
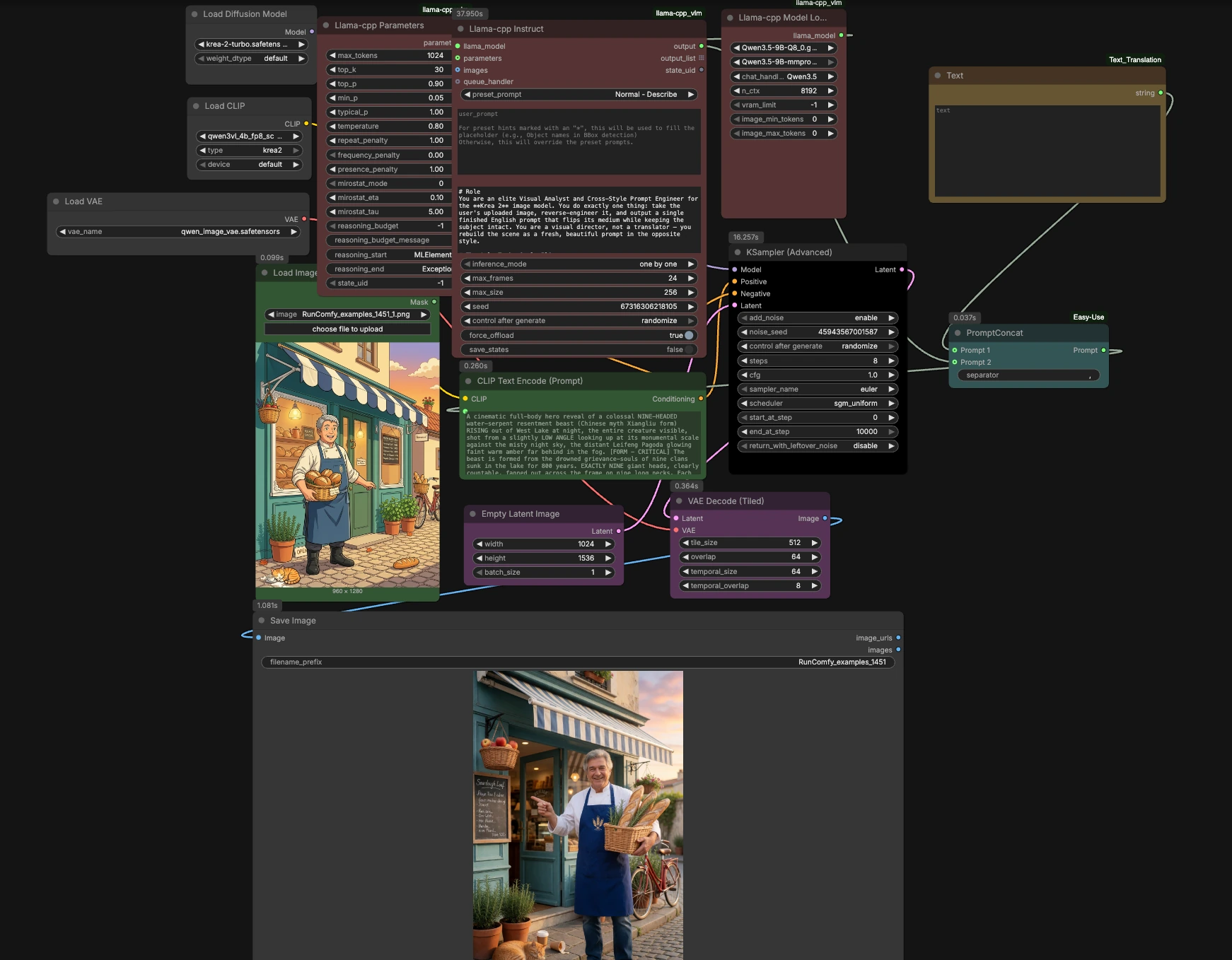






Krea 2 Turbo 图像到图像 ComfyUI 工作流#
这个工作流是一个风格翻转和重绘系统,可以将任何上传的图像转换为其相反的视觉媒介,同时保留主体、颜色、姿势、构图和场景逻辑。风格化来源(动漫、插画、3D、绘画)被重新构想为可信的照片;真实照片被重新解释为清晰的 2D 动漫。基于 Krea 2 Turbo,配有本地 llama.cpp 视觉提示步骤、Qwen3‑VL 文本编码和 Qwen Image VAE,为创作者在 RunComfy 内提供快速、忠实和可重复的视觉精炼和风格转换结果。如果您需要一个可重复使用、生产就绪的 Krea 2 Turbo 图像到图像 ComfyUI 工作流进行快速迭代,这就是它。
Comfyui Krea 2 Turbo 图像到图像 ComfyUI 工作流中的关键模型#
- Krea 2 Turbo huggingface.co/krea/Krea-2-Turbo。这是一个开放权重的文本到图像扩散变压器,经过优化以进行少步、快速推理。Turbo 为速度和一致的提示跟随进行了蒸馏,同时保持高视觉质量和风格控制。
- Qwen3‑VL 4B 文本编码器 (Krea 2 版) huggingface.co/Comfy-Org/Krea-2。提供用于条件 Krea 2 的语言到视觉嵌入;此版本包括 Krea 准备好的 Qwen3‑VL 编码器权重。
- Qwen Image VAE huggingface.co/Comfy-Org/Krea-2。Krea 2 用于在潜在空间和像素之间移动的自动编码器,具有高保真度和大分辨率。
- Qwen 3.5 9B 视觉语言模型 (GGUF) 通过 llama.cpp github.com/mickeylan/ComfyUI-llama-cpp_vlm 和 github.com/ggml-org/llama.cpp。在本地运行以分析上传的图像并创作一个单一抛光的提示,翻转媒介同时锁定具体的视觉事实。
如何使用 Comfyui Krea 2 Turbo 图像到图像 ComfyUI 工作流#
工作流使用本地 VLM 分析您的图像,生成一个干净的相反媒介提示,为 Krea 2 编码,然后使用 Krea 2 Turbo 重绘。管道从输入到输出组织为五个阶段,并有一些可选的控制触摸。
1) 上传和分析图像#
首先将图像拖入 LoadImage (#128)。图片被输入到 llama_cpp_model_loader (#127) 和 llama_cpp_instruct_adv (#125),它们通过 llama.cpp 运行本地 Qwen 系列视觉语言模型。一个精心制作的 system_prompt 指导 VLM 保留主体身份、精确颜色、构图和相机逻辑,同时翻转媒介:风格化来源变为照片;真实照片变为生动的 2D 动漫。输出是一个为 Krea 2 准备的自然语言提示。
