
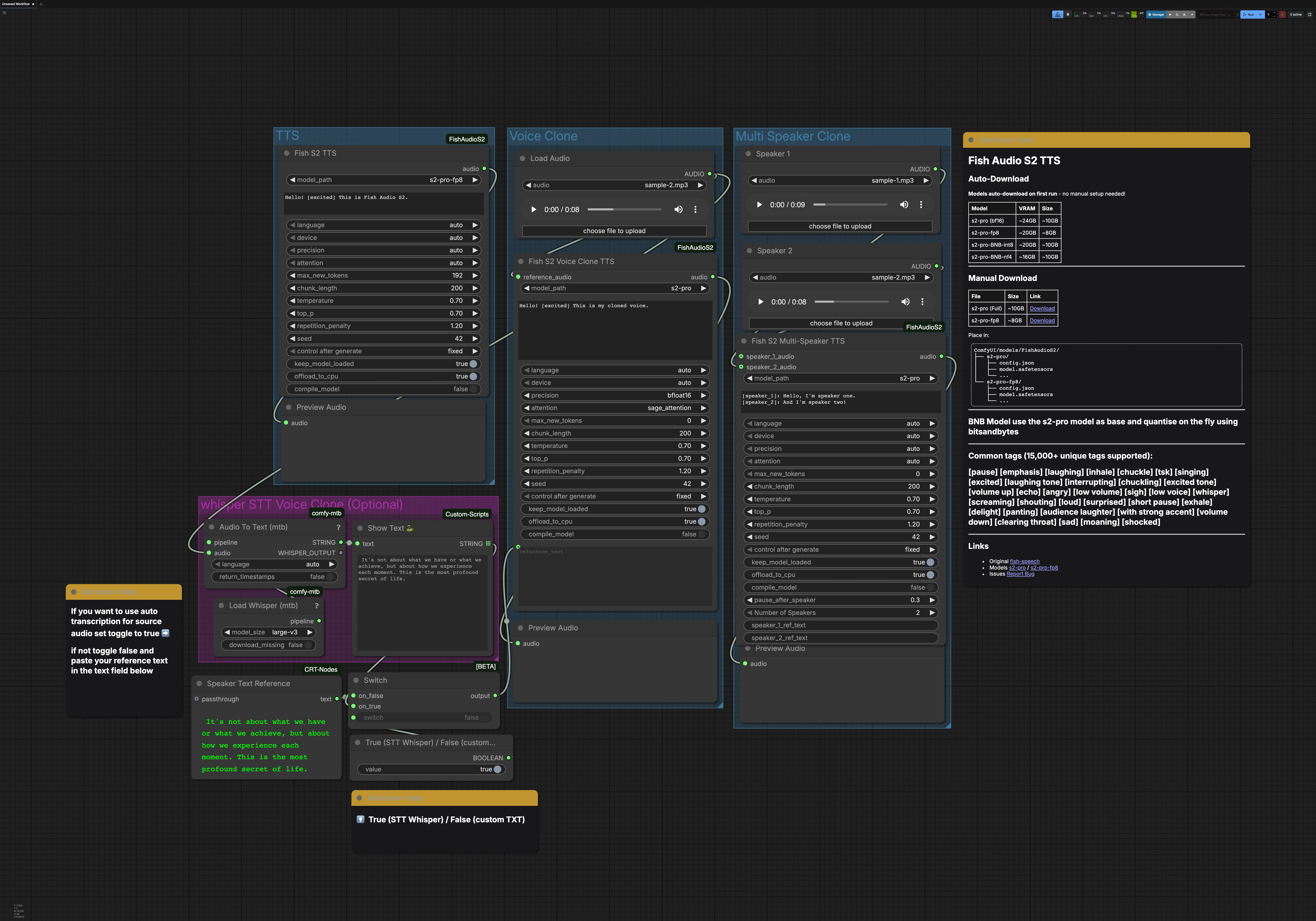
ComfyUI 的 Fish Audio S2 TTS:高质量 TTS、语音克隆和多说话者对话#
Fish Audio S2 TTS 是一个即装即用的 ComfyUI 工作流程,可将文本转换为自然语音,从短参考剪辑中克隆语音,并生成多说话者对话。它由 Fish Audio S2-Pro 系列驱动,并支持通过情感和韵律标签(如 [excited]、[whisper] 和 [laughing])进行丰富的风格控制。
此工作流程非常适合希望在 ComfyUI 内进行灵活、表现力语音合成的创作者、产品团队和开发人员。它包括可选的语音转文本功能,用于快速捕获转录、自动语言检测和多种精度选择,包括 fp8 和 sage_attention,用于高效推断。
注意: 在 2X Large 或更大的机器上运行此工作流程。较小的实例可能会出现内存不足(OOM)。
Comfyui Fish Audio S2 TTS 工作流程中的关键模型#
- Fish Audio S2-Pro —— 用于单个说话者 TTS、语音克隆和多说话者对话的核心生成文本转语音模型。它支持广泛的风格标记和多语言合成 model card,并且是 Fish-Speech 项目的一部分 repo。
- Fish Audio S2-Pro FP8 —— S2-Pro 的内存高效变体,减少了 VRAM 需求,质量损失最小,推荐用于受限 GPU model card。
- OpenAI Whisper large-v3 —— 用于自动转录参考音频的可选语音转文本模型 repo。
如何使用 Comfyui Fish Audio S2 TTS 工作流程#
此工作流程包含三个可以独立运行的主要路径:TTS、语音克隆和多说话者克隆。可选的 Whisper STT 组可以为语音克隆生成转录。每条路径以音频预览结束,以便您快速监控结果。
TTS 组#
FishS2TTS (#42) 节点执行直接文本转语音功能,使用 Fish Audio S2 TTS。在节点的文本框中输入您的脚本,并添加风格标签如 [excited]、[pause] 或 [whisper] 来塑造情感和节奏。语言检测是自动的,因此您可以用目标语言编写,模型会自动调整。选择适合您的 GPU 内存的 S2-Pro 变体,例如 fp8 用于较轻负载。输出会路由到 PreviewAudio 以便即时收听。
语音克隆组#
使用 LoadAudio 提供目标语音的简短、干净的参考剪辑,然后将其路由到 FishS2VoiceCloneTTS (#14)。提供与您想要的说话风格匹配的转录;准确的文本有助于模型保持节奏和口音。您可以从 STT 组驱动参考文本或自己输入,并可以添加风格标签以优化情感和表达。精度和注意力后台选择在长行中平衡速度、内存和稳定性。合成的克隆语音被发送到 PreviewAudio 以便您快速迭代。
多说话者克隆组#
使用 LoadAudio 节点为每个说话者加载一个参考剪辑,然后将它们连接到 FishS2MultiSpeakerTTS (#41)。提供一个对话脚本,用 [speaker_1]、[speaker_2] 等标记每次发言。此模板默认包含两个说话者,节点支持配置时扩展到八个不同的声音。您可以混合叙述散文、标签和对话,以控制每个角色的流程和情感。最终混音会被预览,以便验证时序和清晰度。
