
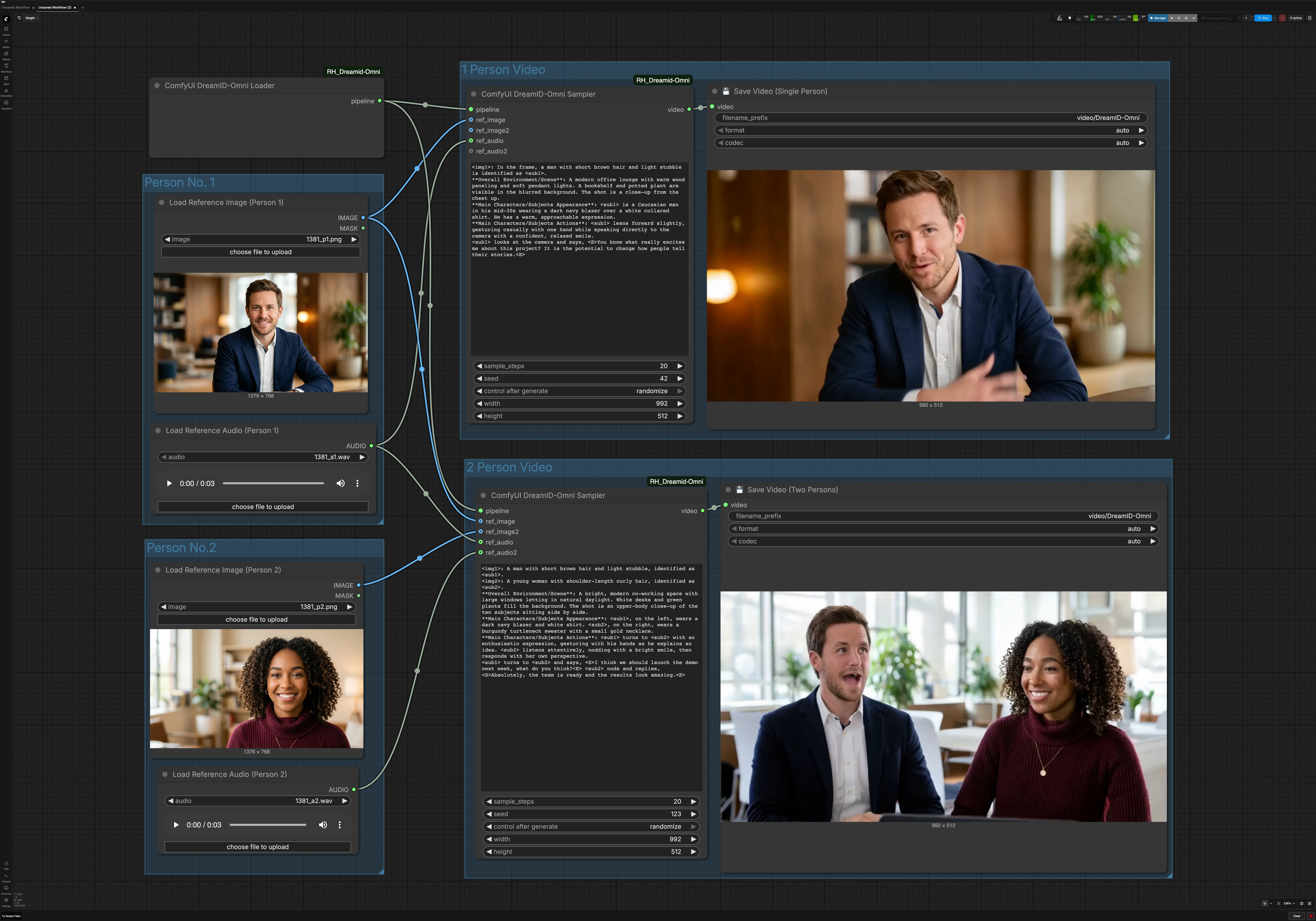
DreamID-Omni 单人和双人角色对话视频工作流程在 ComfyUI 中#
此工作流程将单一参考照片和音频片段转化为保留身份的对话视频。由 DreamID-Omni 模型提供动力,它结合了现代视频骨干与 MMAudio 驱动的唇部运动,使主题自然发声,同时保持您图像中的面孔。它还支持两个角色,能够通过两个声音驱动的并排对话片段。
为创作者、产品团队和研究人员设计,DreamID-Omni 工作流程在 ComfyUI 中非常适合数字化身、个性化公告、教程介绍和 AI 对话场景。您提供照片和音频,选择性地在简短提示中描述镜头,图形会渲染出一段准备分享的精美视频。
Comfyui DreamID-Omni 工作流程中的关键模型#
- DreamID-Omni。核心身份模块,在响应音频时保持参考图像中的人物在帧间的一致性,确保逼真的唇部动作。详情见官方仓库和权重:DreamID-Omni 和 DreamID-Omni on Hugging Face。
- Wan 2.2 视频生成。高容量视频扩散骨干,在 DreamID-Omni 引导面部身份的同时合成连贯的运动、光照和镜头构图。
- MMAudio。音频表示模型,调整口型和细微面部线索以与提供的语音对齐,提升唇同步的真实性。
如何使用 Comfyui DreamID-Omni 工作流程#
此图形有两条并行路径。单人路径使用一张图像和一个音频。双人路径使用两张图像和两个音频来制作对话片段。共享的 DreamID-Omni 加载器初始化这两者的管道。
角色一#
使用 Load Reference Image (Person 1) (#6) 选择一张光照均匀、正面清晰、遮挡最少的肖像。使用 Load Reference Audio (Person 1) (#7) 提供您希望角色说的话语。更清晰的音频会产生更好的唇同步效果,因此请优先选择没有音乐或强烈背景噪音的语音。这对图像和音频同时用于单人模式和双人模式中的左侧或第一个角色。
角色二#
在创建对话时使用 Load Reference Image (Person 2) (#9) 和 Load Reference Audio (Person 2) (#11)。选择的照片应与角色一的构图相匹配,以保持构图平衡。确保第二个音频的响度与第一个类似,以避免突然的感知变化。如果您仅制作单人剪辑,可以忽略此组。
单人视频#
单人路径由 ComfyUI DreamID-Omni Sampler (#21) 驱动。它将 DreamID-Omni 管道与角色一的照片和音频融合,然后根据节点提示区域中的简短场景描述渲染出一致的镜头。保持您的提示简洁实用,例如描述背景、相机距离和举止。结果由 💾 Save Video (Single Person) (#4) 写入,自动命名并导出文件。
双人视频#
对话路径使用 ComfyUI DreamID-Omni Sampler (#22) 将两个身份合成在一个画面中,并用其配对的音频驱动每张口型。提供简短提示以设置环境和互动风格,例如合作空间、随意语调或谁先发言。这有助于稳定相机位置和手势,同时 DreamID-Omni 和 MMAudio 保持身份和唇部对齐。剪辑由 💾 Save Video (Two Persons) (#5) 导出。
共享的 DreamID-Omni 管道#