2) 组装生成提示#
使用 Text (#130) 添加您想要预置或附加的任何短指导,例如项目标签、品牌术语或镜头备注。easy promptConcat (#129) 将您的手动文本与 VLM 创作的描述合并为一个连贯的提示。尽量保持添加内容最少;VLM 已经准确描述了所有可见元素,因此 Krea 2 Turbo 图像到图像 ComfyUI 工作流可以保持忠实。
3) 为 Krea 2 编码文本#
CLIPLoader (#106) 加载捆绑的 Qwen3‑VL 4B 文本编码器用于 Krea 2,CLIPTextEncode (#5) 将最终提示转化为条件。此编码器设计为与 Krea 2 的分词器配对,并保留详细的场景语义、颜色声明和相机提示。ConditioningZeroOut (#124) 提供一个故意为空的负分支,这通常适合 Krea 2 Turbo 的蒸馏指导行为。
4) 使用 Krea 2 Turbo 生成#
UNETLoader (#107) 加载 Krea 2 Turbo 检查点并传递给 KSamplerAdvanced (#12)。EmptyLatentImage (#10) 设置画布大小;选择您想要生成的宽度和高度。Krea 2 Turbo 针对少步采样构建,具有非常低或零的分类器自由指导,因此从接近零的 CFG 开始,只有在需要更严格的提示遵循时才提高。采样器和调度器协同工作,以快速、清晰的结果尊重提示的锁定颜色和构图。
5) 解码并保存输出#
VAELoader (#105) 提供 Qwen Image VAE,由 VAEDecodeTiled (#123) 用于从潜在变量中重建像素,适用于大图像的 VRAM 友好平铺。SaveImage (#35) 写入最终渲染。结果是相反媒介中的干净、忠实重绘,准备进行审查或另一次快速处理。
Comfyui Krea 2 Turbo 图像到图像 ComfyUI 工作流中的关键节点#
llama_cpp_instruct_adv (#125)#
此节点是风格翻转的大脑。仅在您想更改翻转策略或保留规则时调整 system_prompt;默认设置调整为保持身份、姿势、构图和精确颜色。使用 preset_prompt 和 custom_prompt 进行小调整,例如为照片输出命名镜头或为动漫添加温和的调色板说明。将输出保持为一个流畅的段落;Krea 2 最好响应自然语言。
KSamplerAdvanced (#12)#
控制速度、清晰度和遵循度。Krea 2 Turbo 针对少步采样进行了蒸馏,具有低或零 cfg(请参阅模型卡和代码中的官方指导),因此从最小指导开始,仅在需要更紧的提示遵循时向上调整。如果您偏爱在清晰边缘和超平滑渐变之间的不同权衡,请切换 sampler_name 和 scheduler。锁定 noise_seed 以获得一致的变化。