Whisper STT 语音克隆(可选)#
Load Whisper (mtb) (#6) 使用 large-v3 驱动 Audio To Text (mtb) (#7) 自动转录参考剪辑。识别的文本由 ShowText|pysssss (#8) 显示。一个小的切换开关由 ComfySwitchNode (#34) 和一个布尔控制构建,让您可以选择 STT 输出(true)或您自己输入的 Text Box line spot (#31) 文本(false)。这在您想要快速基础转录或精心制作克隆提示时很有用。
Comfyui Fish Audio S2 TTS 工作流程中的关键节点#
FishS2TTS (#42)#
通过可选风格标签和自动语言检测从文本生成单个说话者语音。调整模型变体以匹配您的硬件,例如在 VRAM 紧张时选择 fp8。使用种子控制进行可重复的录制,并在探索替代传递时引入小变化。对于长脚本,选择优化稳定性的注意力后台。
FishS2VoiceCloneTTS (#14)#
通过对 reference_audio 和 reference_text 进行条件化来创建克隆语音。干净且音调一致的语音和与预期节奏相符的转录会产生更好的结果。可以在最终文本中混合风格标签以引导情绪而不损害身份。精度和注意力设置有助于在长行中平衡质量和内存。
FishS2MultiSpeakerTTS (#41)#
通过将每个说话者的参考音频与标记有 [speaker_n] 标签的对话配对来合成多说话者对话。根据需要增加说话者数量,并分配不同的剪辑以增强分离。保持每个说话者的参考音调一致,以避免混合。使用种子在渲染多次场景时进行确定性混合。
可选附加功能#
- 明智地使用风格标签。以 [excited]、[whisper]、[emphasis]、[pause] 等少量标签开始,只有在需要时才增加以确保清晰度。
- 对于语音克隆,修剪参考的开头和结尾的静音,并避免背景噪音以保留音色。
- 如果 GPU 内存有限,优先选择 S2-Pro fp8 或运行时量化选项。为了最大限度的保真度,使用更高的精度。
- 标点符号很重要。逗号和句号改善了措辞,放置在从句边界的标签往往听起来更自然。
- 对于多说话者脚本,每行保持一个话语,并始终以正确的 [speaker_n] 标签前缀以保持分离。
资源:
- Fish Audio S2-Pro 模型卡: Hugging Face
- S2-Pro fp8 变体: Hugging Face
- Fish-Speech 项目: GitHub
- ComfyUI Fish Audio S2 节点: GitHub
- Whisper large-v3: GitHub
致谢#
此工作流程实现并建立在以下作品和资源之上。我们感谢 Saganaki22 提供的 ComfyUI-FishAudioS2 自定义节点,以及 Fish Audio 提供的 S2-Pro 模型的贡献和维护。有关权威详细信息,请参阅下面链接的原始文档和存储库。
资源#
- Saganaki22/ComfyUI-FishAudioS2 自定义节点
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro 模型
- Hugging Face: fishaudio/s2-pro
注意:使用引用的模型、数据集和代码需遵循其作者和维护者提供的相应许可和条款。
