个从第一帧到最后一帧的连贯视觉过程,尊重您的提示,并与生成的音频保持同步。
ComfyUI LTX 2.3 首尾帧工作流程中的关键模型#
- LTX-2.3 22B Distilled FP8 检查点由 Lightricks 提供。核心视频生成模型经过蒸馏以实现高效推理,这里用于在两个图像引导和文本提示的条件下合成时间一致的帧。Model card
- Gemma 3 12B IT 文本编码器。提供对提示的视觉和音频方面的强大语言理解,能够准确地实现运动、场景属性和音轨提示。Model card
- LTX-2.3 潜变量 VAEs 用于视频和音频。这些组件在解码过程中将图像和波形音频映射到紧凑的潜变量并返回,保持质量同时使采样效率更高。随 LTX-2.3 FP8 版本一起发布。Model card
如何使用 ComfyUI LTX 2.3 首尾帧工作流程#
此工作流程需要两个参考图像和一个提示,使用首尾帧引导建立条件,采样具有同步音频的视频潜变量,并将所有内容解码为可播放的文件。
设置
- 在设置组中设置您的目标分辨率、帧数和帧率。宽度和高度定义工作画布;输入帧被调整大小以匹配,因此模型可以干净地插值。帧数控制过渡持续时间,帧率设置播放速度。选择与您的来源匹配的长宽比以避免不必要的裁剪。节点
WIDTH(#113)、HEIGHT(#98)、Length(#102) 和Frame Rate(int)(#114) 锚定这些选择。
第一帧
- 在
Load First Frame(#31) 中加载您的起始图像。通过ResizeImageMaskNode(#124) 调整为目标尺寸,并通过LTXVPreprocess(#104) 进行标准化。这为剪辑开头作为强大的结构和色彩引导做好准备。使用清晰、光线充足的图像以获得最佳效果。
最后一帧
- 在
Load Last Frame(#39) 中加载您的结束图像。通过ResizeImageMaskNode(#125) 调整为相同大小,并通过LTXVPreprocess(#99) 进行标准化。这确保了您希望在过渡结束时获得的最终外观和布局。对于循环,确保最后一帧与第一帧视觉兼容。
提示
LTXAVTextEncoderLoader(#103) 提供文本编码器,两个CLIPTextEncode节点捕获您的正面和负面提示。在正面提示 (CLIPTextEncode(#128)) 中,描述相机运动、主体、照明,并包括音频提示,例如“音乐:环境垫子与柔和打击乐”或“对话:轻声耳语”。负面提示 (CLIPTextEncode(#112)) 可以列出您想要抑制的伪影或特征。
条件
LTXVConditioning(#109) 将文本条件与时间信息合并,以便运动和音频与您选择的帧率对齐。EmptyLTXVLatentVideo(#108) 在您的分辨率和长度上创建视频潜变量。两次LTXVAddGuide通过先附加第一帧 (LTXVAddGuide(#115)) 然后是最后一帧 (LTXVAddGuide(#111)),以便模型知道从哪里开始和结束。LTXVEmptyLatentAudio(#101) 初始化匹配持续时间的音频潜变量,LTXVConcatAVLatent(#119) 将音频和视频潜变量捆绑在一起进行采样。
模型
CheckpointLoaderSimple(#127) 加载 LTX-2.3 22B distilled FP8 权重和视频 VAE,而LTXVAudioVAELoader(#126) 提供音频 VAE。这些都已预配置,因此您可以专注于创意输入而不是设置细节。
采样
CFGGuider(#116) 在您的文本和引导帧的遵循程度与创意自由之间进行平衡。RandomNoise(#100) 设置种子以便可重复性。采样器使用SamplerEulerAncestral(#117) 和来自ManualSigmas(#118) 的自定义计划,由SamplerCustomAdvanced(#120) 协调,逐步将潜变量细化为遵循您的运动和音频指令的连贯序列。
解码
- 采样后,