EmptyLatentImage (#10)#
设置输出大小和批次。使用此选项选择与您预期的构图匹配的宽高比和分辨率;VLM 提示携带构图,因此避免事后裁剪更改。较大的框架受益于平铺解码阶段以保持内存效率。
ConditioningZeroOut (#124)#
设计上禁用负提示,这通常适合 Krea 2 Turbo。如果您的项目需要传统的负提示,请用第二个 CLIPTextEncode 替换此项,输入负输入到 KSamplerAdvanced (#12)。
VAEDecodeTiled (#123)#
执行平铺解码以在更高分辨率下保持 VRAM 使用稳定。如果在极端大小下看到接缝,轻轻增加重叠;如果内存紧张,增加平铺颗粒度。
可选额外功能#
- 对于风格化控制,您可以从 Comfy‑Org repack 加载 Krea‑2 LoRAs(文件中列出了链接),并在 ComfyUI 中应用它们,如任何其他 LoRA huggingface.co/Comfy-Org/Krea-2。Krea 建议在 Raw 上训练 LoRAs 并在 Turbo 上应用;详情请参阅官方仓库 github.com/krea-ai/krea-2。
- 保持手动编辑简短。Krea 2 Turbo 图像到图像 ComfyUI 工作流旨在保留精确的色调和场景逻辑;长手动提示可能会无意中覆盖 VLM 的颜色锁定。
- 为最快的迭代,在中等分辨率下工作,检查构图,然后在满意翻转后放大或提高分辨率以获得最终效果。
致谢#
此工作流实施并构建在以下作品和资源之上。我们感谢 RunningHub 提供的 图像到图像工作流来源,Krea AI 提供的 Krea 2 和 Krea-2-Turbo,以及 Comfy-Org 和 mickeylan 提供的 ComfyUI Krea 2 权重和 ComfyUI llama-cpp VLM 自定义节点 的贡献和维护。有关权威详细信息,请参阅以下链接的原始文档和存储库。
资源#
- RunningHub/Image-to-Image Workflow
- 文档 / 发布说明: RunningHub post
- krea-ai/Krea 2
- GitHub: krea-ai/krea-2
- Krea/Krea-2-Turbo
- Hugging Face: krea/Krea-2-Turbo
- Comfy-Org/Krea-2
- Hugging Face: Comfy-Org/Krea-2
- mickeylan/ComfyUI-llama-cpp_vlm
- GitHub: mickeylan/ComfyUI-llama-cpp_vlm
注意:使用参考的模型、数据集和代码须遵循其作者和维护者提供的相应许可证和条款。