
ComfyUI MOSS TTS: 文本到语音、语音克隆、音效和对话于一体的工作流#
此 ComfyUI MOSS TTS 工作流使用 OpenMOSS MOSS-TTS 系列将文本转换为生动的 24 kHz 语音。它涵盖快速单一发音合成、从短参考片段的零样本语音克隆、描述性语音设计、程序化音效以及带有可选每个发音参考的多发音对话。
基于官方 MOSS-TTS 节点堆栈和模型系列,它在速度和质量之间取得了平衡。本地 1.7B 路径是单 GPU 上的快速通道,而较大的 Delay 8B 模型则以速度换取更广泛的能力和表现力。如果您需要可重用的提示、克隆的声音或 ComfyUI 中的对话,这个 ComfyUI MOSS TTS 工作流就是为您设计的。
Comfyui ComfyUI MOSS TTS 工作流中的关键模型#
- OpenMOSS MOSS-TTS Local 1.7B。单 GPU 友好的文本到语音转换器,提供用于日常生产工作的快速自然 24 kHz 语音。模型卡:MOSS-TTS-Local-Transformer。
- OpenMOSS MOSS-TTS Delay 8B。一个更大的模型系列,强调质量、发音相似性和韵律,以速度和内存为代价。模型卡:MOSS-TTS。
- MOSS Audio Tokenizer。将波形和离散令牌连接起来的学习编解码器,支持 MOSS-TTS 模型的高保真解码。模型卡:MOSS-Audio-Tokenizer。
有关实施细节和更新,请参阅官方存储库:OpenMOSS/MOSS-TTS 和支持此工作流的节点堆栈 richservo/comfyui-moss-tts。
如何使用 Comfyui ComfyUI MOSS TTS 工作流#
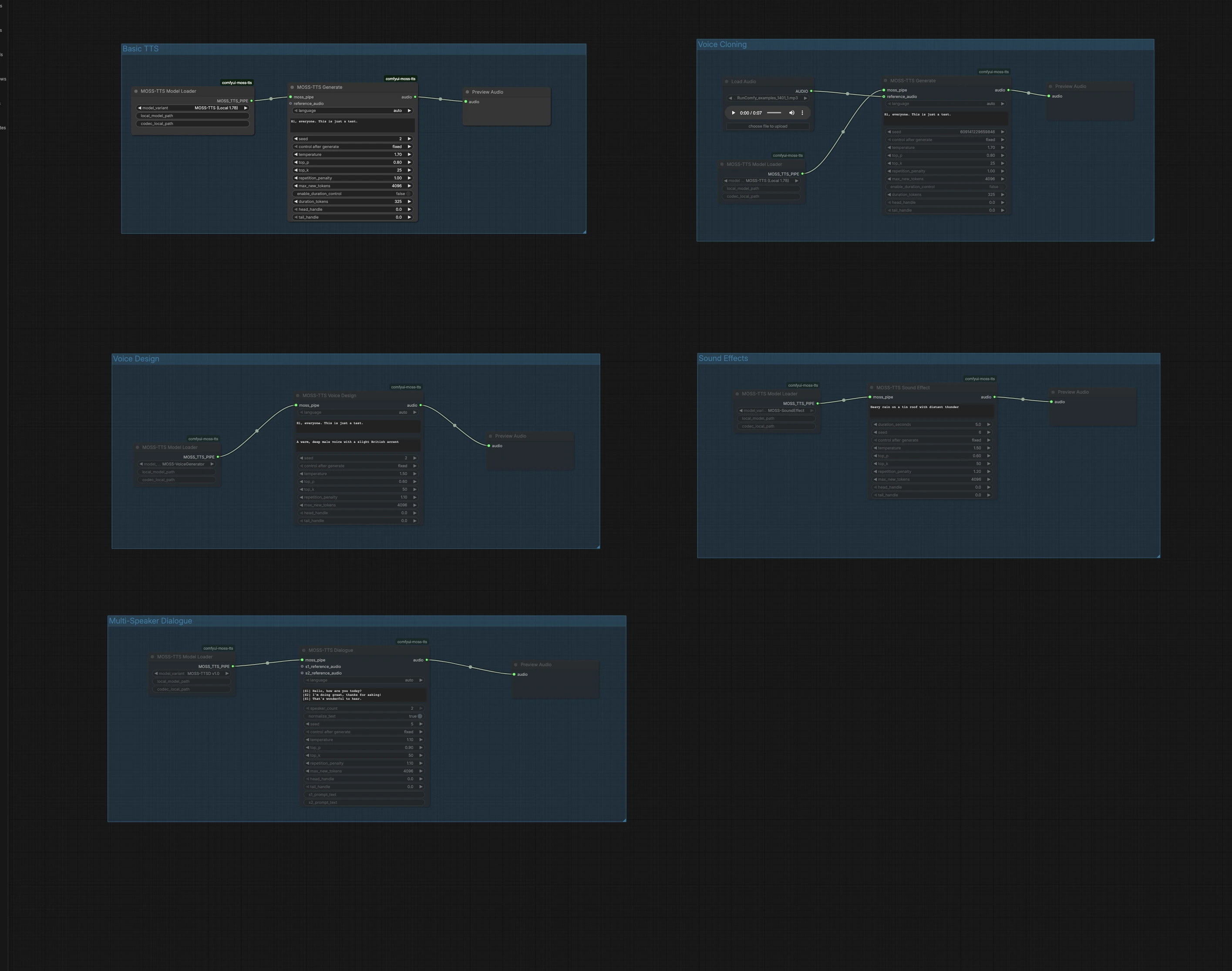
此图分为五个独立的组。选择匹配您目标的组,运行它,然后直接在画布中预览音频。您可以并行运行多个组以试验不同的方法。
基本 TTS#
基本 TTS 组将普通文本转换为语音,使用 Local 1.7B 快速路径。在 MossTTSModelLoader 中加载模型(#1),将您的文本输入到 MossTTSGenerate 中(#2),然后在 PreviewAudio 中收听(#3)。生成器根据您的提示条件来塑造发音和韵律,因此请自然地书写并使用标点符号来控制节奏。当您想要可重复的采样时固定种子,或者在探索不同表达方式时随机化种子。
语音克隆#
语音克隆组从短参考音频片段执行零样本语音克隆。使用 LoadAudio 导入干净的语音样本(#4),将其连接到由 MossTTSModelLoader 驱动的 MossTTSGenerate(#6),并提供目标文本。模型从参考中提取说话者音色和风格,并以该声音呈现您的新脚本。使用中性内容和最少背景噪音的参考来提高相似性,并保持适度的持续时间以实现最快的周转。
语音设计#
语音设计从自然语言描述创建新声音而不是示例片段。MossTTSVoiceDesign(#9)使用文本描述,如“温暖、深沉的男性声音,带有轻微的英国口音”,结合您的脚本,合成 24 kHz 语音。该节点通过 MossTTSModelLoader(#8)加载的专用语音生成器路径提供动力。这是当您想要一致、可重复的角色而不需要真实录音时的理想选择。通过年龄、音色、口音和能量等特征来细化描述以引导声音。
音效#
音效从文本提示生成非语音音频,适用于背景音轨、过渡或环境层。使用 MossTTSSoundEffect(#12)及其模型管道从 MossTTSModelLoader(#11),提示如“重雨打在锡屋顶上伴随远处雷声”产生丰富、可循环的纹理。使用简洁的名词和动作定义场景,然后添加一些形容词来确定强度或距离。在 PreviewAudio(#13)中预览并快速迭代以适应您的混音。