LTXVSeparateAVLatent(#121) 将组合的潜变量分开为视频和音频。LTXVCropGuides(#106) 精细化空间引导以减少边缘伪影,然后进行图像解码。VAEDecodeTiled(#105) 生成帧序列,LTXVAudioVAEDecode(#107) 生成音频波形。CreateVideo(#122) 以您选择的 fps 将帧和声音混合为最终剪辑,SaveVideo(#68) 将最终文件写入您的 ComfyUI 输出。
ComfyUI LTX 2.3 首尾帧工作流程中的关键节点#
EmptyLTXVLatentVideo (#108)
- 定义剪辑的工作分辨率和持续时间。在此调整宽度、高度和长度以设置视觉尺度和过渡时间。较长的持续时间需要提示中更强的运动提示以避免停滞。
LTXVAddGuide (#115)
- 在序列开始时注入第一帧作为结构和颜色锚。如果开头偏离您的来源,增加此引导的影响力;如果感觉过于受限,可稍微减少以允许更多的运动。
LTXVAddGuide (#111)
- 使用最后一帧在剪辑结束时锚定目标外观。如果过渡超出范围或从未完全到达您的最后一帧,提升引导影响力;如果在结束时过于紧绷,则稍微降低。
CFGGuider (#116)
- 控制模型遵循文本和图像条件的强度。较高的引导强调您的提示和引导,但可能降低平滑度;较低的值感觉更自由,但可能偏离预期外观。以小步骤调整并在比较时重复使用相同的种子。
SamplerCustomAdvanced (#120) 与 SamplerEulerAncestral (#117) 和 ManualSigmas (#118)
- 使用一致的计划驱动去噪以实现稳定运动。较短的计划渲染速度更快但可能粗糙;较长或较温和的计划在额外的计算成本下提高一致性。在 A/B 测试其他参数时保持计划一致。
CreateVideo (#122)
- 将解码的帧和音频混合为最终剪辑,使用您选择的帧率。使用与您条件化的相同 fps,以便唇形、脚步声或音乐脉搏保持对齐。
可选附加功能#
- 使用动词和时间编写提示:“相机向前移动”,“灯光在我们接近时变暗”,“音乐:稀疏钢琴与柔和混响”。清晰的动词帮助 LTX 2.3 首尾帧管道推断运动和节奏。
- 匹配您两个图像的长宽比和方向。大的不匹配可能会引入不必要的裁剪或拉伸。
- 对于无缝循环,使最后一帧与第一帧几乎匹配,并保持相机运动循环。
- 在
RandomNoise中重用种子以在迭代提示或引导强度时重复一种外观;更改种子以探索新变化。 - 如果您需要实现细节或自定义节点参考,请参阅 ComfyUI 的 LTX 集成和实用工具,如 ComfyUI-LTXTricks。Repository
致谢#
此工作流程实施并构建于以下作品和资源之上。我们感谢 Lightricks 提供的 LTX-2.3 22B Distilled FP8 Checkpoint、Google 提供的 Gemma 3 12B IT FP4 Text Encoder、logtd 提供的 ComfyUI-LTXTricks Custom Nodes 和 Comfy.org 提供的 Comfy.org Official Workflow 的贡献和维护。有关权威详细信息,请参阅下面链接的原始文档和存储库。
资源#
- Lightricks/LTX-2.3 22B Distilled FP8 Checkpoint
- Hugging Face: Lightricks/LTX-2.3-fp8
- Google/Gemma 3 12B IT FP4 Text Encoder
- Hugging Face: google/gemma-3-12b-it
- logtd/ComfyUI-LTXTricks Custom Nodes
- GitHub: logtd/ComfyUI-LTXTricks
- Comfy.org/Comfy.org Official Workflow
- Docs / Release Notes: comfy.org/workflows/video_ltx2_3_flf2v
注意:使用引用的模型、数据集和代码须遵循其作者和维护者提供的各自许可和条款。