ComfyUI DreamID-Omni Loader (#23) 初始化 DreamID-Omni 组件,供两条路径使用。通常不需要在这里调整任何内容。只要权重和 ComfyUI 节点可用,加载器就会准备好管道以便采样器进行渲染。
Comfyui DreamID-Omni 工作流程中的关键节点#
ComfyUI DreamID-Omni Loader (#23)#
初始化 DreamID-Omni 管道并使其权重可用于下游采样器。这里没有典型的用户输入。如果您维护多个模型变体,请在排队渲染前确认安装了正确的权重。
ComfyUI DreamID-Omni Sampler (#21)#
单人渲染。此节点将加载器管道与第一个参考图像和音频相结合,以合成保留身份的对话头。提示字段是您定义场景和举止的地方;种子控制可重复性;分辨率决定构图和面部细节;步骤权衡速度和保真度。为了在多次拍摄中获得一致的结果,请重用相同的种子并保持提示更改最小化。
ComfyUI DreamID-Omni Sampler (#22)#
双人渲染。此实例接受两张照片和两个音频,将每个声音与其主题配对以实现同步唇部动作。提示可以设置对话和相机布局。像单人模式一样调整种子和分辨率,并确保两个音频在渲染前修剪到所需的时间。
💾 Save Video (Single Person) (#4)#
将单人输出写入磁盘。设置文件夹或基本名称以保持版本有序。如果可以,请在不确定时将编解码器和帧率选项保持在自动状态。
💾 Save Video (Two Persons) (#5)#
将对话输出写入磁盘。使用不同的基本名称,以便单人和双人剪辑易于区分。除非有特定的交付要求,否则请保持自动导出设置以确保可靠性。
可选附加功能#
- 在参考图像中保持面部足够大以占据画面的显著部分,以增强身份锁定。
- 使用干净、音量均衡的语音音频。修剪开头的静音以避免初始冻结的嘴唇。
- 为获得更稳定的视觉效果,在迭代提示或服装时重用相同的种子。
- 如果两人间距感觉紧张,请重新措辞提示以扩大相机或增加肩部空间,而不是裁剪面部。
- 有关资产和更新,请参见官方模型和节点:DreamID-Omni、ComfyUI_RH_Dreamid-Omni 和 DreamID-Omni weights。
致谢#
此工作流程实现并构建在以下作品和资源之上。我们衷心感谢 Guoxu1233 提供的 DreamID-Omni 模型/工作流程,HM-RunningHub 提供的 DreamID-Omni ComfyUI 节点,以及 XuGuo699 提供的 DreamID-Omni 模型权重的贡献和维护。有关权威细节,请参阅下列链接的原始文档和仓库。
资源#
- DreamID-Omni 官方仓库 - https://github.com/Guoxu1233/DreamID-Omni
- GitHub: Guoxu1233/DreamID-Omni
- DreamID-Omni ComfyUI 节点 (RunningHub) - https://github.com/HM-RunningHub/ComfyUI_RH_Dreamid-Omni
- DreamID-Omni 模型权重 (Hugging Face) - https://huggingface.co/XuGuo699/DreamID-Omni
- Hugging Face: XuGuo699/DreamID-Omni
注意:引用的模型、数据集和代码的使用受其作者和维护者提供的相应许可和条款的约束。