多发音对话#
多发音对话组呈现带有可选每个发音参考片段的脚本对话。使用括号中的发音者标签编写您的脚本,例如 [S1] 你好。 和 [S2] 嗨!,然后将其传递给 MossTTSDialogue(#15)下的模型管道从 MossTTSModelLoader(#14)。您可以为 S1 和 S2 附加参考音频输入以克隆每个角色的特定声音,或将其留空以让模型仅从文本上下文中选择不同的发音者。此路径非常适合呼叫和响应、带有角色线的叙述或语音 UI 模拟。
Comfyui ComfyUI MOSS TTS 工作流中的关键节点#
MossTTSModelLoader (#1)#
加载所选的 OpenMOSS 模型系列并组装内部 TTS 管道。选择本地 1.7B 变体以在单 GPU 上快速迭代,或在您优先考虑表现力和相似性时切换到较大的 Delay 8B 模型。保持每个任务系列一个加载器,以便每个下游分支保持独立。
MossTTSGenerate (#2)#
主要的单发音合成器,消耗您的文本提示和可选的参考音频以生成 24 kHz 语音。提供干净、标点良好的文本以获得更清晰的节奏,并在需要零样本克隆时连接短语音片段。在固定和随机之间切换种子以平衡可重复性和探索性。
MossTTSVoiceDesign (#9)#
从描述性提示生成新的声音以及要说的文本。将描述集中在音色、年龄、口音和能量上,以引导身份,同时保持简洁。当许可或采购真实声音不切实际时,这是一个强有力的选择。
MossTTSSoundEffect (#12)#
从简短的文本描述中合成非语言音频。编写紧凑的提示,锚定来源、动作和空间,然后迭代以匹配场景。非常适合您在同一个 ComfyUI MOSS TTS 图中用于对话的环境和一次性。
MossTTSDialogue (#15)#
解析带括号的发音者标签,并将多轮对话渲染为单个音频输出。使用 [S1]、[S2] 等标记每一行,并可选择连接每个发音者的参考片段以保持身份在轮次之间的一致性。保持台词简洁,以确保发音者之间的交接最可靠。
可选附加功能#
- 使用本地 1.7B 模型快速草稿,然后在需要更强的相似性或更丰富的韵律时切换到 Delay 8B 检查点。
- 对于零样本克隆,使用干净的 5-15 秒语音片段,具有最少的混响和噪音,以改善音色传输。
- 在对话中,保持发音者标签一致,不要包含如
[S1]的标点符号,以避免解析错误。 - 使用 3-6 个特征(如音色、年龄、口音、风格和能量)来制作语音设计提示,以获得可预测的结果。
- 在您的文本中使用标点符号和换行符来控制 ComfyUI MOSS TTS 输出中的停顿和节奏。
- 在任何预览后添加一个
SaveAudio节点,如果您想要批量渲染的自动文件导出。
参考资料: OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
致谢#
此工作流实现并建立在以下作品和资源的基础上。我们感谢 richservo 提供的 ComfyUI MOSS-TTS 自定义节点,OpenMOSS 提供的 MOSS-TTS 仓库,以及 OpenMOSS-Team 提供的 MOSS-TTS 模型(Delay 8B 和 Local 1.7B)和 MOSS Audio Tokenizer 的贡献和维护。有关权威的详细信息,请参阅下面链接的原始文档和存储库。
资源#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
注意: 使用引用的模型、数据集和代码需遵循其作者和维护者提供的相应许可证和条款。
